430 Chapter 1 Introduction
1.1 What Operating Systems Do
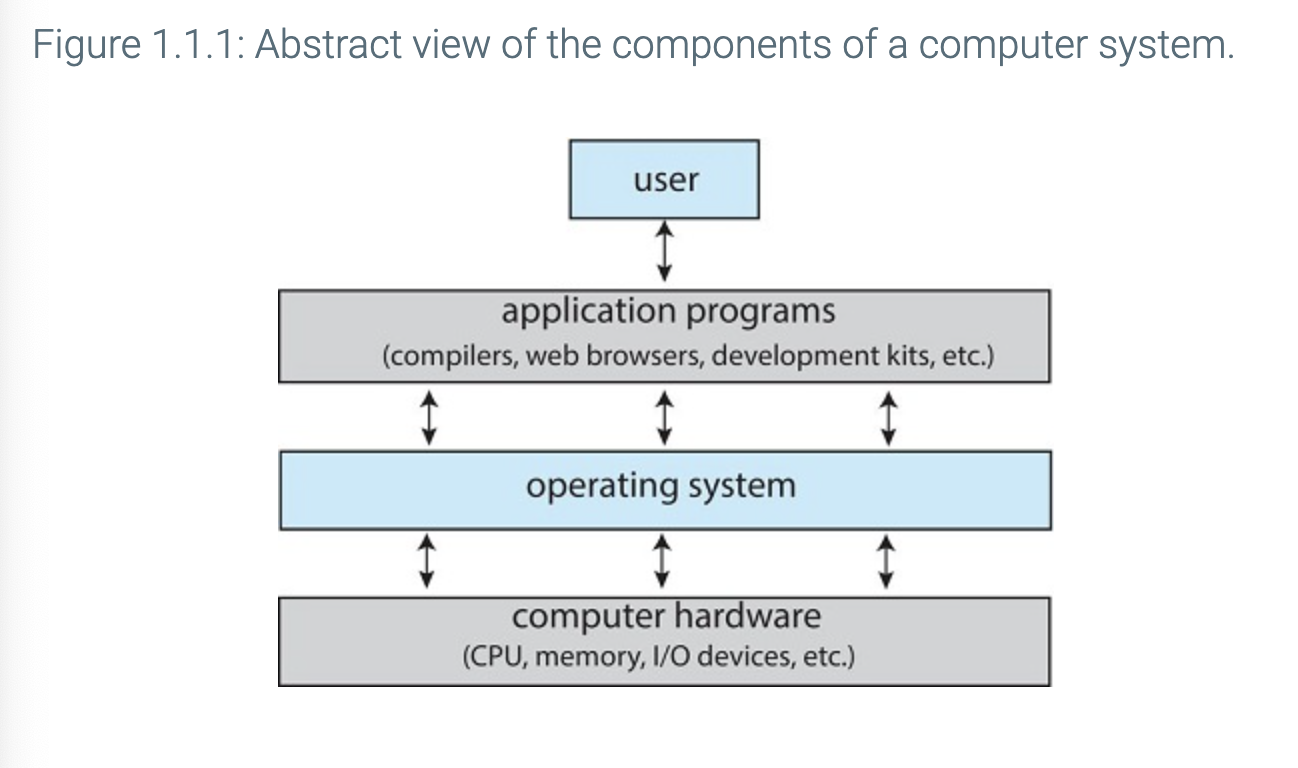
A computer system can be divided into roughly four components
- The Hardware
- The Operating System
- The Application Programs
- The User
Hardware: CPU, Memory, I/O that provides resources for the system
Application Programs: Define the ways in which the resources are used to solve the users computing problem
Operating System: Controls the hardware and coordinates its use among the various application programs for the users
Think of an Operating System like a government, it preforms no useful function by itself
System View
From a computer's point of view, we can view the OS as a resource allocator.
An operating system is a control program, the goal of which is to manage the execution of user programs to prevent errors and improper use of the computer
Defining Operating Systems
A more common definition, and the one that we usually follow, is that the operating system is the one program running at all times on the computer—usually called the kernel. Along with the kernel, there are two other types of programs: system programs, which are associated with the operating system but are not necessarily part of the kernel, and application programs, which include all programs not associated with the operation of the system.
A reasonable summary is that the operating system is inclusive of the kernel that is loaded at boot time, any device drivers and kernel functions loaded at run time, and any system programs related to the operation of the system (as opposed to applications). The operating system is the piece of software that sits between the hardware and applications, providing a set of services to the computer and users, and is not part of the firmware or hardware logic.
Mobile operating systems often include not only a core kernel but also middleware—a set of software frameworks that provide additional services to application developers.
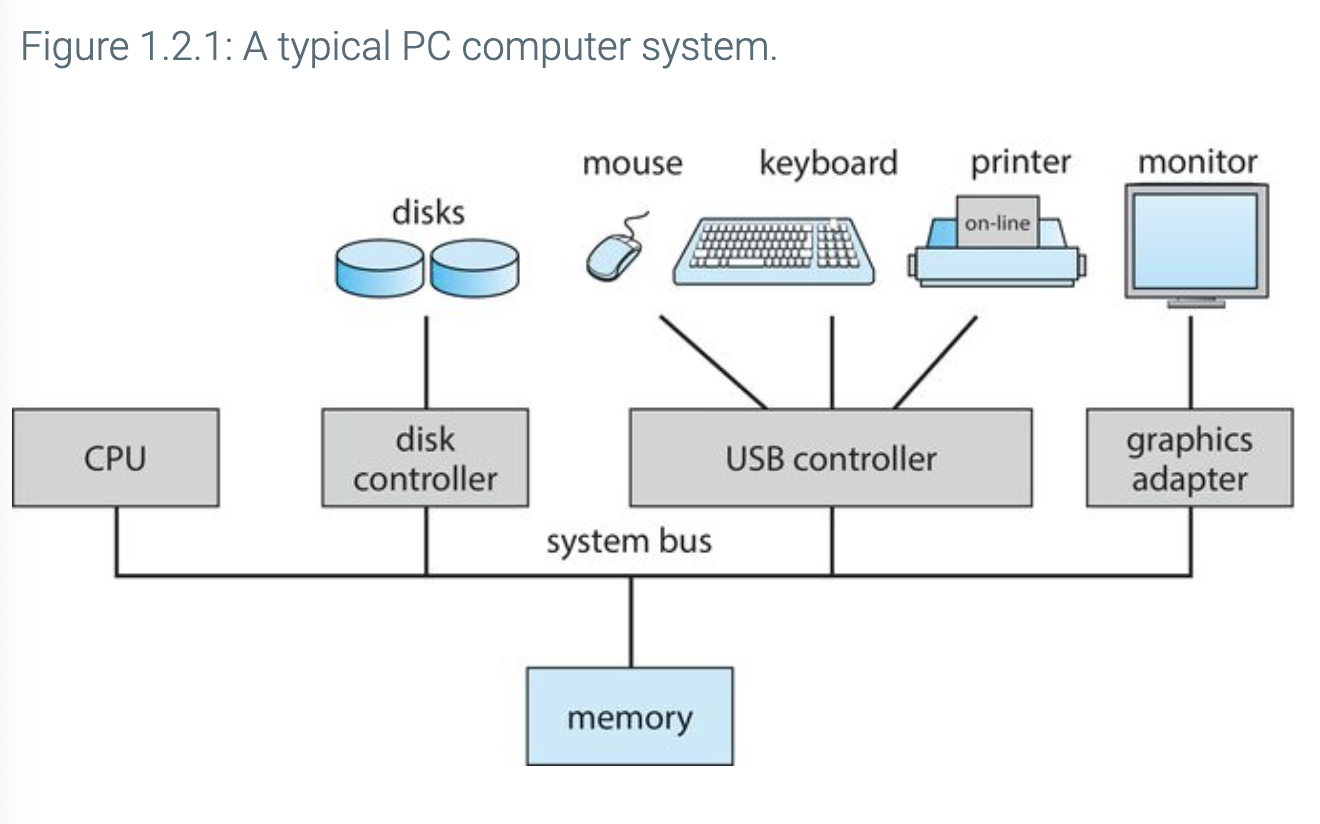
1.2 Computer-System Organization
Interrupts
The interrupt architecture must also save the state information of whatever was interrupted, so that it can restore this information after servicing the interrupt. If the interrupt routine needs to modify the processor state—for instance, by modifying register values—it must explicitly save the current state and then restore that state before returning. After the interrupt is serviced, the saved return address is loaded into the program counter, and the interrupted computation resumes as though the interrupt had not occurred.
Implementation
- The CPU hardware has a wire called the interrupt-request line that the CPU senses after executing every instruction.
- When the CPU detects that a controller has asserted a signal on the interrupt-request line, it reads the interrupt number and jumps to the interrupt-handler routine by using that interrupt number as an index into the interrupt vector.
- It then starts execution at the address associated with that index. The interrupt handler saves any state it will be changing during its operation, determines the cause of the interrupt, performs the necessary processing, performs a state restore, and executes a
return_from_interruptinstruction to return the CPU to the execution state prior to the interrupt.
We say that the device controller raises an interrupt by asserting a signal on the interrupt request line, the CPU catches the interrupt and dispatches it to the interrupt handler, and the handler clears the interrupt by servicing the device. The animation below summarizes the interrupt-driven I/O cycle.
In a modern OS, we need more sophisticated interrupt handling features
- We need the ability to defer interrupt handling during critical processing.
- We need an efficient way to dispatch to the proper interrupt handler for a device.
- We need multilevel interrupts, so that the operating system can distinguish between high- and low-priority interrupts and can respond with the appropriate degree of urgency.
In modern hardware, we handle these with the CPU and interrupt-controller hardware
Intel Processor Event-Vector Table

Storage Structure
Von Neumann Architecture
- First Fetches an instruction from memory and stores it an instruction register
- The instruction is decoded and may cause additional items to be fetched and stored in a register.
- After the instruction has been executed, the result may be stored back in memory
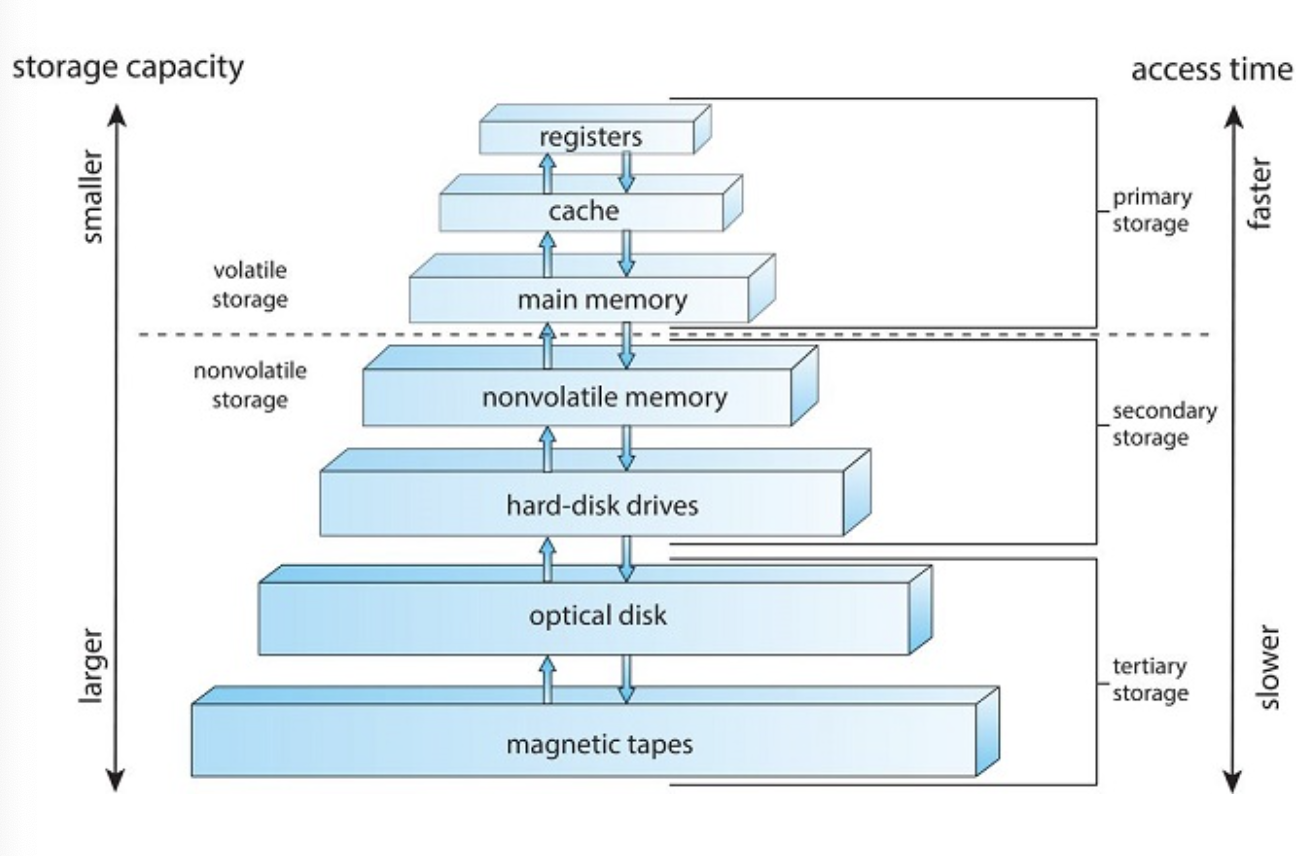
Storage-Device Heirarchy
I/O Structure
1.3 Computer-System Architecture
Single-processor systems
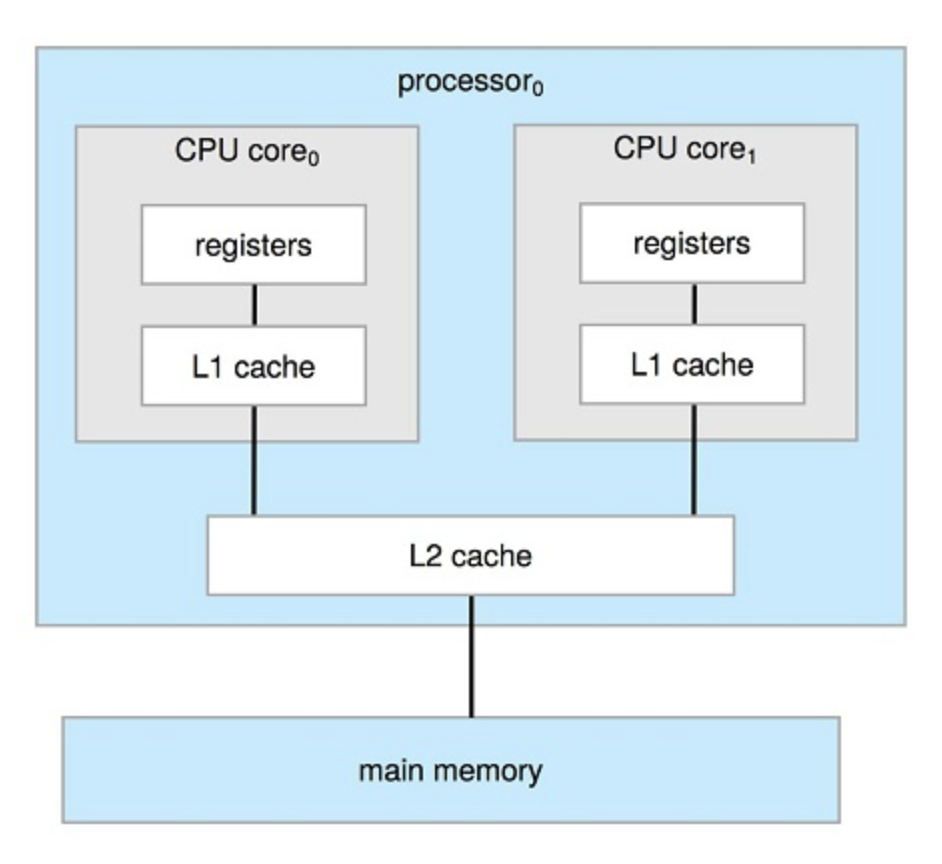
Many years ago, most computer systems used a single processor containing one CPU with a single processing core. The core is the component that executes instructions and registers for storing data locally. The one main CPU with its core is capable of executing a general-purpose instruction set, including instructions from processes. These systems have other special-purpose processors as well. They may come in the form of device-specific processors, such as disk, keyboard, and graphics controllers.
Multiprocessor Systems
On modern computers, from mobile devices to servers, multiprocessor systems now dominate the landscape of computing. Traditionally, such systems have two (or more) processors, each with a single-core CPU. The processors share the computer bus and sometimes the clock, memory, and peripheral devices.
The speed-up ratio with N processors is not N, however; it is less than N. When multiple processors cooperate on a task, a certain amount of overhead is incurred in keeping all the parts working correctly.
The most common multiprocessor systems use symmetric multiprocessing (SMP), in which each peer CPU processor performs all tasks, including operating-system functions and user processes.
Symmetric Multiprocessing Architecture
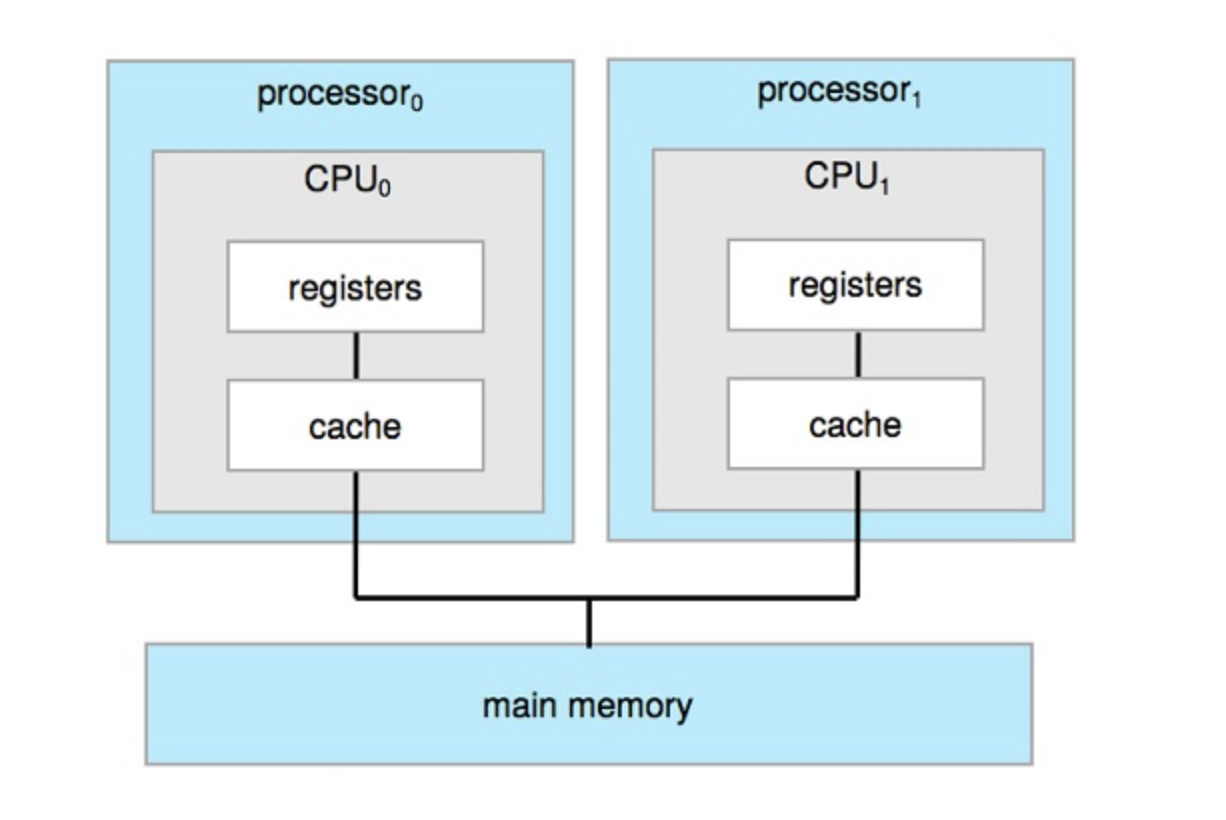
The benefit of this model is that many processes can run simultaneously—N processes can run if there are N CPUs—without causing performance to deteriorate significantly.
a multicore processor with N cores appears to the operating system as N standard CPUs.
Dual Core Design with Two Cores on Same Chip
Clustered Systems
Clustering is usually used to provide high-availability service—that is, service that will continue even if one or more systems in the cluster fail.
1.4 Operating-System Operations
Another form of interrupt is a trap (or an exception), which is a software-generated interrupt caused either by an error (for example, division by zero or invalid memory access) or by a specific request from a user program that an operating-system service be performed by executing a special operation called a system call.
Multiprogramming and Multitasking
The OS keeps several process in memory at the same time. The OS then picks and begins to execute one of these processes. Eventually the process may be blocked, when this happens the OS switches to and executes another process.
Memory Layout for a multiprogramming system
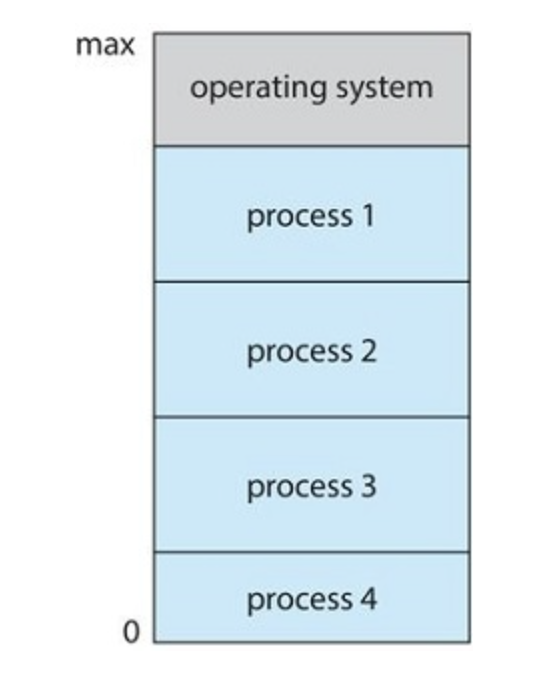
Multi process operations require memory management
A CPU Scheduler chooses which process will run next
Dual-mode and multimode operation
Used to protect the OS and hardware from executing incorrectly
Minimally we need two modes
- User Mode
- Kernel Mode (aka supervisor, system, or privileged)
These are distinguished by the used of a mode bit where 0 = Kernel Mode and 1 = User mode
When the computer system is executing on behalf of a user application, the system is in user mode. However, when a user application requests a service from the operating system (via a system call), the system must transition from user to kernel mode to fulfill the request.
Transition from user to kernel mode
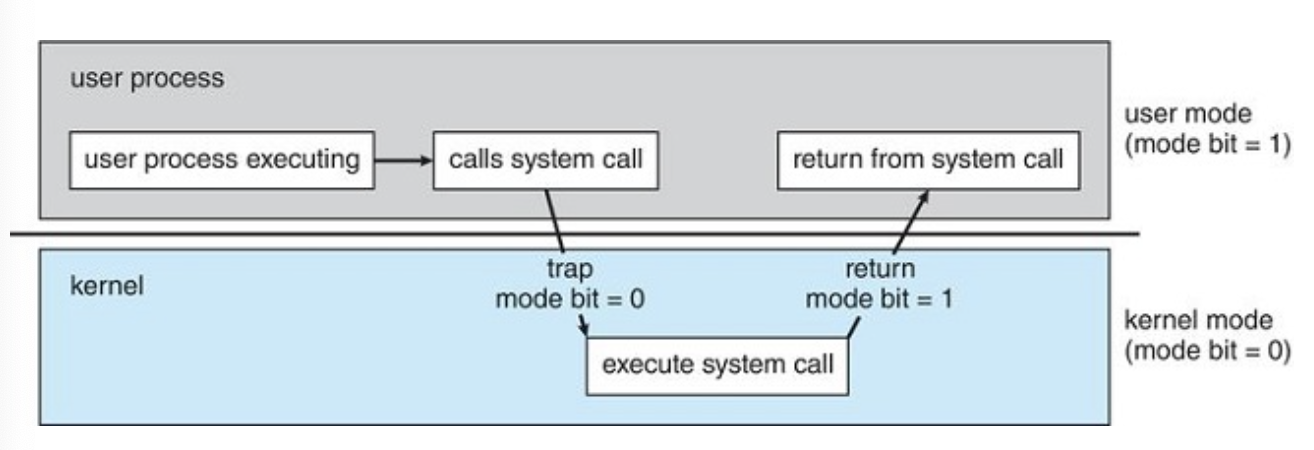
The system will boot in kernel mode, then starts user applications in user mode.
When a system call is executed, it is typically treated by the hardware as a software interrupt. Control passes through the interrupt vector to a service routine in the operating system, and the mode bit is set to kernel mode.
1.5 Resource Management
An OS is effectively a resource manager
Process Management
- Creating and deleting both user and system processes
- Scheduling processes and threads on the CPUs
- Suspending and resuming processes
- Providing mechanisms for process synchronization
- Providing mechanisms for process communication
Memory Management
The operating system is responsible for the following activities in connection with memory management:
- Keeping track of which parts of memory are currently being used and which process is using them
- Allocating and deallocating memory space as needed
- Deciding which processes (or parts of processes) and data to move into and out of memory
File System Management
The operating system is responsible for the following activities in connection with file management:
- Creating and deleting files
- Creating and deleting directories to organize files
- Supporting primitives for manipulating files and directories
- Mapping files onto mass storage
- Backing up files on stable (nonvolatile) storage media
Mass-Storage Management
The operating system is responsible for the following activities in connection with secondary storage management:
- Mounting and unmounting
- Free-space management
- Storage allocation
- Disk scheduling
- Partitioning
- Protection
Cache Management
Characteristics of various types of storage
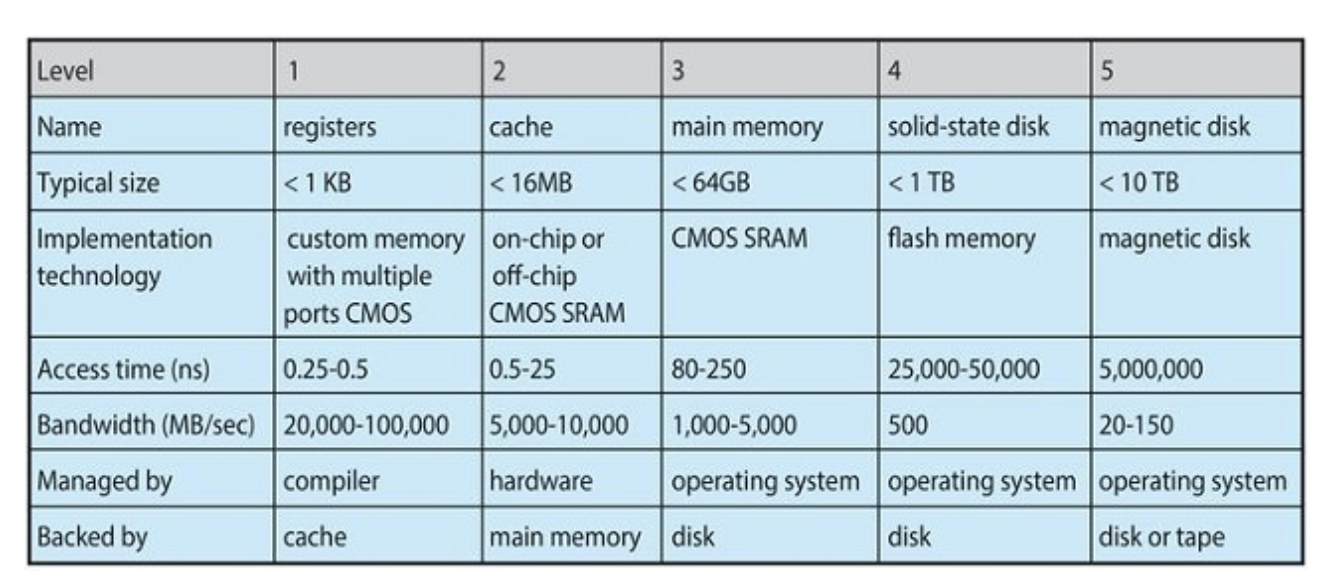
The movement of information between levels of a storage hierarchy may be either explicit or implicit, depending on the hardware design and the controlling operating-system software. For instance, data transfer from cache to CPU and registers is usually a hardware function, with no operating-system intervention. In contrast, transfer of data from disk to memory is usually controlled by the operating system.
example, suppose that an integer A that is to be incremented by 1 is located in file B, and file B resides on hard disk. The increment operation proceeds by first issuing an I/O operation to copy the disk block on which A resides to main memory. This operation is followed by copying A to the cache and to an internal register. Thus, the copy of A appears in several places: on the hard disk, in main memory, in the cache, and in an internal register. Once the increment takes place in the internal register, the value of A differs in the various storage systems. The value of A becomes the same only after the new value of A is written from the internal register back to the hard disk.

I/O system management
The I/O subsystem consists of several components:
- A memory-management component that includes buffering, caching, and spooling
- A general device-driver interface
- Drivers for specific hardware devices
1.6 Security and Protection
If a computer system has multiple users and allows the concurrent execution of multiple processes, then access to data must be regulated.
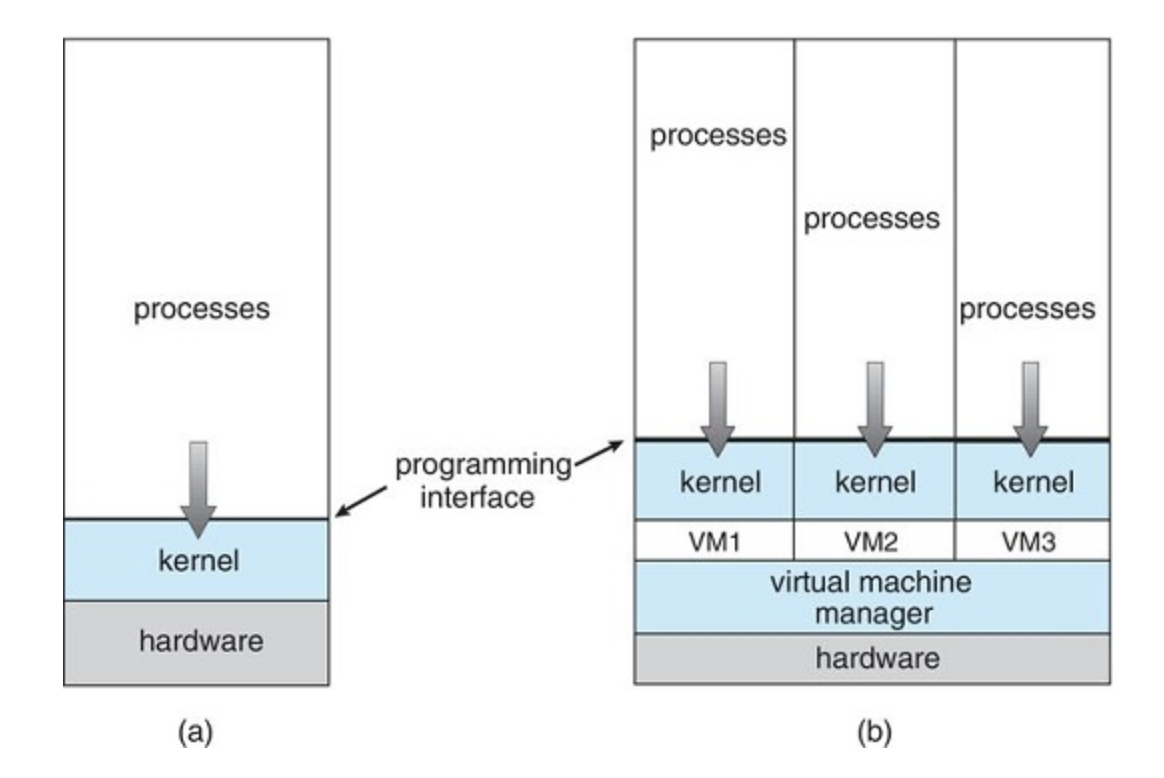
1.7 Virtualization
Virtualization is a technology that allows us to abstract the hardware of a single computer (the CPU, memory, disk drives, network interface cards, and so forth) into several different execution environments, thereby creating the illusion that each separate environment is running on its own private computer.
1.8 Distributed Systems
Some operating systems have taken the concept of networks and distributed systems further than the notion of providing network connectivity. A network operating system is an operating system that provides features such as file sharing across the network, along with a
1.9 Kernel Data Structures
The following are data structures used heavily in operating systems
Lists, Stacks, and Queues
An array is a simple data structure in which each element can be accessed directly. For example, main memory is constructed as an array.
Lists are one of the most fundamental data structures after arrays. The most common type is a Linked List. List are sometimes used directly by Kernel algorithms, usually they are used though to construct stacks and queues
Stack: An OS typically uses a stack when invoking function calls. Parameters, local variables, and the return address are pushed onto the stack when a function is called; returning from the function call pops those items off the stack.
Queue: An OS typically uses a queue to do things such as sending items to hardware, as well as CPU Scheduling.
Trees
Trees: Linux uses a balanced binary search tree (red-black)...similar to AVL Tree
Hash Functions and Maps
Hash Tables
A hash function takes data as its input, performs a numeric operation on the data, and returns a numeric value. This numeric value can then be used as an index into a table (typically an array) to quickly retrieve the data. Whereas searching for a data item through a list of size n can require up to O(n) comparisons, using a hash function for retrieving data from a table can be as good as O(1), depending on implementation details. Because of this performance, hash functions are used extensively in operating systems.
We can use Hash Maps to say, authenticate users
suppose that a user name is mapped to a password. Password authentication then proceeds as follows: a user enters her user name and password. The hash function is applied to the user name, which is then used to retrieve the password. The retrieved password is then compared with the password entered by the user for authentication.
Bitmaps
Bitmaps: commonly used when there is a need to represent the availability of a large number of resources. Disk drives provide a nice illustration. A medium-sized disk drive might be divided into several thousand individual units, called disk blocks. A bitmap can be used to indicate the availability of each disk block.
1.10 Computing Environments
Client-Server Computing
Contemporary network architecture features arrangements in which server systems satisfy requests generated by client systems. This form of specialized distributed system, called a client-server system
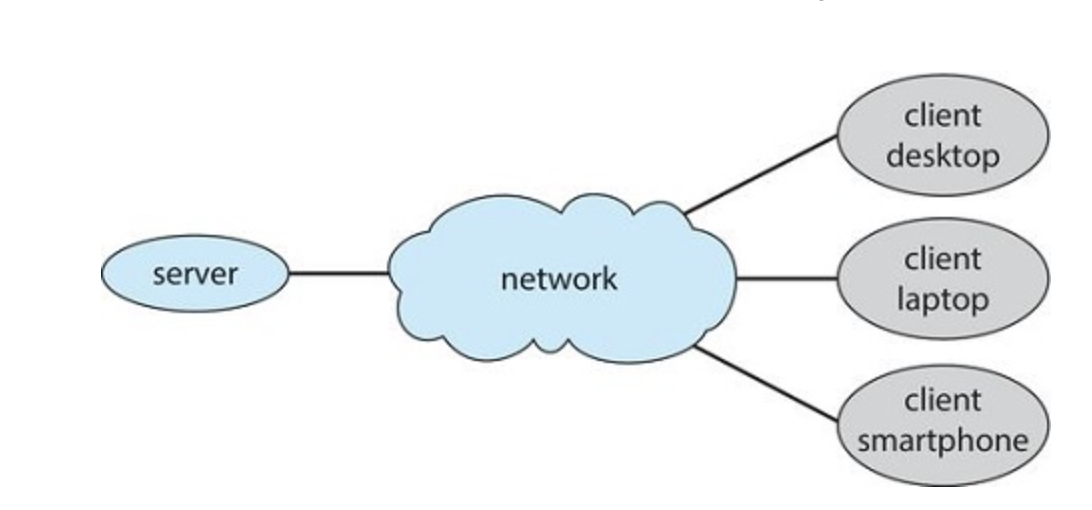
Servers can be broadly categorized as computer serves and file servers
- Compute-Server System: Client Sends Request, Server executes the action, returns the result
- File-Server System: Clients Create, Update, Read, and Delete C.R.U.D files
Peer-to-Peer (P2P)
In this system, clients and servers are not distinguished from one another. All nodes are peers and may act as a client or a server
To participate in a peer-to-peer system, a node must first join the network of peers. Once a node has joined the network, it can begin providing services to—and requesting services from—other nodes in the network. Determining what services are available is accomplished in one of two general ways:
- When a node joins a network, it registers its service with a centralized lookup service on the network. Any node desiring a specific service first contacts this centralized lookup service to determine which node provides the service. The remainder of the communication takes place between the client and the service provider.
- An alternative scheme uses no centralized lookup service. Instead, a peer acting as a client must discover what node provides a desired service by broadcasting a request for the service to all other nodes in the network. The node (or nodes) providing that service responds to the peer making the request. To support this approach, a discovery protocol must be provided that allows peers to discover services provided by other peers in the network.
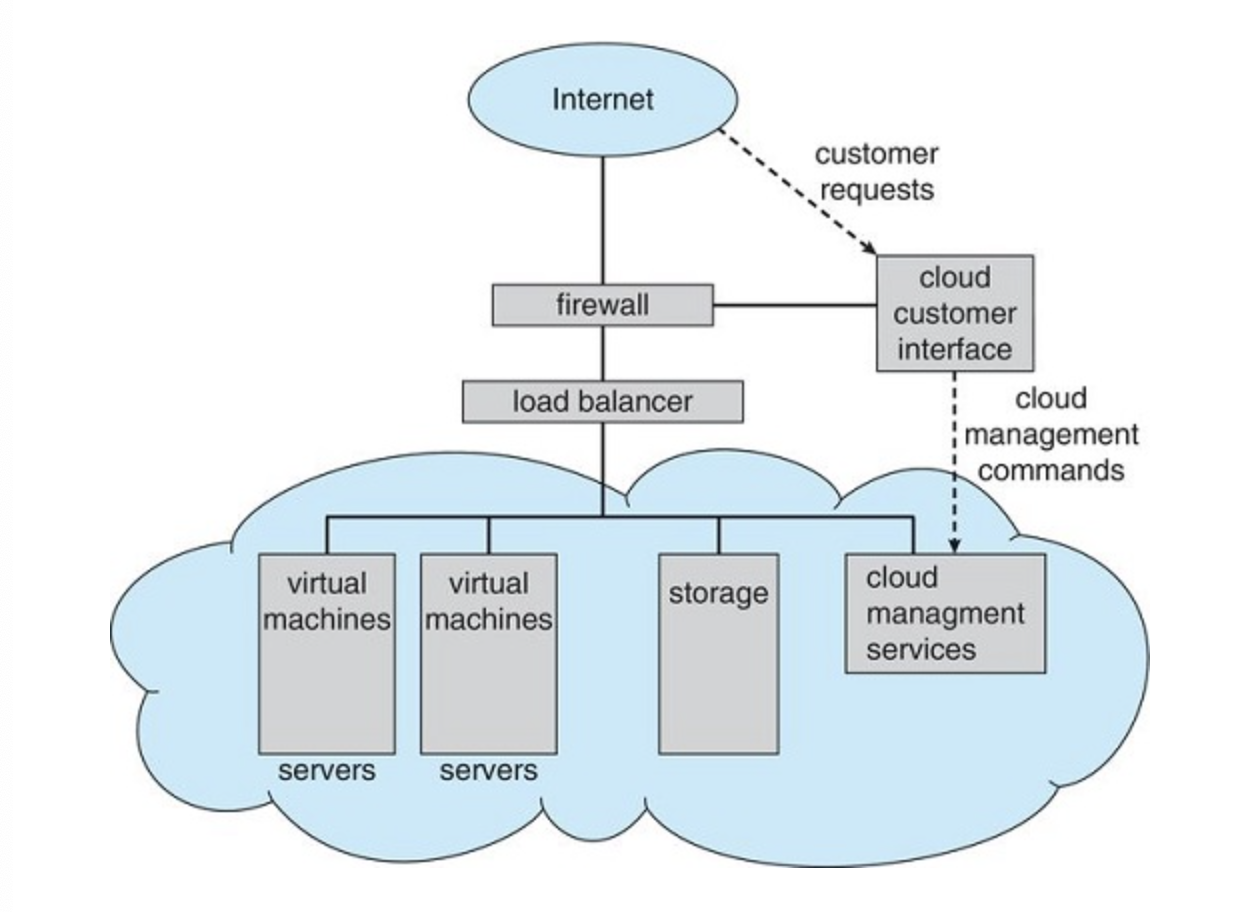
Cloud Computing
Uses virtualization as a base for its functionality
-
Public cloud—a cloud available via the Internet to anyone willing to pay for the services
-
Private cloud—a cloud run by a company for that company's own use
-
Hybrid cloud—a cloud that includes both public and private cloud components
Real-Time Embedded Systems
Make use of Real-Time Operating Systems RTOS