CSS 430 Book Notes Chapter 3 Processes
3.1 Process Concept
A process is a program in execution.
In most systems, a process is a unit of work
Modern operating systems support processes having multiple threads of control. Where you have multiple cores, you can have parallel threads
Chapter Objectives
- Identify the separate components of a process and illustrate how they are represented and scheduled in an operating system.
- Describe how processes are created and terminated in an operating system, including developing programs using the appropriate system calls that perform these operations.
- Describe and contrast interprocess communication using shared memory and message passing.
- Design programs that use pipes and POSIX shared memory to perform interprocess communication.
- Describe client-server communication using sockets and remote procedure calls.
- Design kernel modules that interact with the Linux operating system.
The process
A Process is a program in execution with the status being represented by the value of the program counter and the contents of the processors registers.
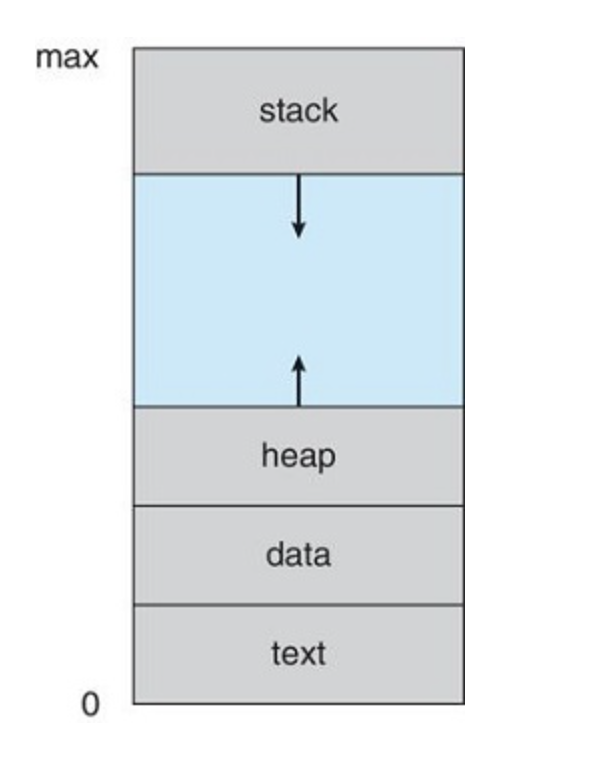
- Text: Executable code
- Data: global variables
- Heap: dynamically allocated memory
- Stack: temporary data storage when invoking functions (such as parameters return address and local variables)
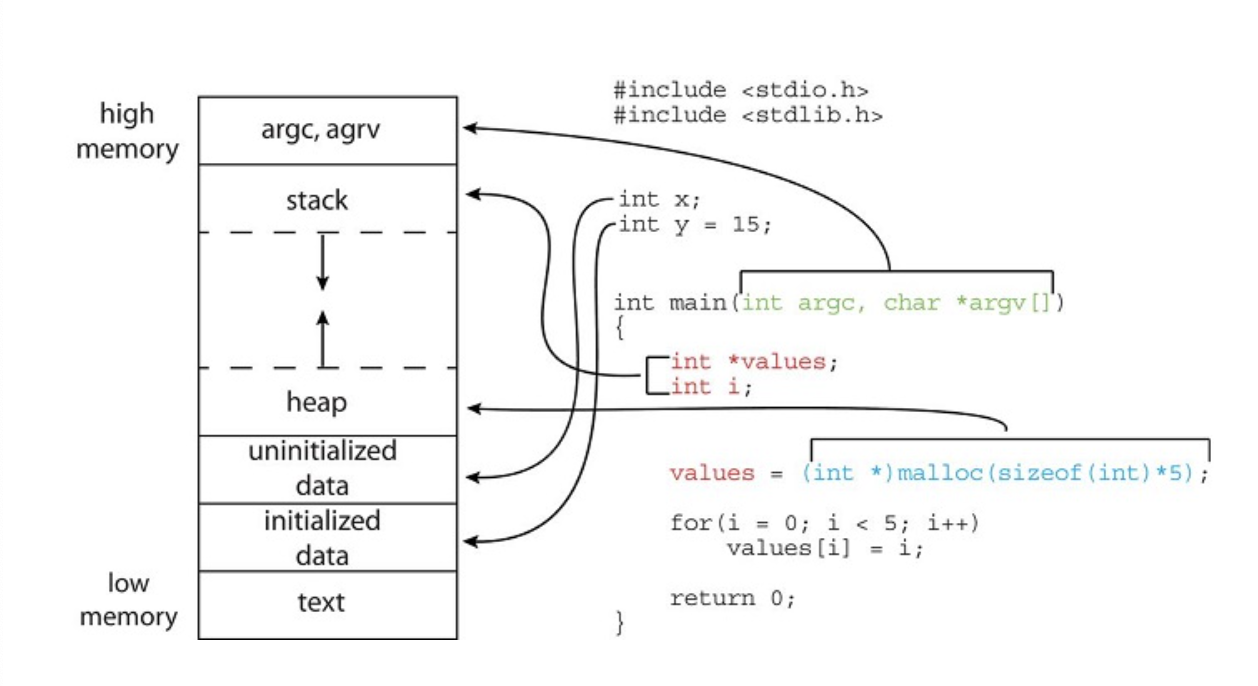
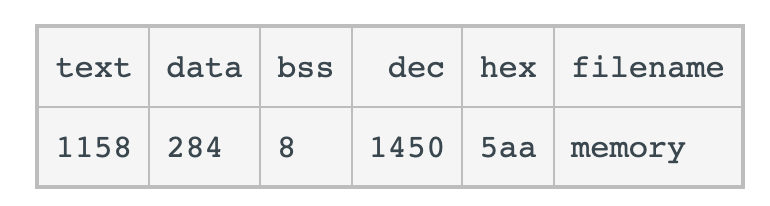
The GNU size command can be used to determine the size (in bytes) of some of these sections. Assuming the name of the executable file of the above C program is memory, the following is the output generated by entering the command size memory:
Each time a function is called, an activation record containing function parameters, local variables and return address are pushed onto the stack. When control is returned, the activation record is popped from the stack.
The heap will grow as memory is dynamically allocated and will shrink when memory is returned to the system
The heap and stack grow towards each other, therefore its important that the os ensures they don't overlap (See Buffer Overflow).
A program is not a process and is passive. A program is passive. A process is an active entity with a program counter specifiying the next instruction to execute
Multiple processes may be associated with the same program, however they are separate execution sequences
Process state
As a process executes, it changes states.
A process may be in one of the following states:
- New: the process is being created
- Running: Instructions are being executed
- Waiting: The process is waiting for some event to occur
- Ready: The process is waiting to be assigned to a processor
- Terminated: The process has finished execution
Only one process can be running on any processor core at any instant
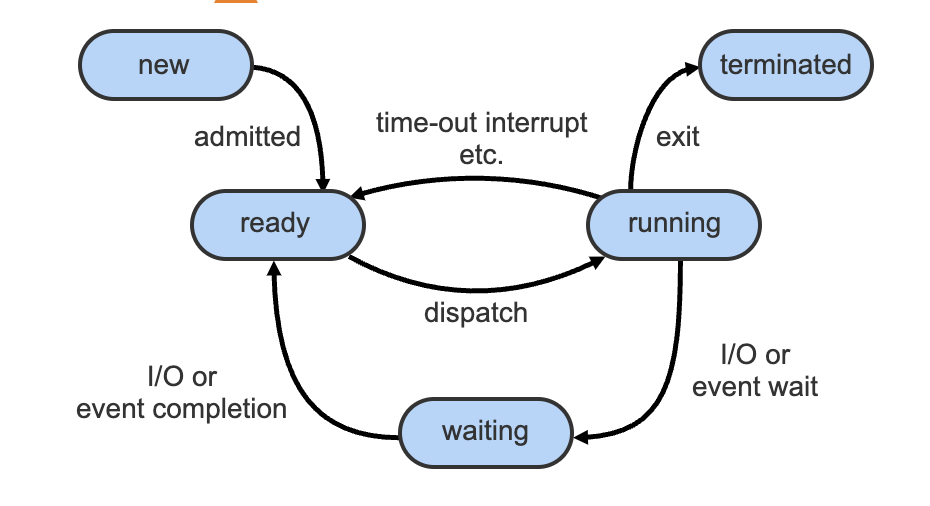
- A new process is created. The new process is moved to the ready state.
- The process is scheduled onto a core that is available and running. If an I/O request or an event request occurs, the process is moved to the waiting state.
- Once the I/O request or event request is completed, the process is moved back to the ready state.
- If the process is running and the core is needed, for example by an interrupt, the process is moved back to the ready state.
- The cycle continues until the process exits, fails, or is terminated. The process then moves to the terminated state.
Process control block
Each process is represented in the operating system by a PCB (Process control block) also known as a task control block
The pcb contains many pieces of info associated with a specific process including:
- State
- Program counter: The address of the next process instruction
- CPU Registers
- CPU-scheduling information: process priority, pointers to scheduling queues and other parameters
- memory-management information
- Accounting information: amount of cpu and real time used, time limits, job or process numbers etc
- I/O status info: list of I/O devices allocated to the process. open files. etc

Threads
Most modern operating systems have extended the process concept to allow a process to have multiple threads of execution and thus to perform more than one task at a time.
A multithreaded word processor could, for example, assign one thread to manage user input while another thread runs the spell checker. On systems that support threads, the PCB is expanded to include information for each thread. Other changes throughout the system are also needed to support threads. Chapter Threads & Concurrency explores threads in detail.
3.2 Process Scheduling
The process scheduler selects an available process for program execution on a core.
The number of process currently in memory is known as the degree of multiprogamming
An I/O bound process is one that spends more time doing I/O than it spends doing computations where as a CPU-bound process generates I/O requests infrequently
Scheduling queues
As processes enter the system, they are put into a ready queue, where they are ready and waiting to execute on a CPU's core
This queue is generally stored as a linked list with a ready-queue header containing pointers to the first PCB in the lst and each PCB with a pointer field that st points to the net PCB in the ready queue.
Processes that are waiting for a certain event to occur (such as I/O completion) are placed in a wait queue
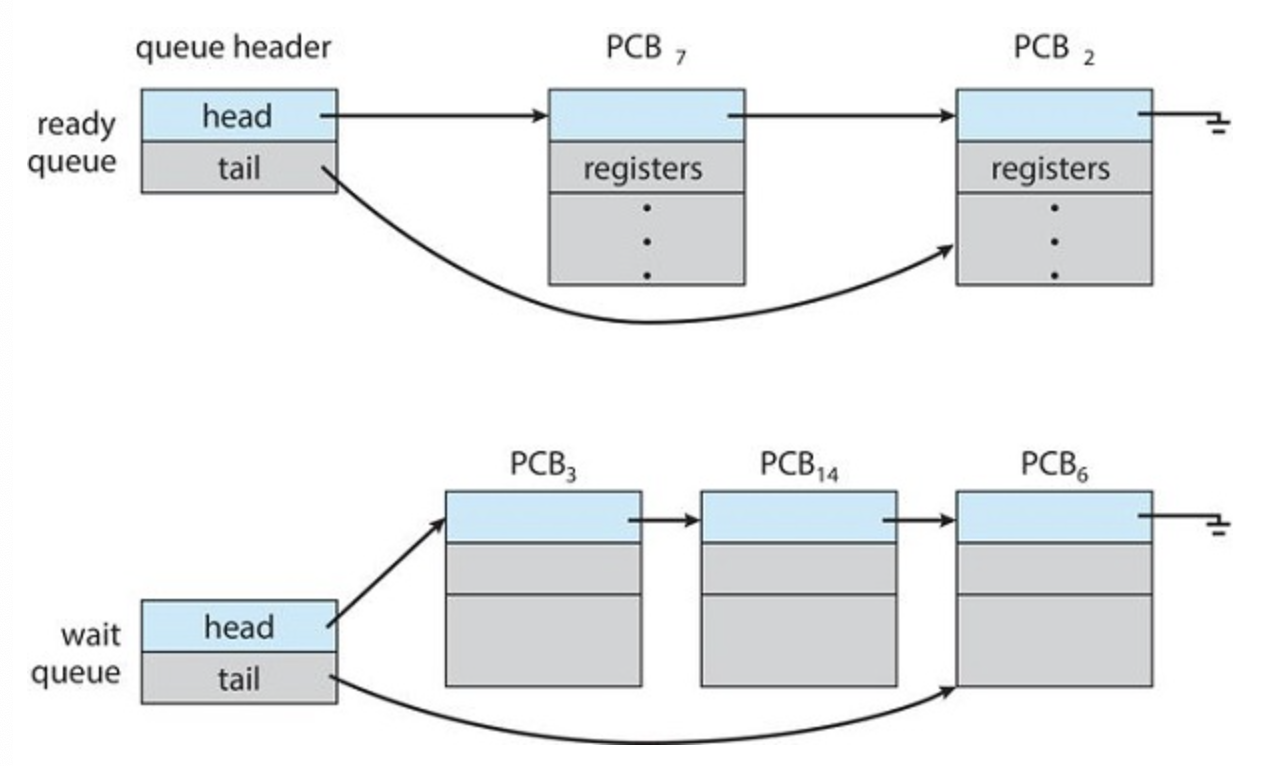
A queueing diagram is a comment way to represent the scheduling of processes. Two types of queues are present, ready and wait. Circles represent the resources that serve teh queue and the arrow is the flow of processes in the system.
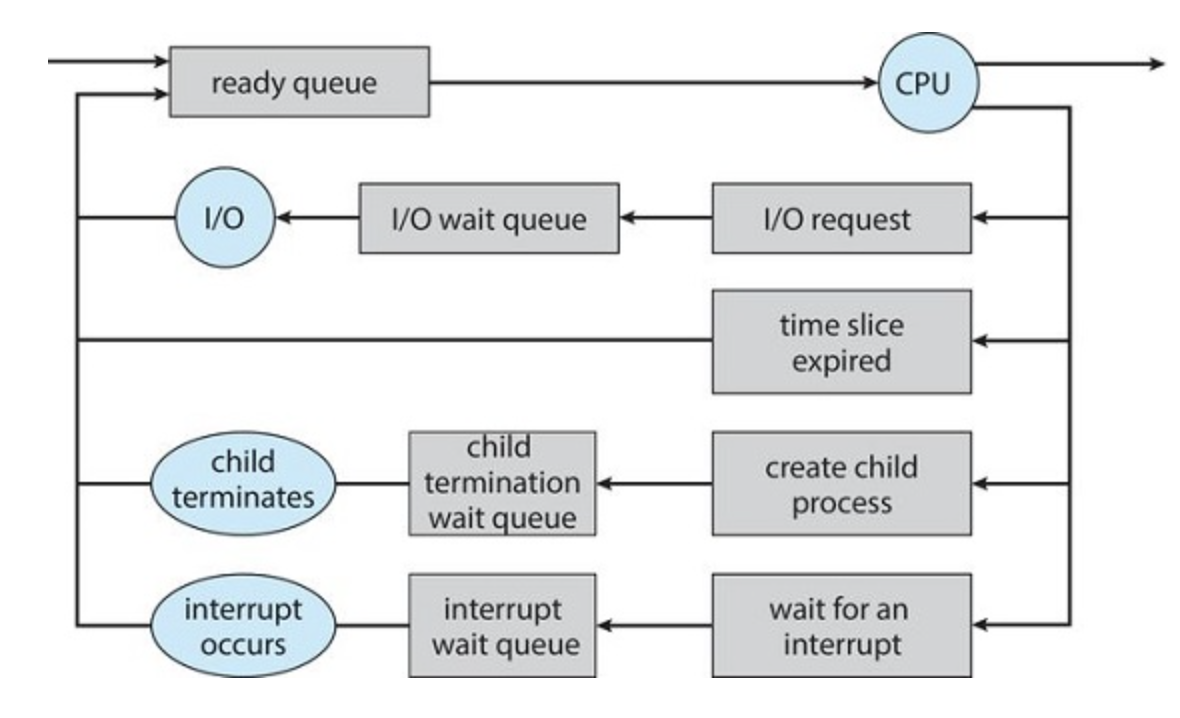
A new process starts in the ready queue, it waits until it's popped off for execution (dispatched). Once a process is allocated to a core, one of several events can occur:
- The process could issue an I/O request and then be placed in an I/O wait queue.
- The process could create a new child process and then be placed in a wait queue while it awaits the child's termination.
- The process could be removed forcibly from the core, as a result of an interrupt or having its time slice expire, and be put back in the ready queue.
This cycle continues until it terminates at which point it is removed from all queues and it's PCB and resources are deallocated
CPU Scheduling
The role of the CPU scheduler is to select from among the processes that are in the ready queue and allocate a CPU core to one of them.
The CPU scheduler executes at least once every 100 milliseconds, although typically much more frequently.
Some operating systems have an intermediate form of scheduling, known as swapping, whose key idea is that sometimes it can be advantageous to remove a process from memory (and from active contention for the CPU) and thus reduce the degree of multiprogramming. Later, the process can be reintroduced into memory, and its execution can be continued where it left off.
Context Switch
When an interrupt occurs, the system needs to save the current context of the process running on the CPU core so that it can restore that context when its processing is done, essentially suspending the process and then resuming it.
Generically, we perform a state save of the current state of the CPU core, be it in kernel or user mode, and then a state restore to resume operations.
Switching the CPU core to another process requires performing a state save of the current process and a state restore of a different process. This task is known as a context switch
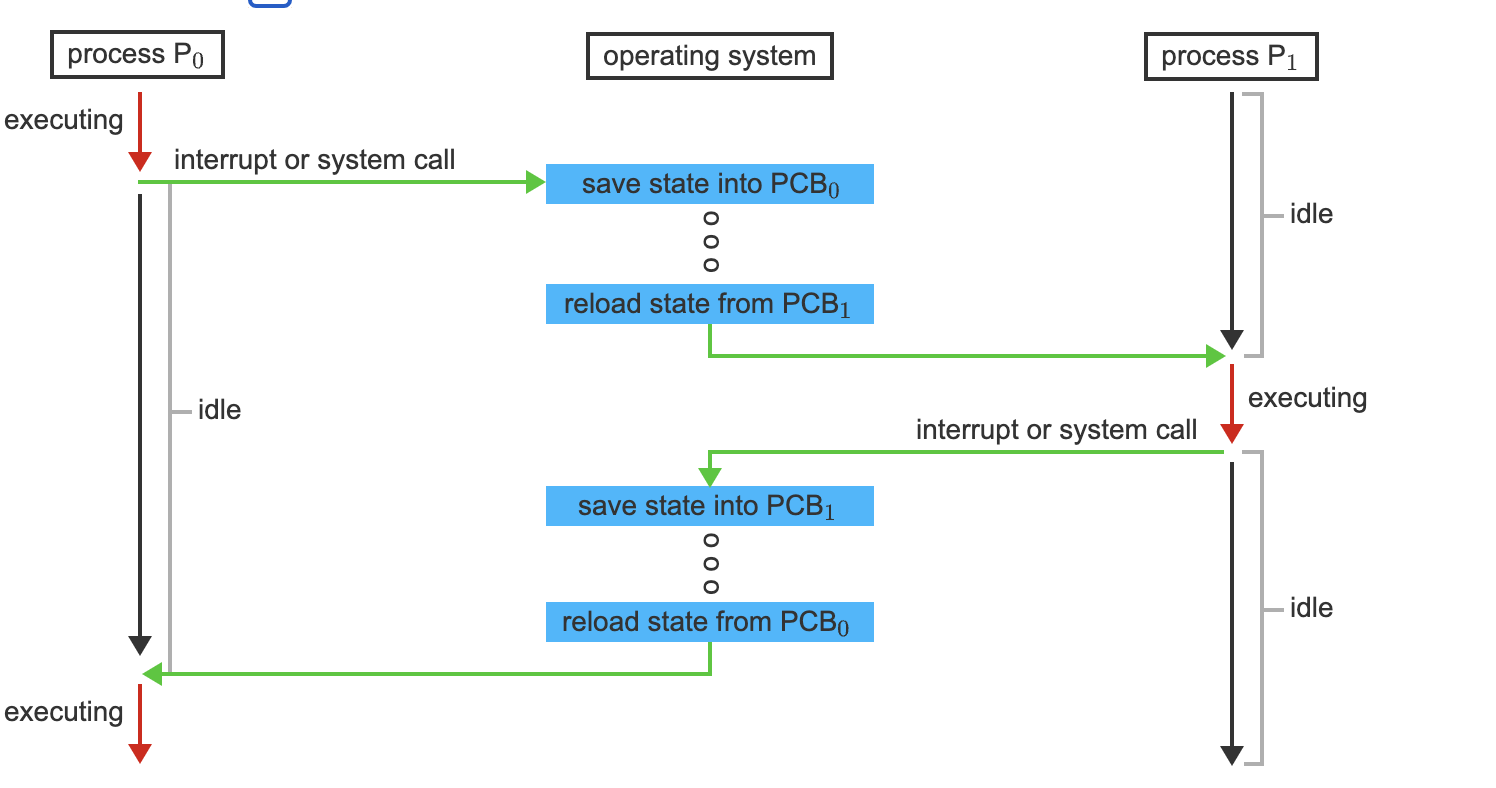
- The system has two processes, P0 and P1. P1 is idle, P0 is executing and executes a system call, or the system receives an interrupt. The operating system saves the state of P0 in its PCB.
- P0 is now off core, so idle. The operating system restores the state of P1 from its PCB and puts P1 on the core. It continues execution.
- P1 execution is interrupted, the operating system saves its state to its PCB and restores the next process's state (P0 in this case) to prepare it to continue execution.
- The operating system puts P0 onto the core, continuing its execution while P1 is now idle, in ready state, waiting its turn.
3.3 Operations on processes
Process creation
Processes may create new processes. The creating process is called a parent, and the created process, a child. Each new child process may create other process which forms a tree of processes
Most operating systems identify a process according to a unique process identifier (PID).
In linux, the systemd process always has a PID of 1 and serves as the root process for all other user process and is the first user process created on boot.
The systemd process then crates processes which provide additional services
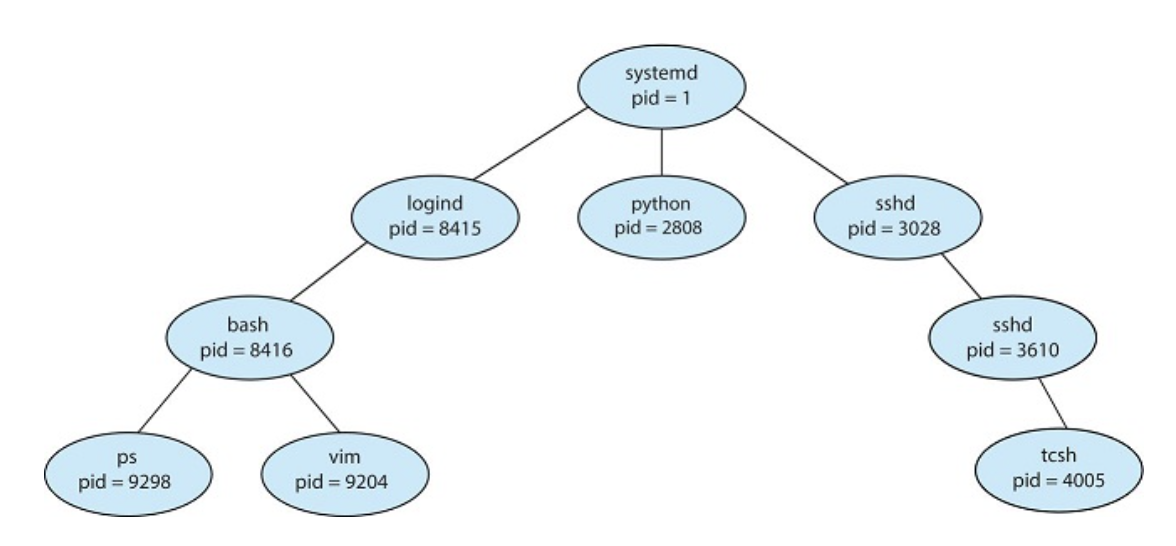
When a process creates a new process, two possibilities for execution exist:
- The parent continues to execute concurrently with its children
- The parent waits until some or all of its children have terminated
There are also two address-space possibilities for the new process
- the child process is a duplicate of the parent
- the child process has a new program loaded into it.
Creating a separate process using the fork() system call
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
pid_t pid;
/* fork a child process */
pid = fork();
if (pid < 0) { /* error occurred */
fprintf(stderr, "Fork Failed");
return 1;
}
else if (pid == 0) { /* child process */
execlp("/bin/ls","ls",NULL);
}
else { /* parent process */
/* parent will wait for the child to complete */
wait(NULL);
printf("Child Complete");
}
return 0;
}
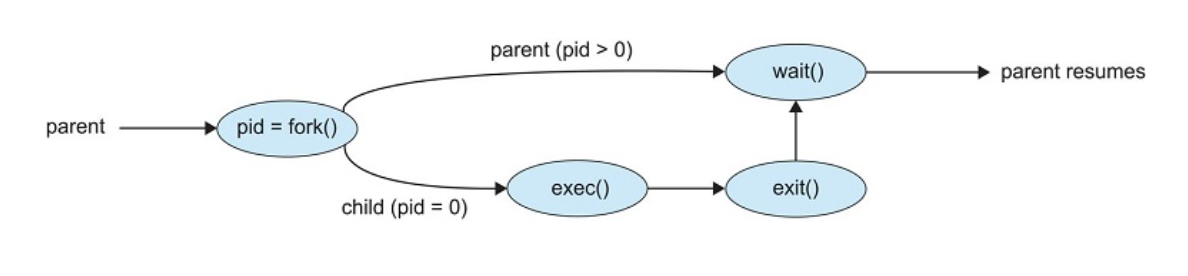
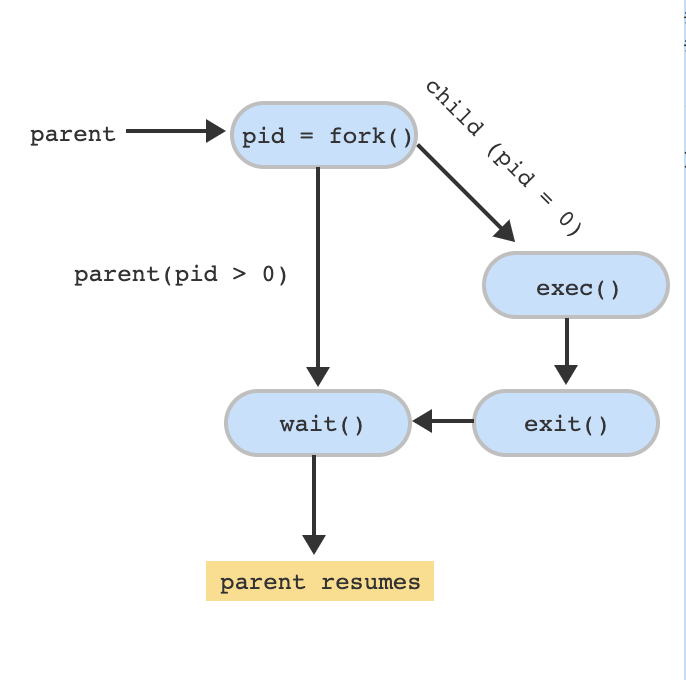
- Parent calls the fork() system call which creates the child process. The child is a copy of the parent process which means there are two processes that return from the fork() system call – the parent and child processes.
- The fork() system call returns 0 to identify the child process. In this case, the child process will run the exec() system call which runs the "ls" command.
- The fork() system call returns a value > 0 to the parent and the parent calls the wait() system call waiting for the child process to terminate.
- The child process will terminate by calling the exit() system call.
- Once the child process terminates, the parent process returns from wait() and resumes.
Process termination
The exit() system call is used to ask the operating system to delete the process.
A parent may terminate the execution of one of its children for a variety of reasons, such as these:
- The child has exceeded its usage of some of the resources that it has been allocated. (To determine whether this has occurred, the parent must have a mechanism to inspect the state of its children.)
- The task assigned to the child is no longer required.
- The parent is exiting, and the operating system does not allow a child to continue if its parent terminates.
In some operating systems, a child cannot exist if a parent has terminated. If a parent is terminated, all children must also be terminated, this is called cascading termination
The wait() system call is passed a parameter that allows the parent to obtain the exit status of the child.
When a process terminates, its resources are deallocated by the operating system. However, its entry in the process table must remain there until the parent calls wait(), because the process table contains the process's exit status. A process that has terminated, but whose parent has not yet called wait(), is known as a zombie process.
3.4 Interprocess Communication
A process is independent if it does not share data with any other processes executing in the system.
A process is cooperating if it can affect or be affected by the other processes executing in the system.
Cooperating processes require an interprocess communication (IPC) mechanism that will allow them to exchange data.
There are two fundamental models of interprocess communication: shared memory and message passing.
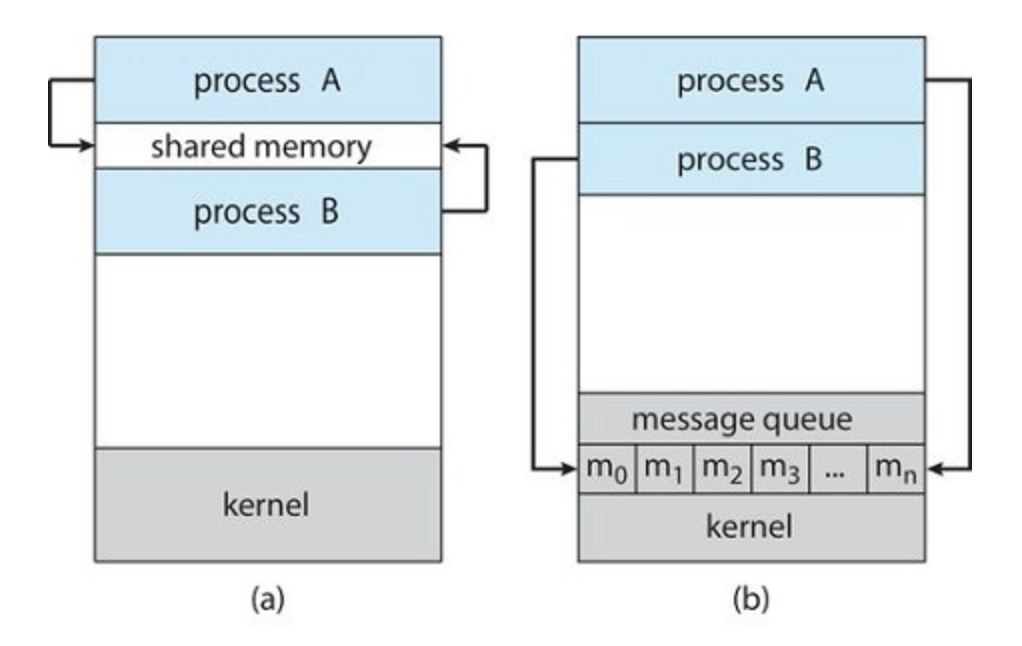
Message passing is useful for exchanging smaller amounts of data, because no conflicts need be avoided and it's easier to implement in a distributed system.
Shared memory can be faster than message passing, since message-passing systems are typically implemented using system calls and thus require the more time-consuming task of kernel intervention.
3.5 IPC in shared-memory systems
Typically, a shared-memory region resides in the address space of the process creating the shared-memory segment. Other processes that wish to communicate using this shared-memory segment must attach it to their address space.
One solution to the producer-consumer problem uses shared memory. To allow producer and consumer processes to run concurrently, we must have available a buffer of items that can be filled by the producer and emptied by the consumer.
An unbounded buffer places no limit on the size of the buffer, where as a bounded buffer does
3.6 IPC in message-passing systems
A message-passing facility provides at least two operations:
send(message) and receive(message)
If processes P and Q want to communicate, they must send messages to and receive messages from each other: a communication link must exist between them.
Naming
Processes that want to communicate must have a way to refer to each other. They can use either direct or indirect communication.
Direct Communication: each process must explicitly name the recipient or sender
send(P, message)—Send amessageto processP.receive(Q, message)—Receive amessagefrom processQ.
This scheme exhibits symmetry in addressing; that is, both the sender process and the receiver process must name the other to communicate.
With asymmetry, only the sender names the recipient; the recipient is not required to name the sender. In this scheme, the send() and receive() primitives are defined as follows:
send(P, message)—Send amessageto processP.receive(id, message)—Receive amessagefrom any process. The variableidis set to the name of the process with which communication has taken place.
These are both limited as it requires some form of hard-coding
With indirect communication, the messages are sent to and received from mailboxes, or ports.
-
send(A, message)—Send amessageto mailboxA. -
receive(A, message)—Receive amessagefrom mailboxA.
receive() from A. Which process will receive the message sent by P1? The answer depends on which of the following methods we choose:
- Allow a link to be associated with two processes at most.
- Allow at most one process at a time to execute a
receive()operation. - Allow the system to select arbitrarily which process will receive the message (that is, either P2 or P3, but not both, will receive the message). The system may define an algorithm for selecting which process will receive the message (for example, round robin, where processes take turns receiving messages). The system may identify the receiver to the sender.
Synchronization
Message passing may be either blocking or nonblocking—also known as synchronous and asynchronous.
-
Blocking send. The sending process is blocked until the message is received by the receiving process or by the mailbox.
-
Nonblocking send. The sending process sends the message and resumes operation.
-
Blocking receive. The receiver blocks until a message is available.
-
Nonblocking receive. The receiver retrieves either a valid message or a null
Buffering
Messages exchanged by communicating processes reside in a temporary queue. Such queues can be implemented in three ways:
-
Zero capacity. The queue has a maximum length of zero; thus, the link cannot have any messages waiting in it. In this case, the sender must block until the recipient receives the message.
-
Bounded capacity. The queue has finite length n; thus, at most n messages can reside in it. If the queue is not full when a new message is sent, the message is placed in the queue (either the message is copied or a pointer to the message is kept), and the sender can continue execution without waiting. The link's capacity is finite, however. If the link is full, the sender must block until space is available in the queue.
-
Unbounded capacity. The queue's length is potentially infinite; thus, any number of messages can wait in it. The sender never blocks.
3.7 Examples of IPC systems
Pipes
A pipe acts as a conduit allowing two processes to communicate.
Ordinary pipes allow two processes to communicate in standard producer-consumer fashion: the producer writes to one end of the pipe (the write end) and the consumer reads from the other end (the read end).
On UNIX systems, ordinary pipes are constructed using the function pipe(int fd[])
This function creates a pipe that is accessed through the int fd[] file descriptors: fd[0] is the read end of the pipe, and fd[1] is the write end. UNIX treats a pipe as a special type of file. Thus, pipes can be accessed using ordinary read() and write() system calls.
An ordinary pipe cannot be accessed from outside the process that created it.
Typically, a parent process creates a pipe and uses it to communicate with a child process that it creates via fork()
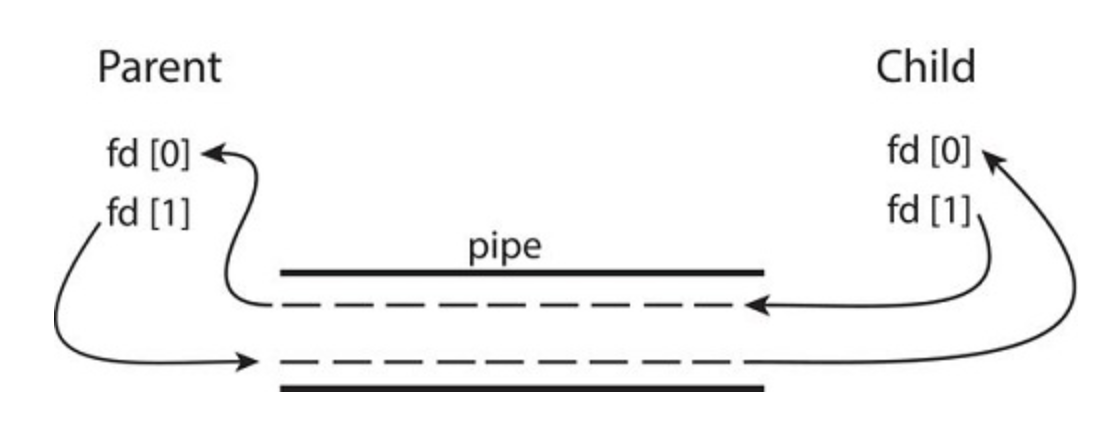
Ordinary Pipe in Unix
#include <sys/types.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#define BUFFER_SIZE 25
#define READ_END 0
#define WRITE_END 1
int main(void)
{
char write_msg[BUFFER_SIZE] = "Greetings";
char read_msg[BUFFER_SIZE];
int fd[2];
pid_t pid;
/* create the pipe */
if (pipe(fd) == -1) {
fprintf(stderr,"Pipe failed");
return 1;
}
/* fork a child process */
pid = fork();
if (pid < 0) { /* error occurred */
fprintf(stderr, "Fork Failed");
return 1;
}
if (pid > 0) { /* parent process */
/* close the unused end of the pipe */
close(fd[READ_END]);
/* write to the pipe */
write(fd[WRITE_END], write_msg, strlen(write_msg)+1);
/* close the write end of the pipe */
close(fd[WRITE_END]);
}
else { /* child process */
/* close the unused end of the pipe */
close(fd[WRITE_END]);
/* read from the pipe */
read(fd[READ_END], read_msg, BUFFER_SIZE);
printf("read %s",read_msg);
/* close the read end of the pipe */
close(fd[READ_END]);
}
return 0;
}
3.8 Communication in client-server systems
Sockets
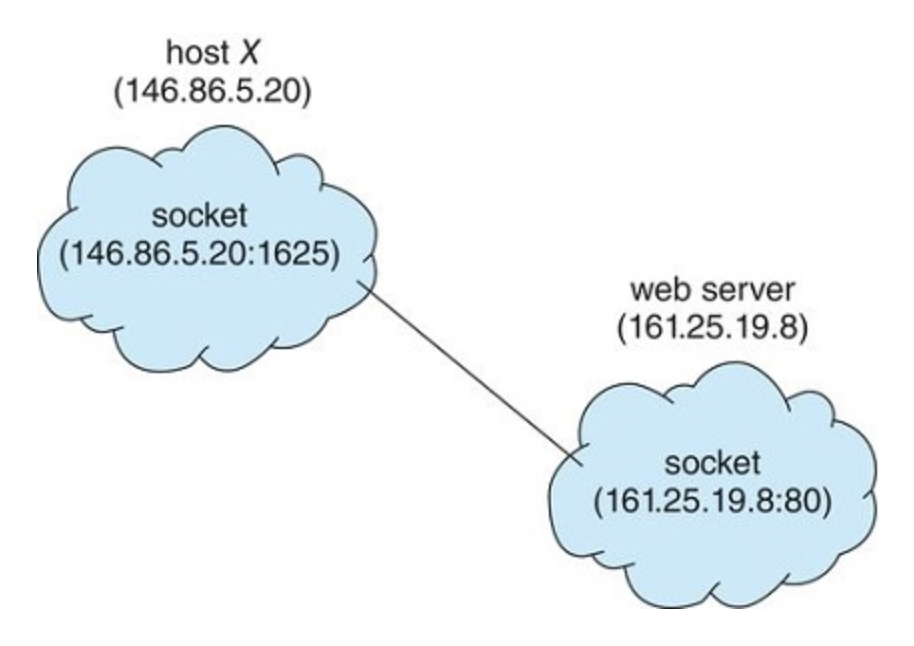
A socket is defined as an endpoint for communication. A pair of processes communicating over a network employs a pair of sockets—one for each process.
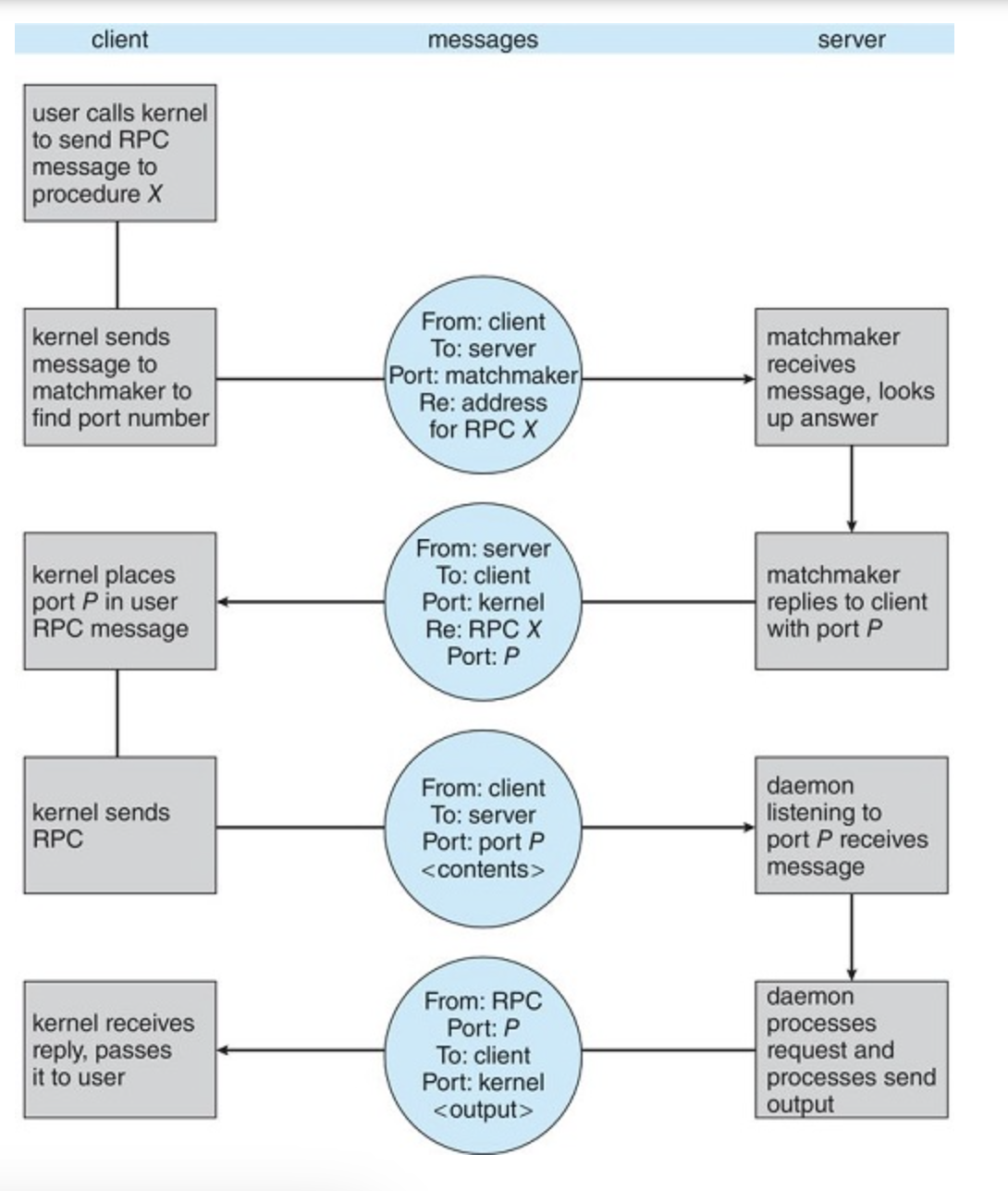
Remote Procedure Calls
A port in this context is simply a number included at the start of a message packet.