CSS 430 Book Notes Chapter 5 - CPU Scheduling
5.1 Basic Concepts
On modern operating systems, it's kernel-level threads, not processes that are being scheduled by the operating system.
Chapter Objectives
- Describe various CPU scheduling algorithms.
- Assess CPU scheduling algorithms based on scheduling criteria.
- Explain the issues related to multiprocessor and multicore scheduling.
- Describe various real-time scheduling algorithms.
- Describe the scheduling algorithms used in the Windows, Linux, and Solaris operating systems.
- Apply modeling and simulations to evaluate CPU scheduling algorithms.
- Design a program that implements several different CPU scheduling algorithms.
Several processes are kept in memory at one time. When one process has to wait, the operating system takes the CPU away from that process and gives the CPU to another process.
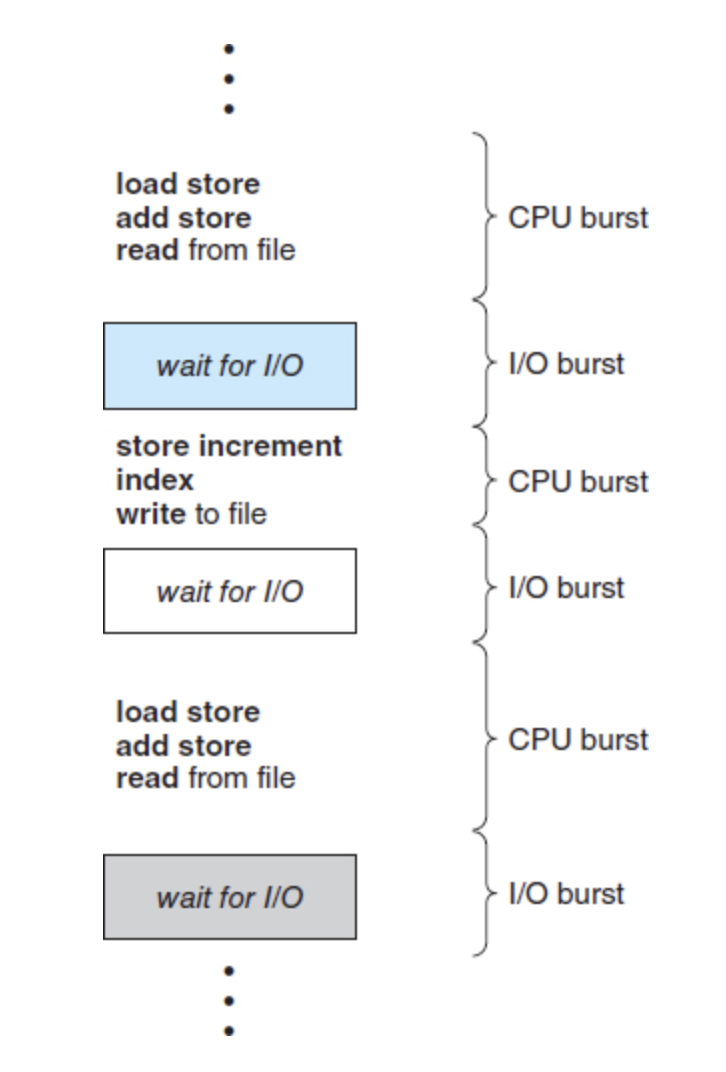
The success of CPU scheduling depends on an observed property of processes: process execution consists of a cycle of CPU execution and I/O wait. Processes alternate between these two states.
Process execution begins with a CPU burst. That is followed by an I/O burst, which is followed by another CPU burst, then another I/O burst, and so on until the system requests to terminate execution
Alternating sequence of CPU and I/O bursts.
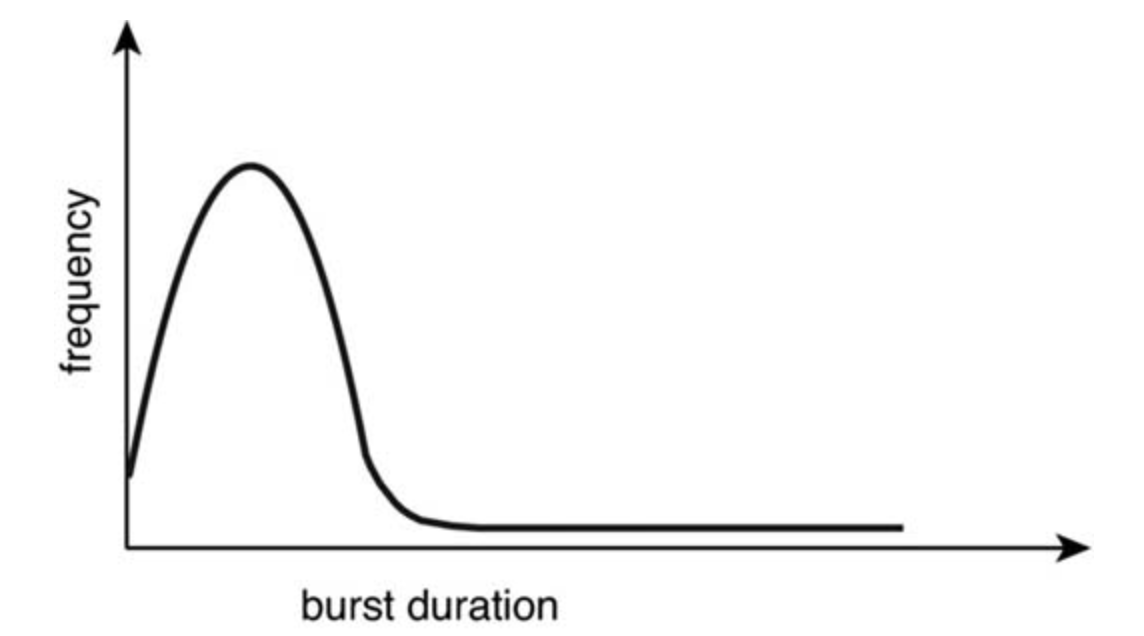
CPU-Burst Duration Histogram
CPU Scheduler
- Selects a process from the processes in memory that are ready to execute and allocates the CPU to that proces
The ready queue is not necessarily FIFO
Preemptive and nonpreemptive scheduling
CPU-Scheduling may take place under the following four circumstances
-
When a process switches from the running state to the waiting state (for example, as the result of an I/O request or an invocation of
wait()for the termination of a child process) -
When a process switches from the running state to the ready state (for example, when an interrupt occurs)
-
When a process switches from the waiting state to the ready state (for example, at completion of I/O)
-
When a process terminates
For circumstances 1 and 4, the scheduling scheme is non-preemptive, however for 2 and 3 it is preemptive.
With nonpreemptive scheduling, once the CPU has been allocated to a process, the process keeps the CPU until it releases it either by terminating or by switching to the waiting state.
Preemptive scheduling can result in race conditions with data shared among several processes. Most modern operating systems are preemptive
While one process is updating the data, it is preempted so that the second process can run. The second process then tries to read the data, which are in an inconsistent state.
Dispatcher
The dispatcher is the module that gives control of the CPU's core to the process selected by the CPU scheduler and includes the following:
- Switching context from one process to another
- Switching to user mode
- Jumping to the proper location in the user program to resume that program
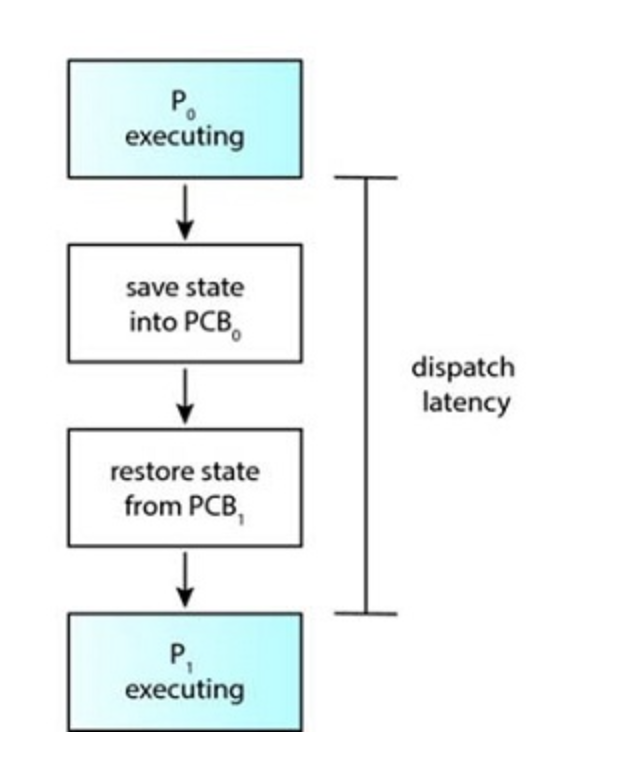
The dispatcher is invoked during each context switch. The time it takes to stop a process and start another one is called dispatch latency.
The role of the dispatcher
Voluntary Context Switch: The process has given up control because it requires a resource that is unavailable.
Non-voluntary: the cpu has been taken away from a process such as during preemption.
5.2 Scheduling Criteria
CPU Utilization
We want to keep the CPU as busy as possible
Throughput
If the CPU is busy executing processes, then work is being done. One measure of work is the number of processes that are completed per time unit, called throughput.
Turnaround Time
From the point of view of a particular process, the important criterion is how long it takes to execute that process. The interval from the time of submission of a process to the time of completion is the turnaround time.
Waiting Time
The CPU-scheduling algorithm does not affect the amount of time during which a process executes or does I/O. It affects only the amount of time that a process spends waiting in the ready queue. Waiting time is the sum of the periods spent waiting in the ready queue.
Response Time
Another measure is the time from the submission of a request until the first response is produced. This measure, called response time, is the time it takes to start responding, not the time it takes to output the response.
5.3 Scheduling Algorithms
CPU scheduling deals with the problem of deciding which of the processes in the ready queue is to be allocated the CPU's core.
First-come, first serve (FCFS)
With this scheme, the process that requests the CPU first is allocated the CPU first.

- FCFS scheduling for the five processes that arrived in the order P1, P2, P3, P4, and P5.
- Each process is associated with a burst time.
- A Gantt Chart is used to demonstrate the order in which processes are selected for scheduling using the FCFS scheduling algorithm.
- Process P1 is selected first as it is the first process to arrive. It begins running at time 0. After P1 finishes running, P2 is selected to run at time 7.
- Process P3 is selected next and runs at time 10. Process P4 is selected to run at time 22.
- P5 arrives last, and thus it is the last process to be selected by the FCFS scheduling algorithm and begins running at time 27. At time 36,process P5 finishes running.
Downsides
The average waiting time is long
It's non preemptive
Shortest Job First Scheduling (SJF)
Each process is associated with the length of the processes next CPU burst. When the CPU is available, it assigns the process with the next available CPU burst. If two burst sizes are the same, FCFS is followed
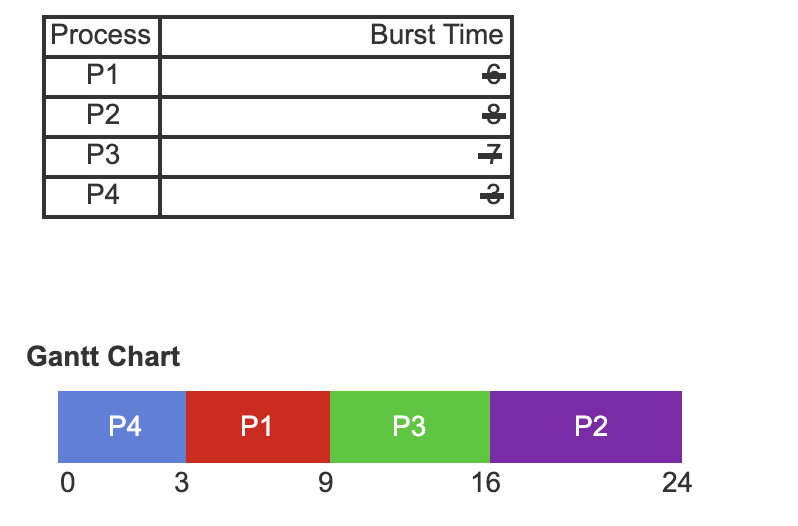
- SJF scheduling for the four processes that arrived in the order P1, P2, P3, and P4.
- Each process is associated with a burst time.
- A Gantt Chart is used to demonstrate the order in which processes are selected for scheduling using the SJF scheduling algorithm.
- Process P4 is selected first as P4 is the process with the shortest CPU burst. P4 begins running at time 0. Process P4 finishes running at time 3.
- Process P1 is selected next as P1 has the next shortest CPU burst. Process P1 begins to run at time 3 and finishes at time 9. Process P3 then starts at time 9 and ends at time 16.
- Process P2 has the longest CPU burst, therefore P2 is scheduled last and runs at time 16. Process P2 finishes running at time 24.
SJF gives the minimum average waiting time for a given set of processes
It cannot be implemented at the level of CPU scheduling however as there is no way to know the length of next CPU Burst
The next CPU burst is generally predicted as an exponential average of the measured lenghts of CPU bursts
Prediction of length of next CPU burst
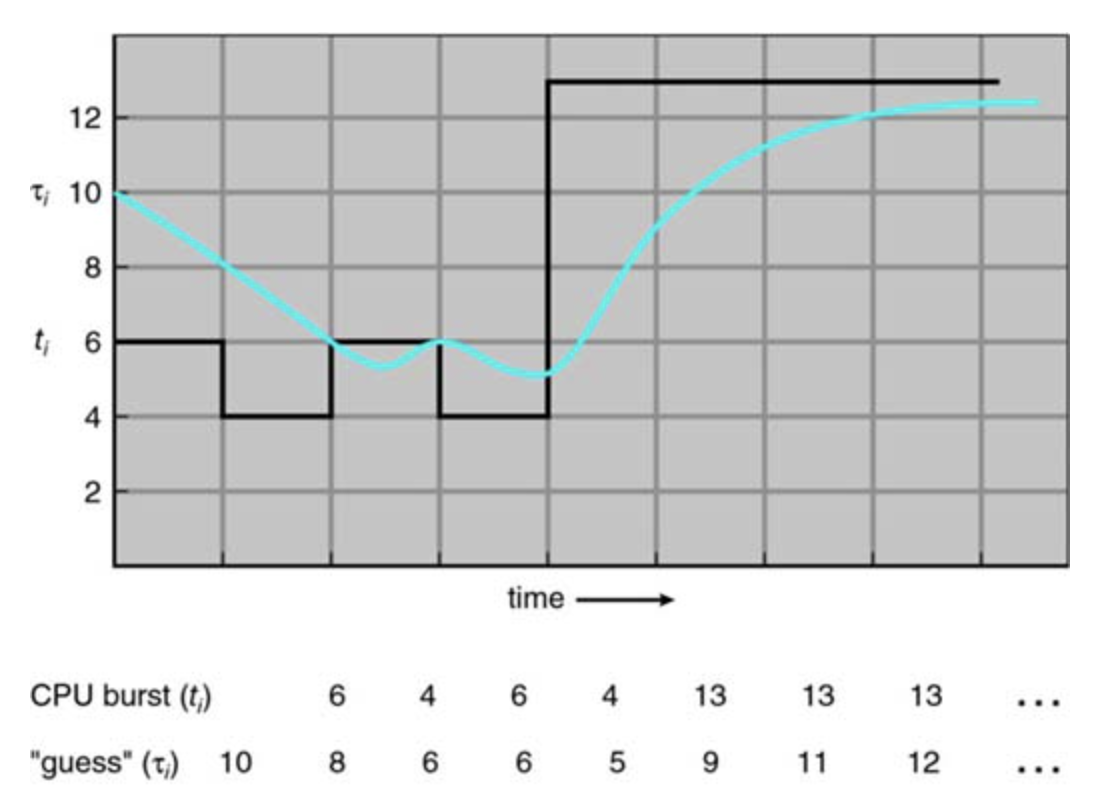
The SJF algo can be preemptive or non preemptive. The choice arises when a new process arrives at the ready queue while a previous process is still executing. The next CPU burst of the newly arrived process may be shorter than what is left of the currently executing process. A preemptive SJF algorithm will preempt the currently executing process, whereas a nonpreemptive SJF algorithm will allow the currently running process to finish its CPU burst.
Preemptive SJF is sometimes called "shortest-remainging-time-first"
Round-Robin Scheduling
Similar to FCFS, but with preemption. A small unite of time (time slice) is defined (generally from 10 to 100 ms). The ready queue is treated as a circular queue. The scheduler goes around the queue allocating the cpu to each process
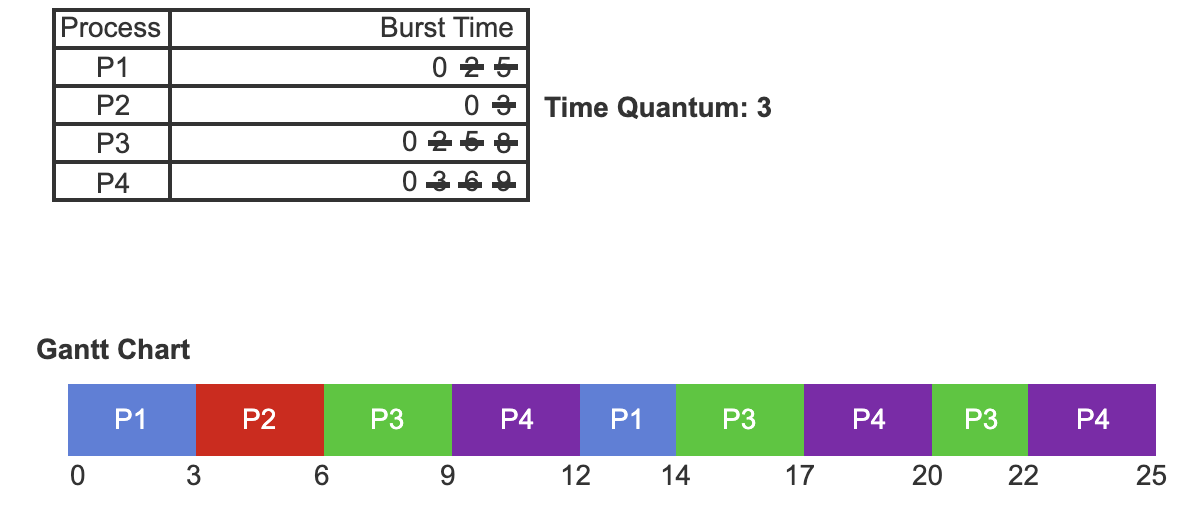
- RR scheduling for the four processes that arrived in the order P1, P2, P3, and P4.
- Each process is associated with a burst time. The time quantum is the amount of time a process can run before it is preempted and the CPU is assigned to another process.
- A Gantt Chart is used to demonstrate the order in which processes are selected for scheduling using the priority scheduling algorithm.
- Process P1 is selected first as it is the first process to arrive. P1 begins running at time 0 where it will run for the duration of a time quantum — three time units.
- Process P2 will run next, beginning at time 3. Process P2 runs for the duration of a time quantum. Process P2 completes its CPU burst.
- Process P3 and P4 run next. Both run for the duration of the time quantum.
- Process P1 only runs for the remaining duration of its CPU burst.
- The RR scheduling algorithm continues running until all remaining processes have completed their CPU burst.
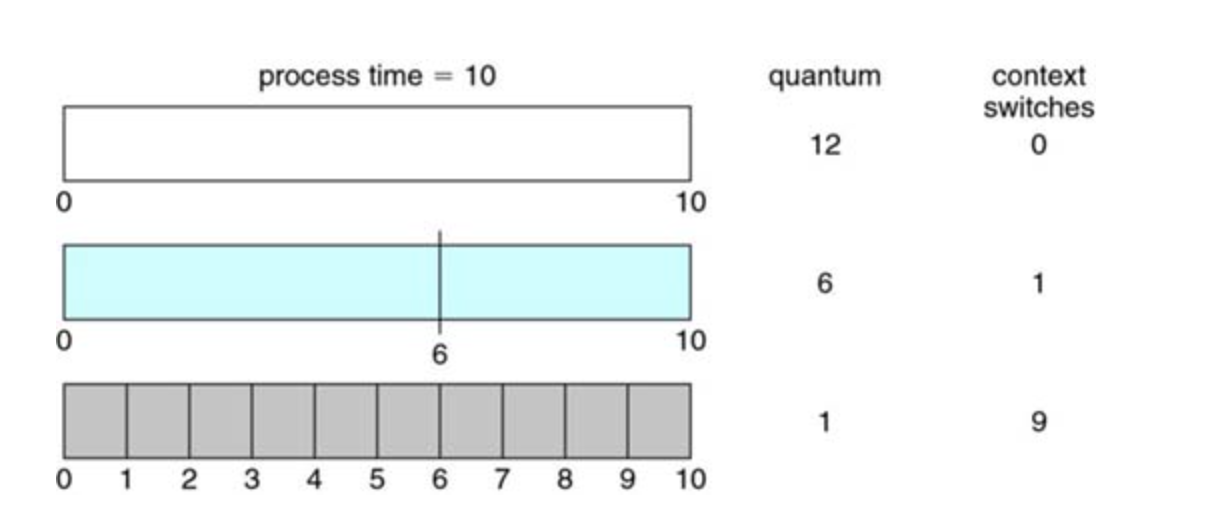
A smaller time quantum increases context switches
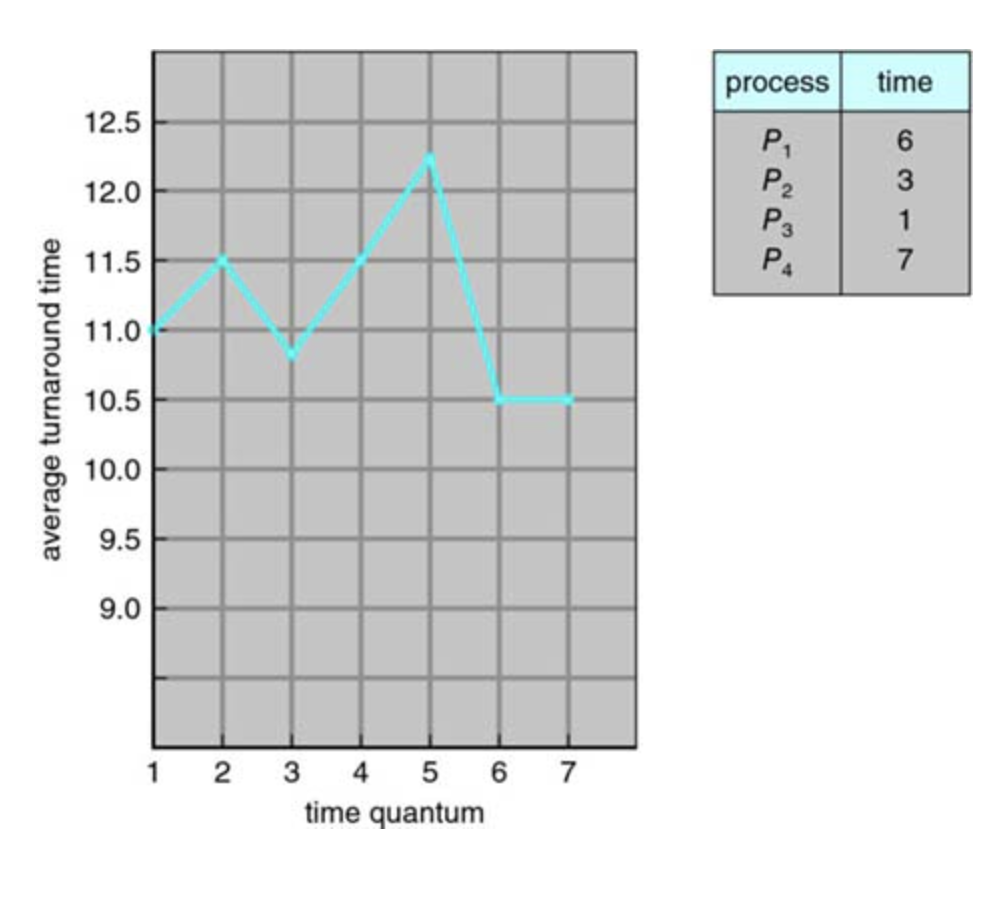
Turnaround time varies with quantum size
Priority Scheduling
A priority is associated with each process and the cpu is allocated to the process with the highest priority.
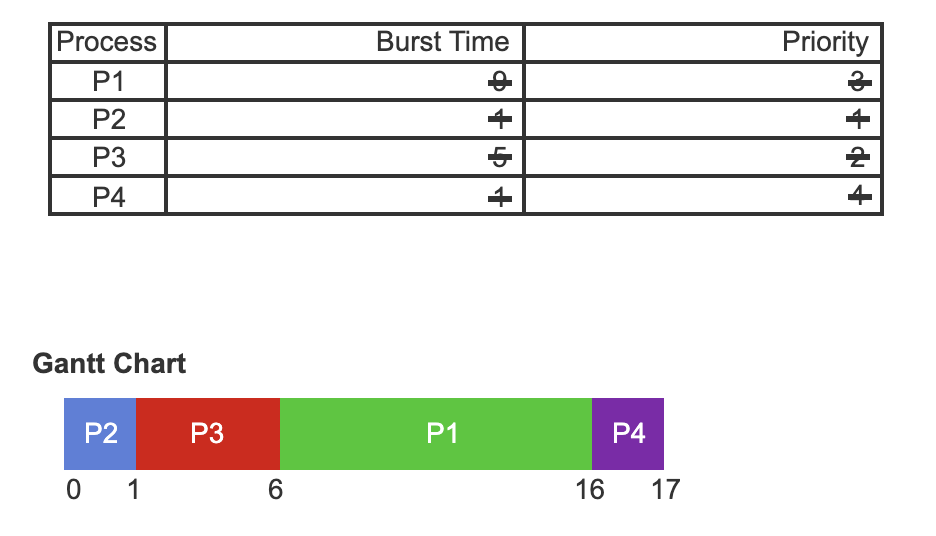
- Priority scheduling for the four processes P1, P2, P3, and P4.
- Each process is associated with a burst time. Each process is also associated with a priority where a lower value indicates a higher relative priority.
- A Gantt Chart is used to demonstrate the order in which processes are selected for scheduling using the priority scheduling algorithm.
- Process P2 is selected first as P2 is the process with the highest priority. P2 begins running at time 0. Process P2 finishes running at time 1.
- Process P3 is selected next as P3 has the next highest priority. Process P3 begins to run at time 1 and finishes at time 6. Process P1 then starts at time 6 and ends at time 16.
- Process P4 the lowest priority, therefore P4 is scheduled last and runs at time 16. Process P4 finishes running at time 17.
Priorities can be defined either internally or externally.
Priority scheduling can be either preemptive or nonpreemptive.
A major problem with priority scheduling algorithms is indefinite blocking, or starvation. A process that is ready to run but waiting for the CPU can be considered blocked. A priority scheduling algorithm can leave some low-priority processes waiting indefinitely. In a heavily loaded computer system, a steady stream of higher-priority processes can prevent a low-priority process from ever getting the CPU.
A solution to the problem of indefinite blockage of low-priority processes is aging. Aging involves gradually increasing the priority of processes that wait in the system for a long time.
Multilevel queue scheduling
With both priority and round-robin scheduling, all processes may be placed in a single queue, and the scheduler then selects the process with the highest priority to run. Depending on how the queues are managed, an O(n) search may be necessary to determine the highest-priority process. In practice, it is often easier to have separate queues for each distinct priority, and priority scheduling simply schedules the process in the highest-priority queue.
Separate Queues for each priority
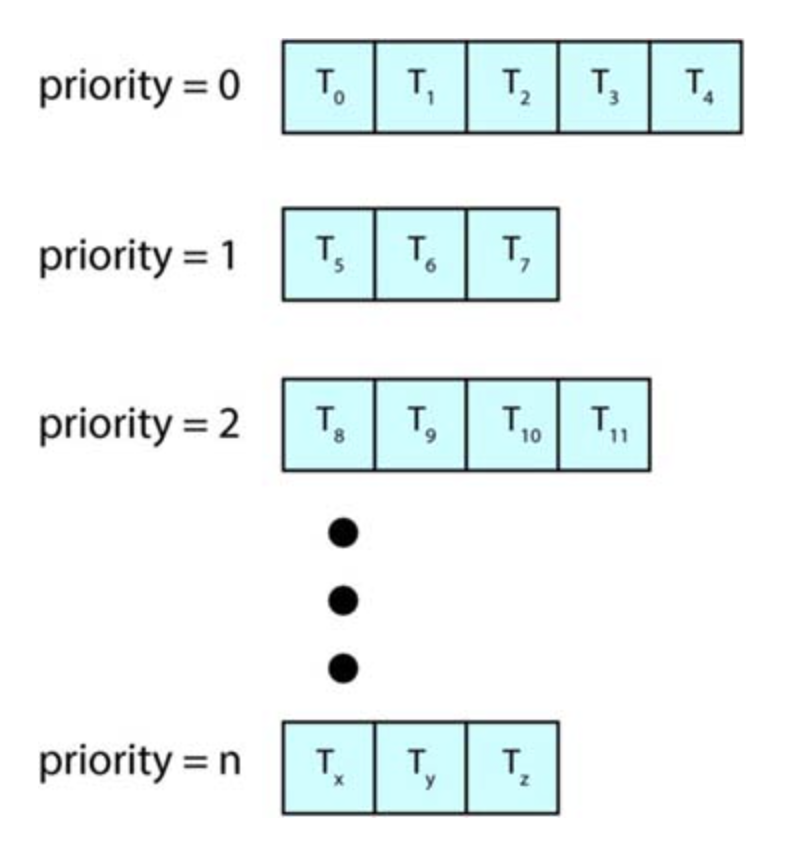
A multilevel queue scheduling algorithm can also be used to partition processes into several separate queues based on the process type, for example, foreground(interactive) and background(batch) processes
Multilevel queue scheduling
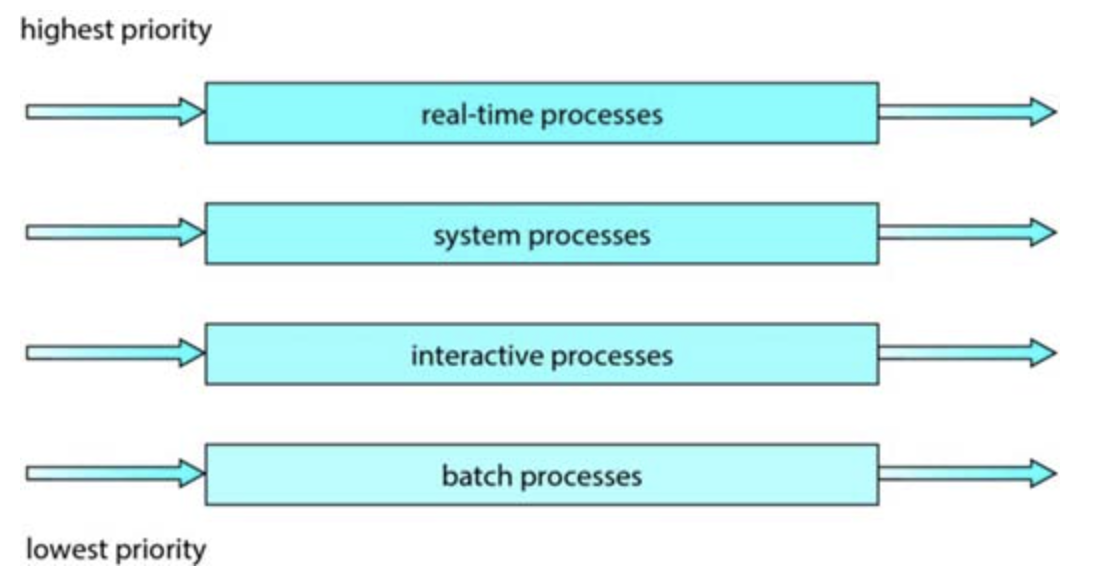
Multilevel feedback queue
The multilevel feedback queue allows a process to move between queues. Separate processes according to characteristics of CPU bursts. If a process uses too much CPU time, it's priority is lowered.
Multilevel feedback queues
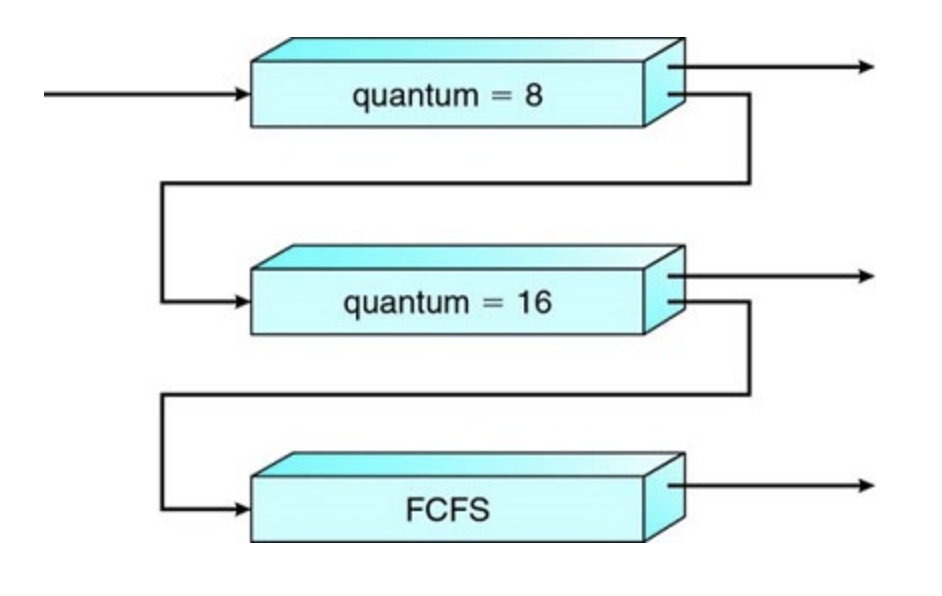
An entering process is put in queue 0. A process in queue 0 is given a time quantum of 8 milliseconds. If it does not finish within this time, it is moved to the tail of queue 1. If queue 0 is empty, the process at the head of queue 1 is given a quantum of 16 milliseconds. If it does not complete, it is preempted and is put into queue 2. Processes in queue 2 are run on an FCFS basis but are run only when queues 0 and 1 are empty.
5.4 Thread Scheduling
Contention Scope
process-contention scope(PCS): Competition for the CPU takes place among threads belonging to the same process
system-contention scope (SCS): The kernel decides which kernel level thread to schedule onto a CPU, Competition for the CPU with SCS scheduling takes place among all threads in the system.
5.5 Multi-processor scheduling
If multiple CPUs are available, load sharing, where multiple threads may run in parallel, becomes possible, however scheduling issues become correspondingly more complex.
multiprocessor now applies to the following system architectures:
- Multicore CPUs
- Multithreaded cores
- NUMA systems
- Heterogeneous multiprocessing
Approaches to multi-processor scheduling
One approach to CPU scheduling in a multiprocessor system has all scheduling decisions, I/O processing, and other system activities handled by a single processor — the main server. Remaining processors execute user code. This is known as asymmetric multiprocessing
The CPU with the scheduler may become the bottleneck
The standard approach for supporting multiprocessors is symmetric multiprocessing (SMP), where each processor is self-scheduling.
the scheduler for each processor examines the ready queue and selects a thread to run. Note that this provides two possible strategies for organizing the threads eligible to be scheduled:
- All threads may be in a common ready queue.
- Each processor may have its own private queue of threads.
If we select the first option, we have a possible race condition on the shared ready queue and therefore must ensure that two separate processors do not choose to schedule the same thread and that threads are not lost from the queue.
The second option permits each processor to schedule threads from its private run queue and therefore does not suffer from the possible performance problems associated with a shared run queue.
Organization of ready queues
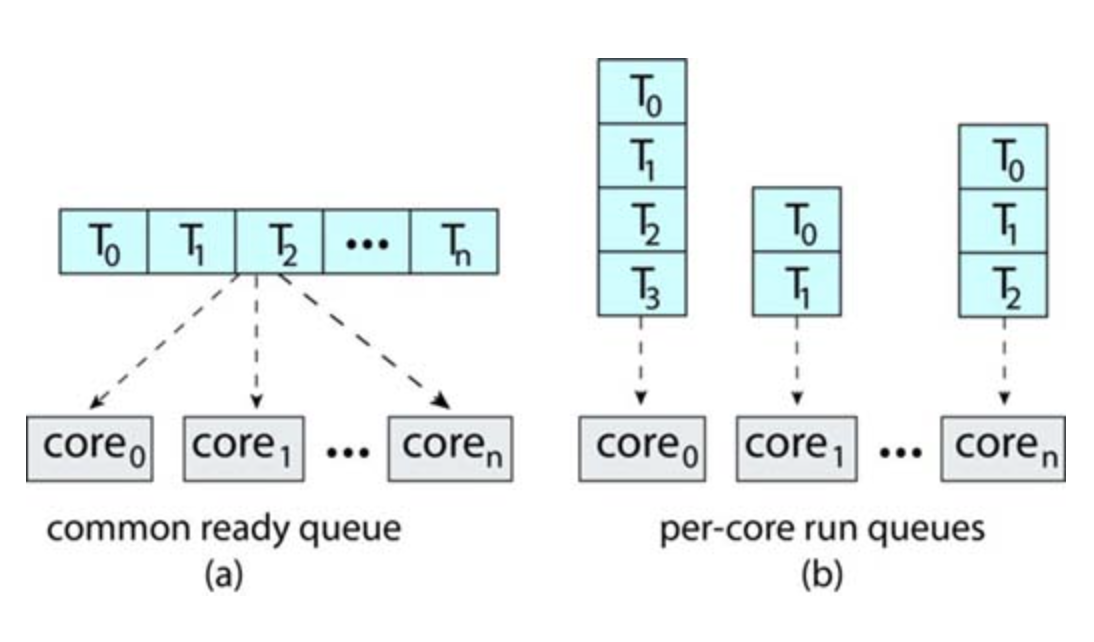
Virtually all modern operating systems support SMP
Multicore Processors
Most contemporary computer hardware now places multiple computing cores on the same physical chip, resulting in a multicore processor. Each core maintains its architectural state and thus appears to the operating system to be a separate logical CPU. SMP systems that use multicore processors are faster and consume less power than systems in which each CPU has its own physical chip.
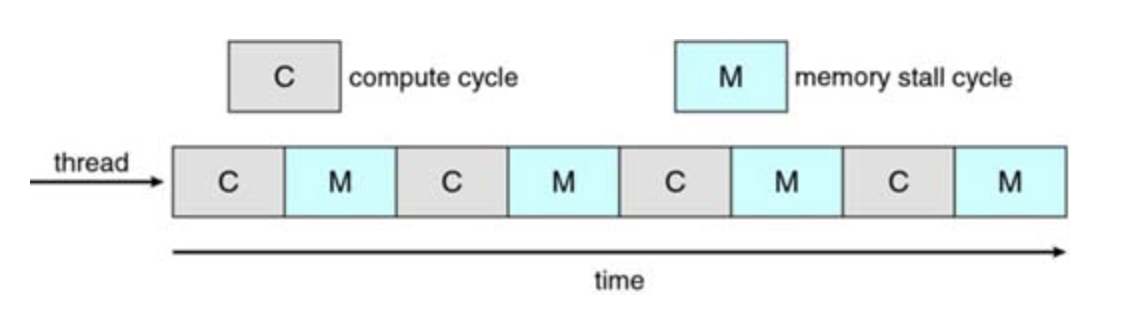
memory stall, when a processor spends a significant amount of time waiting on data to become available, happens because modern processors are much faster than memory
Memory Stall
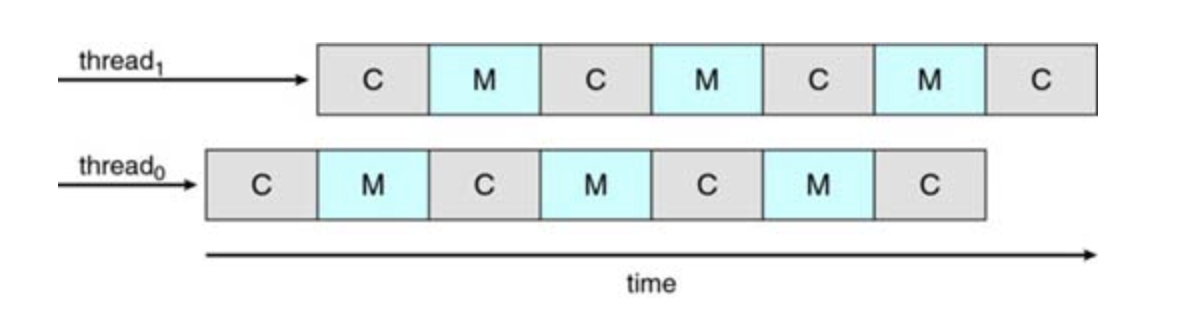
To solve for memory stall, most modern hardware uses two or more hardware threads. If one hardware thread stalls, the core can switch to another thread
From an operating system perspective, each hardware thread maintains its architectural state, such as instruction pointer and register set, and thus appears as a logical CPU that is available to run a software thread. This technique—is known as chip multithreading
Multithreaded multicore system
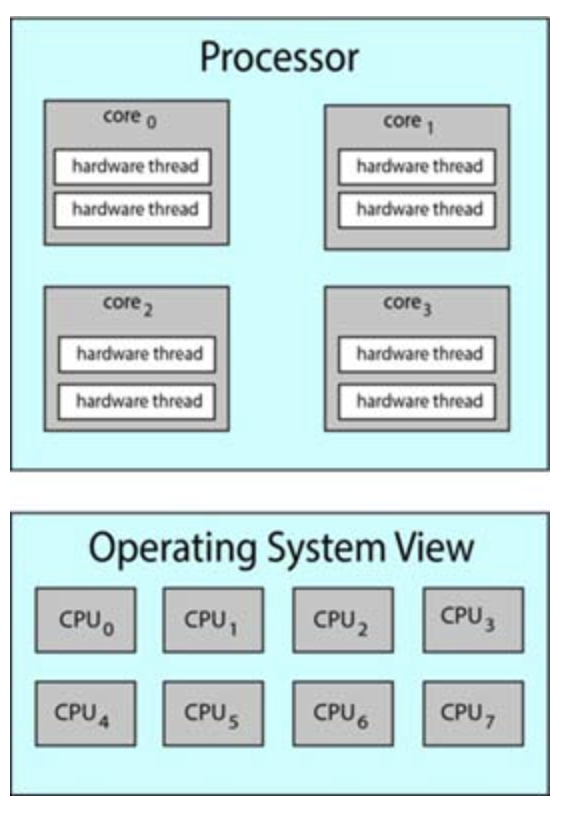
Intel processors use the term hyper-threading (simultaneous multithreading)
There are generally two ways to multithread a core:
Coarse-grained: a thread executes on a core until a long-latency event such as a memory stall occurs - Higher switching cost
Fine-grained: switches between threads at a much finer level of granulairy, typically the boundary of an instruction cycle - lower switching cost
Resources of a core are shared among hardware threads, so a core can only execute one thread at a time. Therefore, a multithreaded multicore processor requires two levels of scheduling.
Two levels of scheduling
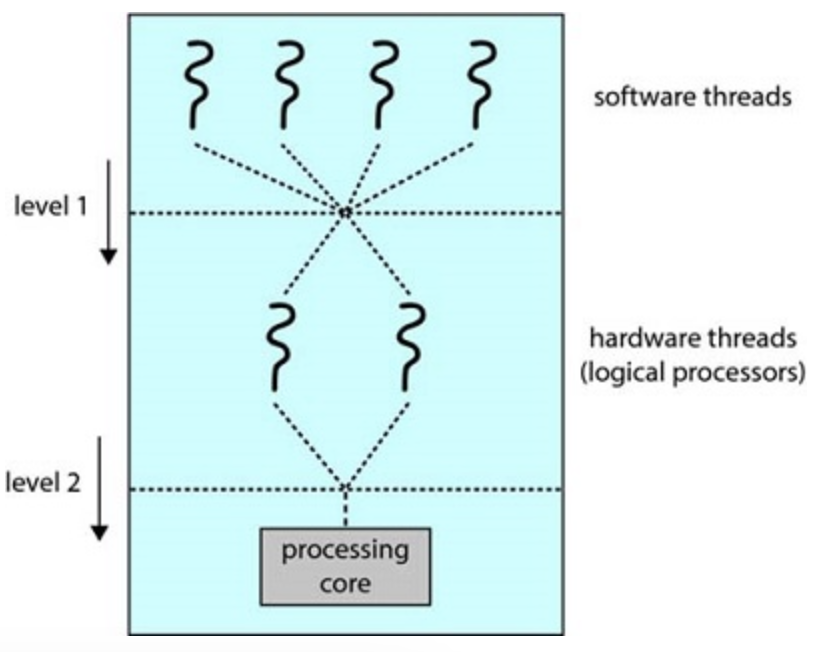
One level are operating system scheduling decisions that choose the software thread to run on each thread.
The second level specifies how each core decides which hardware thread to run. One approach is a round robin algo to schedule a hardware thread on the processing core., another is to assign each hw thread an urgency value.
Load Balancing
Load balancing attempts to keep the workload evenly distributed across all processors in an SMP system.
generally only needed on systems where each processor has its own private ready queue of eligible threads to execute.
Two General Approaches
Push Migration: A specific task periodically checks the load on each processor, if unbalance found, it distributes the load.
Pull Migration: An idle processor pulls a waiting task from a busy processor.
Processor Affinity
Successive memory accesses by a thread are often satisfied by cache memory. If a thread migrates to another processor, the contents of the first processor must be cleared and moved to the second processor. This has a high cost, so most systems try to avoid migrating. This is known as processor affinity
Heterogeneous multiprocessing
some systems are now designed using cores that run the same instruction set, yet vary in terms of their clock speed and power management, including the ability to adjust the power consumption of a core to the point of idling the core. These are known as heterogeneous multiprocessing.
5.6 Real Time CPU Scheduling
Minimizing Latency
When an event occurs, the system must respond to and service it as quickly as possible. We refer to event latency as the amount of time that elapses from when an event occurs to when it is serviced
Event Latency

Two types of latencies affect the performance of real-time systems:
- Interrupt latency
- Dispatch latency
Interrupt Latency
Interrupt latency refers to the period of time from the arrival of an interrupt at the CPU to the start of the routine that services the interrupt.
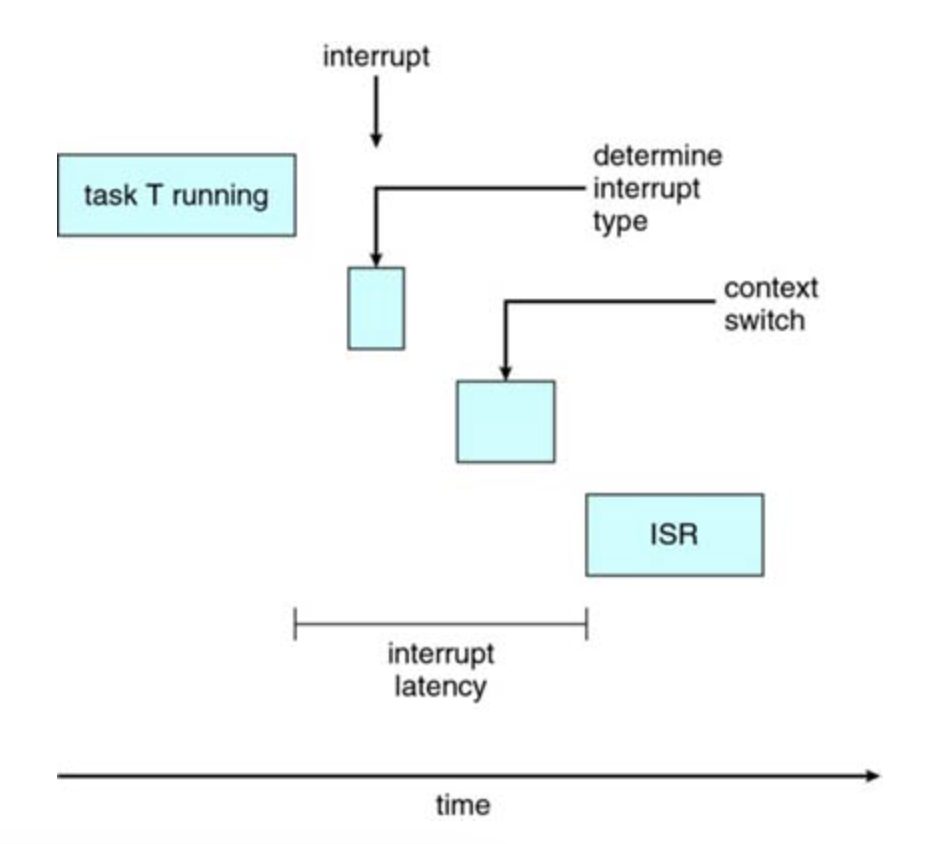
Dispatch Latency
The amount of time required for the scheduling dispatcher to stop one process and start another is known as dispatch latency.
The conflict phase of dispatch latency has two components:
- Preemption of any process running in the kernel
- Release by low-priority processes of resources needed by a high-priority process
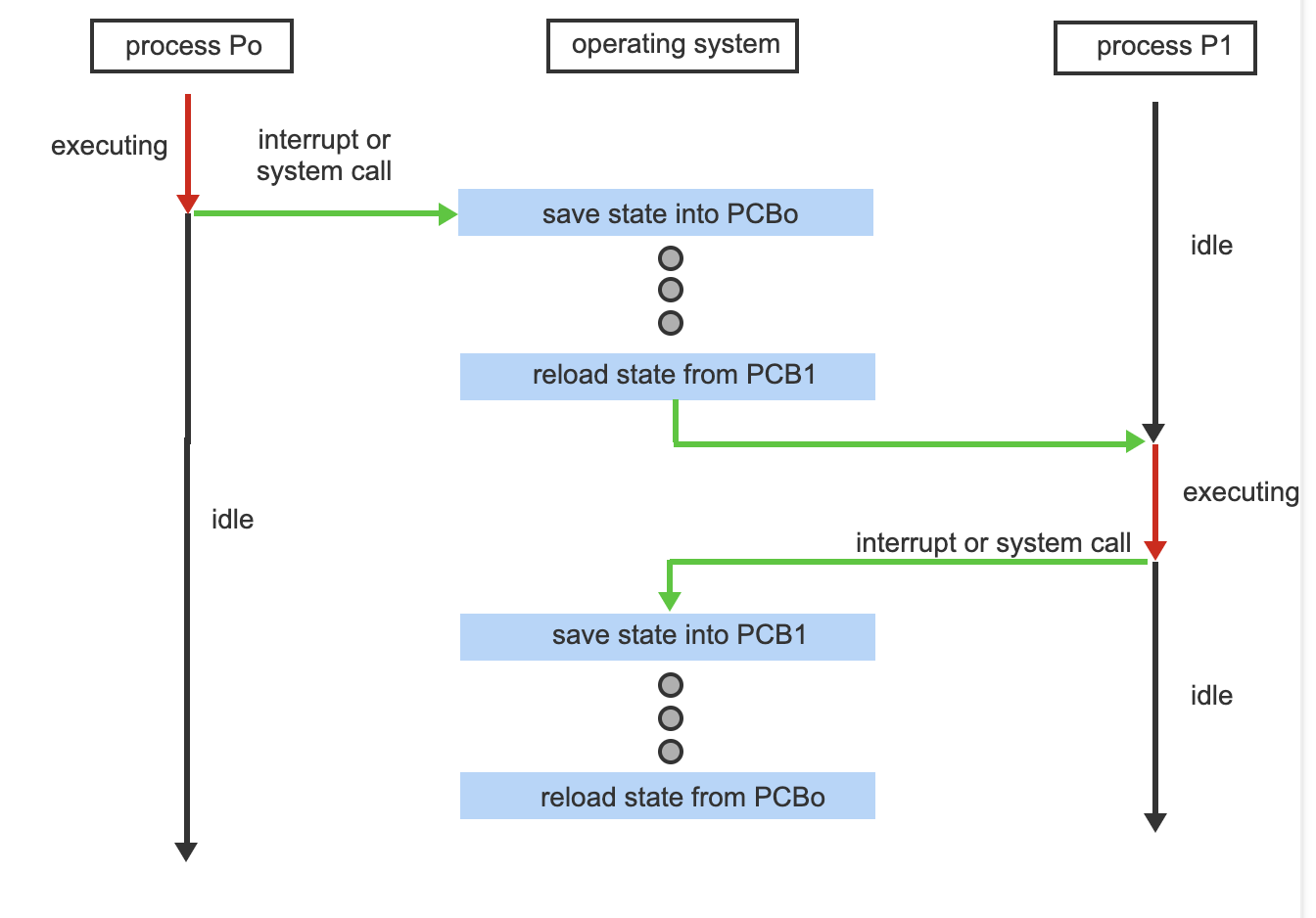
- The system has two processes, P0 and P1; P1 is idle, P0 is executing and executes a system call or the system receives an interrupt the operating system saves the state of P0 in its PCB.
- P0 is now off core, so idle, and the operating system restores the state of P1 from its PCB puts P1 on the core and it continues execution.
- P1 execution is interrupted, the operating system saves its state to its PCB and restores the next process's state (P0 in this case) to prepare it to continue execution.
- The operating system puts P0 onto the core, continuing its execution while P1 is now idle, in ready state, waiting its turn.
Priority Based Scheduling
Periodic Task
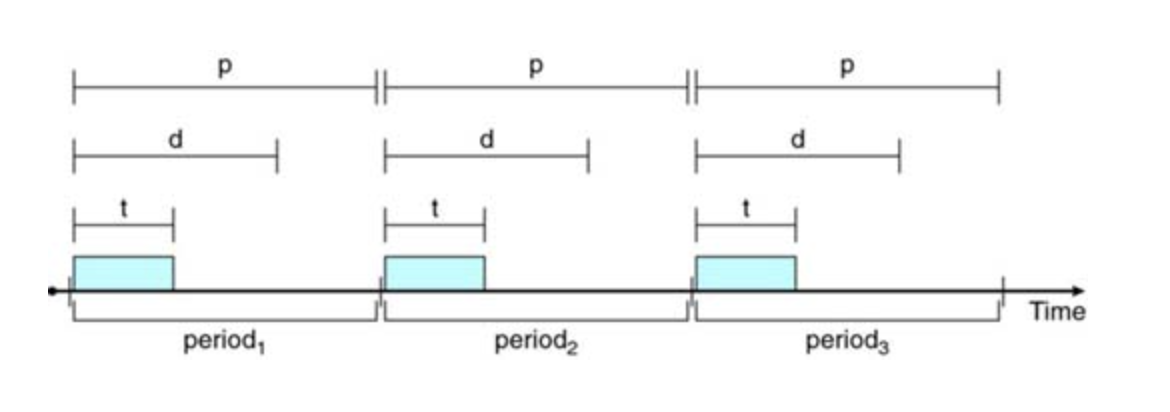
Periodic Process require the CPU at constant intervals (periods). Once a periodic process has acquired the CPU, it has a fixed processing time t, a deadline d by which it must be serviced by the CPU, and a period p.
Rate-monotic scheduling
The rate-monotonic scheduling algorithm schedules periodic tasks using a static priority policy with preemption. If a lower-priority process is running and a higher-priority process becomes available to run, it will preempt the lower-priority process.
Scheduling of tasks when P2 has a higher priority than P1.
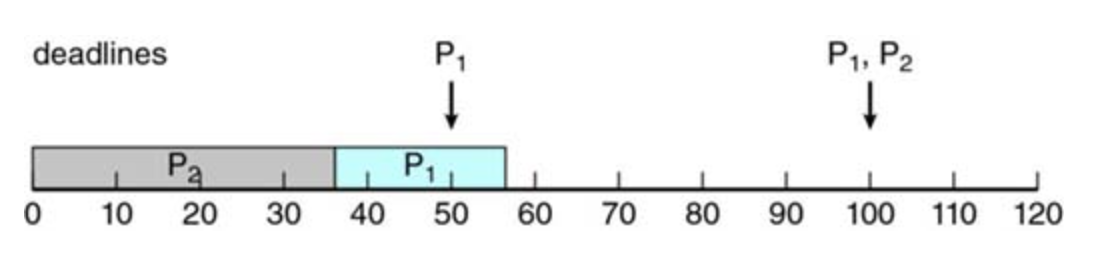
Rate-monotonic Scheduling
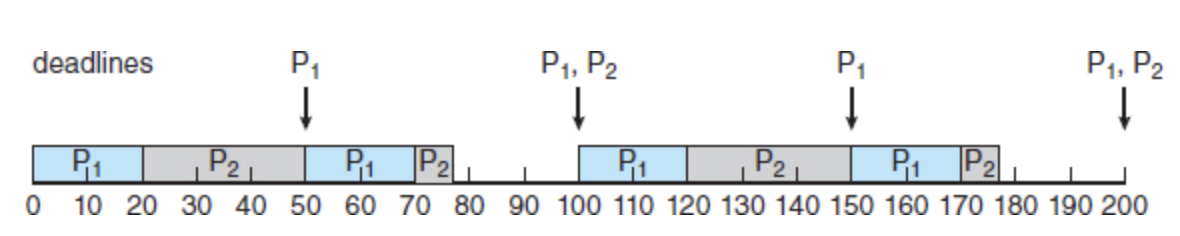
Missing deadlines with rate-monotonic scheduling

Earliest-deadline-first scheduling
Earliest-deadline-first (EDF) scheduling assigns priorities dynamically according to deadline.
Proportional Share Scheduling
Proportional share schedulers operate by allocating T shares among all applications.
5.7 Examples
5.8 Algorithm Evaluation
To select an algorithm, we must first define the relative importance of these elements. Our criteria may include several measures, such as these:
- Maximizing CPU utilization under the constraint that the maximum response time is 300 milliseconds
- Maximizing throughput such that turnaround time is (on average) linearly proportional to total execution time
Deterministic modeling
Analytic evaluation uses the given algorithm and the system workload to produce a formula or number to evaluate the performance of the algorithm for that workload.
Deterministic modeling is one type of analytic evaluation. This method takes a particular predetermined workload and defines the performance of each algorithm for that workload.
Queueing Models
The computer system is described as a network of servers. Each server has a queue of waiting processes. The CPU is a server with its ready queue, as is the I/O system with its device queues. Knowing arrival rates and service rates, we can compute utilization, average queue length, average wait time, and so on. This area of study is called queueing-network analysis.
As an example, let n be the average long-term queue length (excluding the process being serviced), let W be the average waiting time in the queue, and let λ be the average arrival rate for new processes in the queue (such as three processes per second). We expect that during the time W that a process waits, λ × W new processes will arrive in the queue. If the system is in a steady state, then the number of processes leaving the queue must be equal to the number of processes that arrive. This is known as Little's Formula
Simulations
To get a more accurate evaluation of scheduling algorithms, we can use simulations. Running simulations involves programming a model of the computer system. Software data structures represent the major components of the system.
Evaluation of CPU Schedulers by Simulation
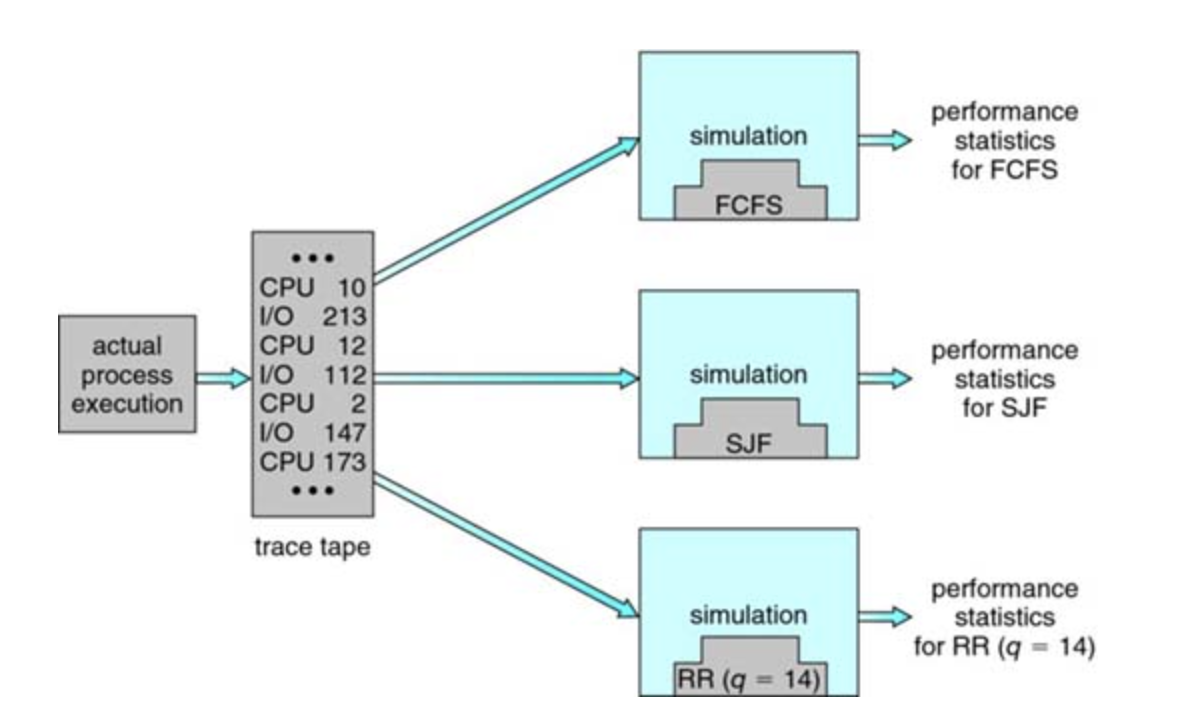
Implementation
The only completely accurate way to evaluate a scheduling algorithm is to code it up, put it in the operating system, and see how it works.
Regression testing confirms that the changes haven't made anything worse, and haven't caused new bugs or caused old bugs to be recreated