CSS 430 Chapter 2 Operating-System Structures
Chapter Objectives
- Identify services provided by an operating system.
- Illustrate how system calls are used to provide operating system services.
- Compare and contrast monolithic, layered, microkernel, modular, and hybrid strategies for designing operating systems.
- Illustrate the process for booting an operating system.
- Apply tools for monitoring operating system performance.
- Design and implement kernel modules for interacting with a Linux kernel.
2.1 Operating-System Services
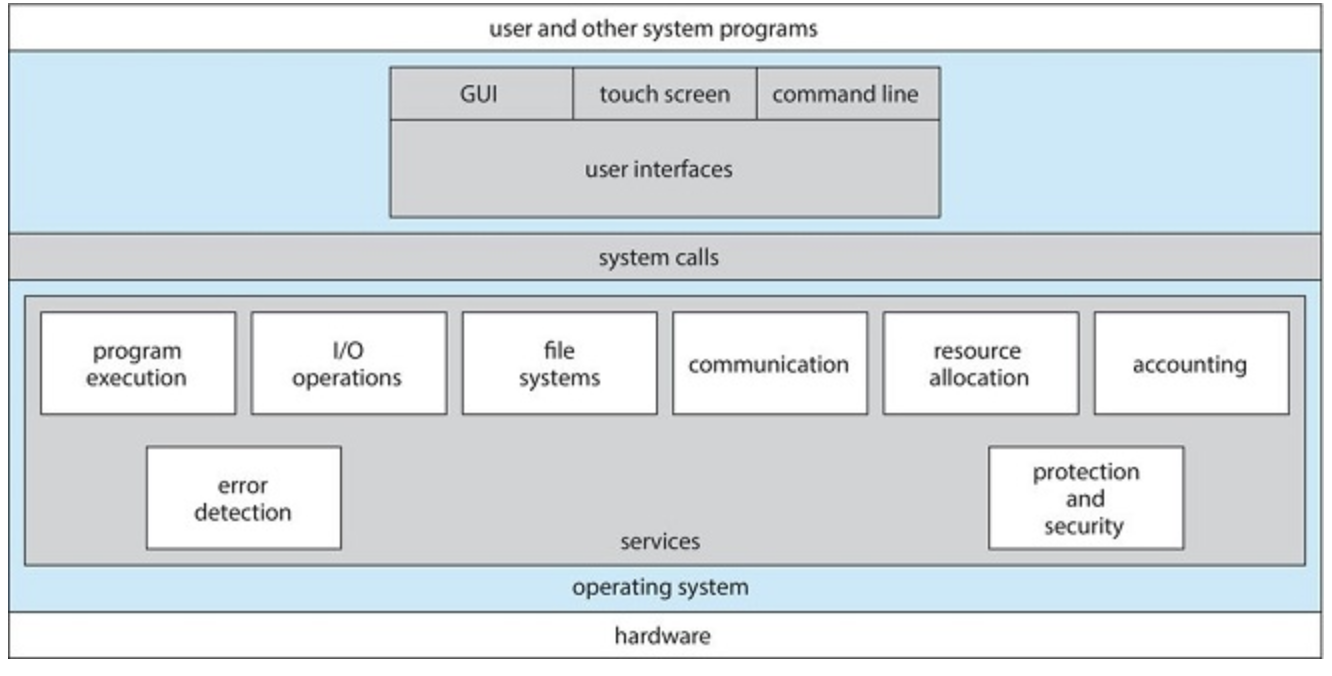
User Centric Operating System Services
- User Interface (Either GUI or CLI)
- Program Execution: The system must be able to load a program into memory and to run that program. The program must be able to end its execution, either normally or abnormally
- I/O Operations: A running program may require I/O, which may involve a file or an I/O device. For efficiency and protection, users usually cannot control I/O devices directly. Therefore, the operating system must provide a means to do I/O.
- File-system manipulation: The file system is of particular interest. Obviously, programs need to read and write files and directories. They also need to create and delete them by name, search for a given file, and list file information. Finally, some operating systems include permissions management to allow or deny access to files or directories based on file ownership.
- Communications: processes may need to exchange information. This may be implemented via shared memory (two or more processes read and write to a shared section of memory) or message passing (packets of information in predefined formats are moved between processes by the OS)
- Error detection: The OS needs to be able to detect and correct errors constantly.
OS Centric Operating System Services
- Resource allocation: The OS manages different types of resources for different processes
- Logging: We want to keep track of which programs use how much and what kinds of computer resources
- Protection and Security: Protection involves ensuring that all access to system resources is controlled.
2.2 User and Operating-System Interface
Command Interpreters
On systems with multiple command interpreters to choose from, the interpreters are known as shells.
The main function of the command interpreter is to get and execute the next user-specified command.
The command interpreter works in one of two ways.
- The command interpreter contains the code to execute the command
- The commands are implemented through programs. The interpreter does not understand the command, it just loads the program into memory and executes it
rm file.txt would search for a file called rm, load it into memory, and execute it with the parameter file.txt
2.3 System Calls
System calls provide an interface to the services made available by an operating system.
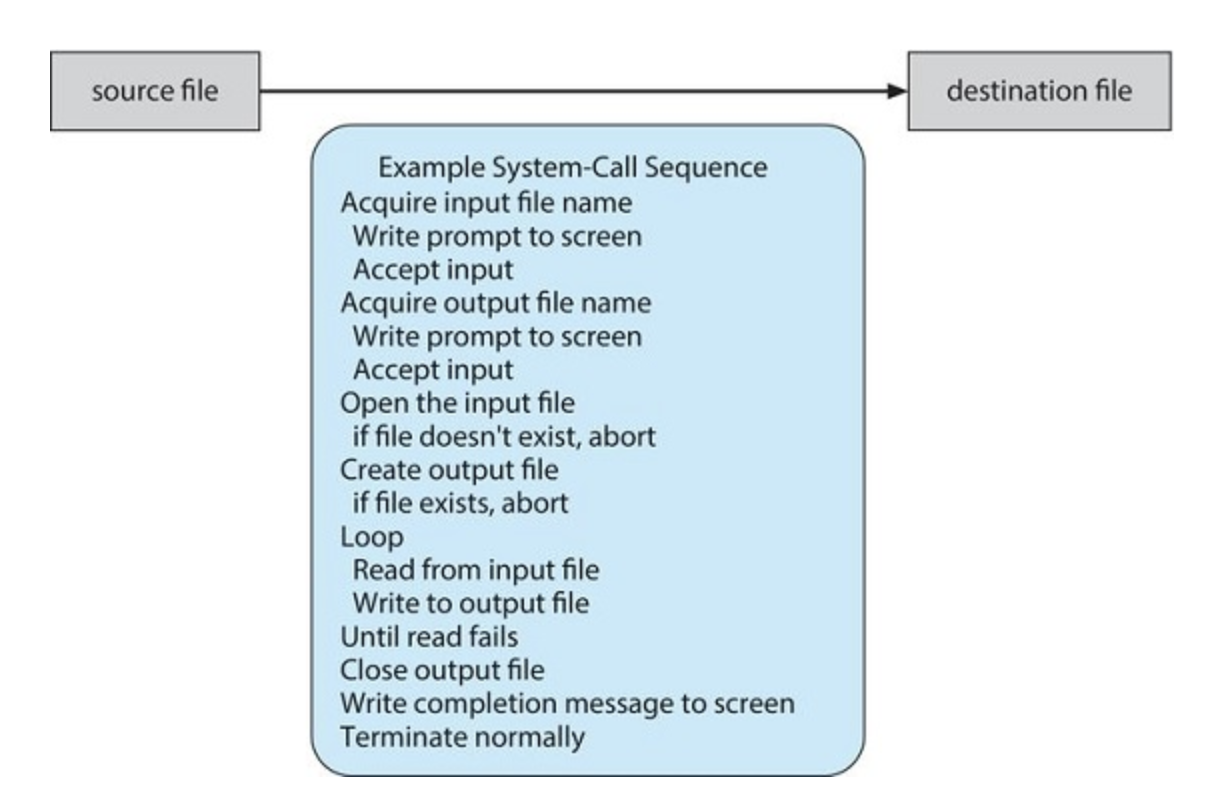
cp in.txt out.txt
This command copies the input file in.txt to the output file out.txt
Once the two file names have been obtained, the program must open the input file and create and open the output file. Each of these operations requires another system call. Possible error conditions for each system call must be handled. For example, when the program tries to open the input file, it may find that there is no file of that name or that the file is protected against access. In these cases, the program should output an error message (another sequence of system calls) and then terminate abnormally (another system call). If the input file exists, then we must create a new output file. We may find that there is already an output file with the same name. This situation may cause the program to abort (a system call), or we may delete the existing file (another system call) and create a new one (yet another system call). Another option, in an interactive system, is to ask the user (via a sequence of system calls to output the prompting message and to read the response from the terminal) whether to replace the existing file or to abort the program.
When both files are set up, we enter a loop that reads from the input file (a system call) and writes to the output file (another system call). Each read and write must return status information regarding various possible error conditions. On input, the program may find that the end of the file has been reached or that there was a hardware failure in the read (such as a parity error). The write operation may encounter various errors, depending on the output device (for example, no more available disk space).
Finally, after the entire file is copied, the program may close both files (two system calls), write a message to the console or window (more system calls), and finally terminate normally (the final system call).
Application Programming Interface
Behind the scenes, the functions that make up an API typically invoke the actual system calls on behalf of the application programmer. For example, the Windows function CreateProcess() (which, unsurprisingly, is used to create a new process) actually invokes the NTCreateProcess() system call in the Windows kernel.
Another important factor in handling system calls is the run-time environment, the RTE provides a system-call interface. The system-call interface intercepts function calls in the API and invokes the necessary system calls within the operating system.
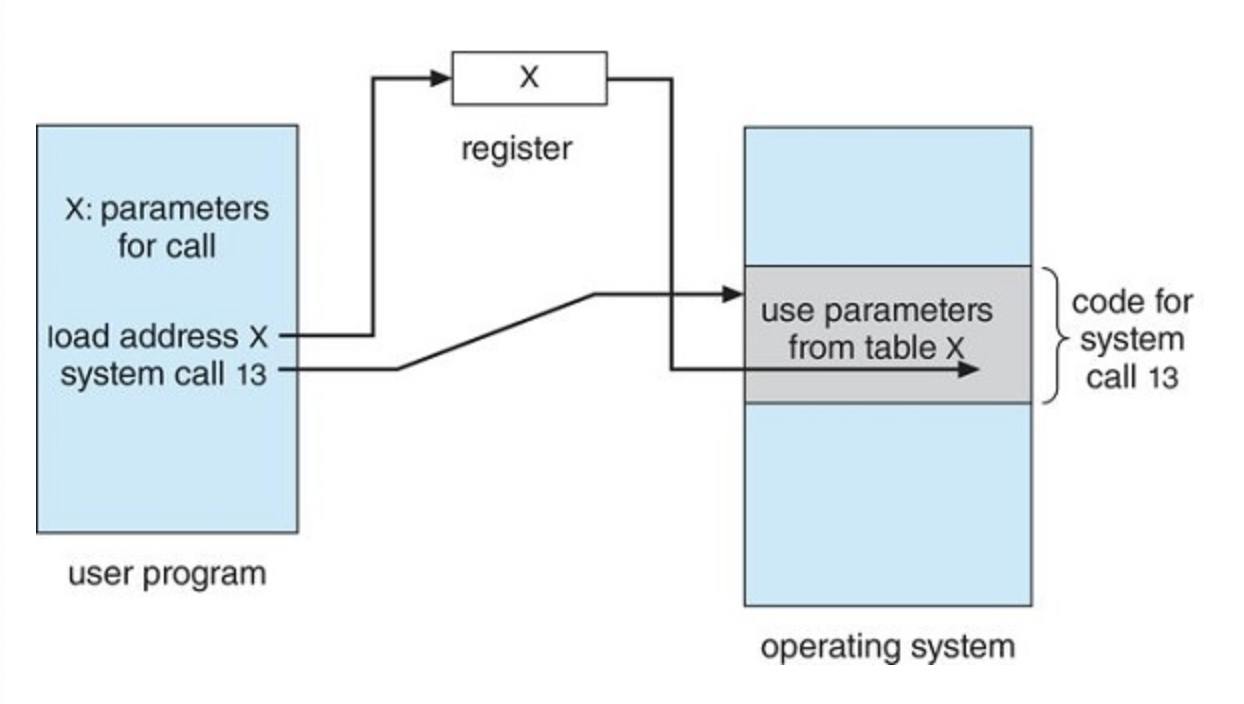
There are 3 general methods used to pass parameters to the operating system
- Passing parameters in registers(simplist)
- Storing parameters in a block or table in memory, and passing the address block to a register
- A combination of these two
Types of system calls
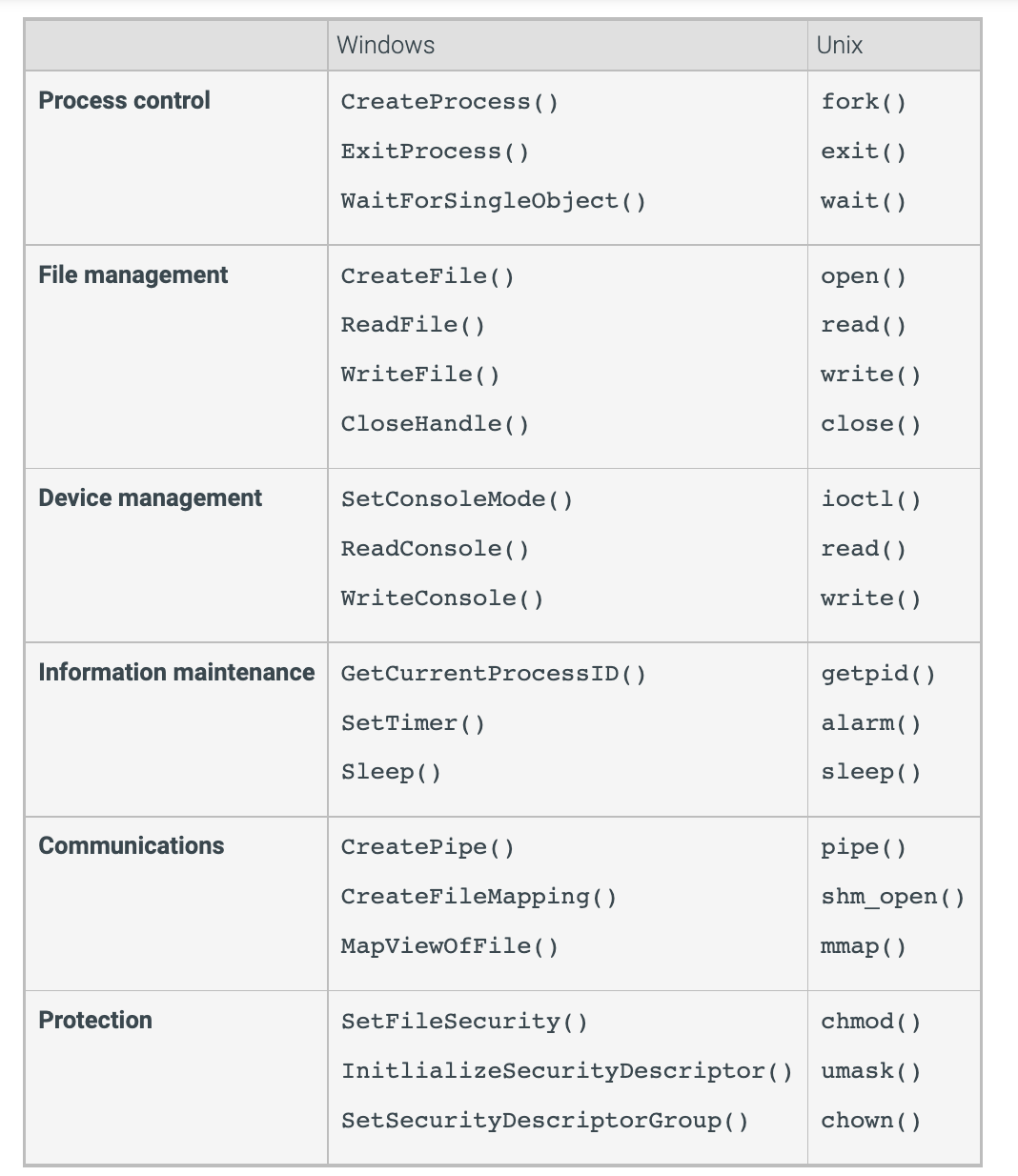
There are 6 major categories for system calls
- process control
- file management
- device management
- information maintenance
- communications
- protection

Process Control
A running program needs to be able to halt its execution either normally (end()) or abnormally (abort()).
A process executing one program may want to load() and execute() another program.
If control returns to the existing program when the new program terminates, we must save the memory image of the existing program; thus, we have effectively created a mechanism for one program to call another program. If both programs continue concurrently, we have created a new process to be multiprogrammed. Often, there is a system call specifically for this purpose (create_process()).
Quite often, two or more processes may share data. To ensure the integrity of the data being shared, operating systems often provide system calls allowing a process to lock shared data.
File Management
create(), delete(), read(), write() are just a few examples of file system calls
Device Management
A system with multiple users may require us to first request() a device, to ensure exclusive use of it. After we are finished with the device, we release() it.
Information Maintenance
Many system calls exist simply for the purpose of transferring information between the user program and the operating system.
example, time() and date().
Generally, calls are also used to get and set the process information (get_process_attributes() and set_process_attributes()).
Communication
In the message-passing model, the communicating processes exchange messages with one another to transfer information. Messages can be exchanged between the processes either directly or indirectly through a common mailbox.
For this we need a host name and a process name...as such we can use get_hostid() and get_processid()
In the shared-memory model, processes use shared_memory_create() and shared_memory_attach() system calls to create and gain access to regions of memory owned by other processes.
Protection
Protection provides a mechanism for controlling access to the resources provided by a computer system.
Typically, system calls providing protection include set_permission() and get_permission(), which manipulate the permission settings of resources such as files and disks.
2.4 System Services
In the hierarchy of computer logic, the lowest level is hardware, next is system services.
System services provide a convenient environment for program development and execution and can be divided into the following categories
- File Management
- Status information
- File modification
- Programming language support
- Program loading and execution
- Communications
- Background services
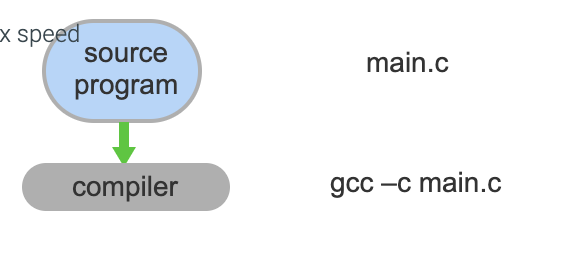
2.5 Linkers and Loaders
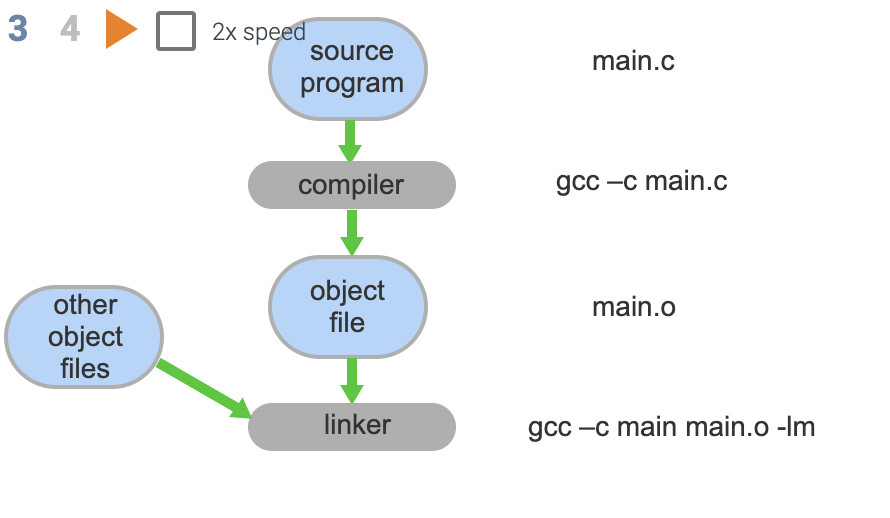
- The source program main.c is read by the C compiler gcc
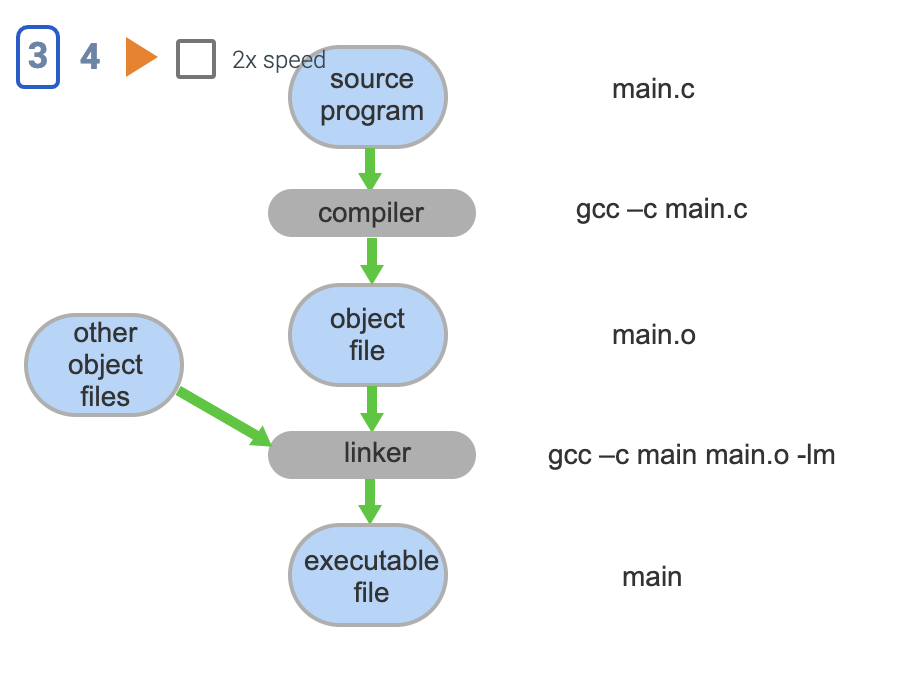
- Output is object(compiled code) which is processed by the linker which finds and merges in other objects needed by the program
- Output is an executable file ready to run
- At run time, when program is invoked, it is loaded into memory by the loader which also loads other code such as dynamically linked libraries. The addresses in the ./main process are adjusted to call the now-loaded library functions and the processes can be executed
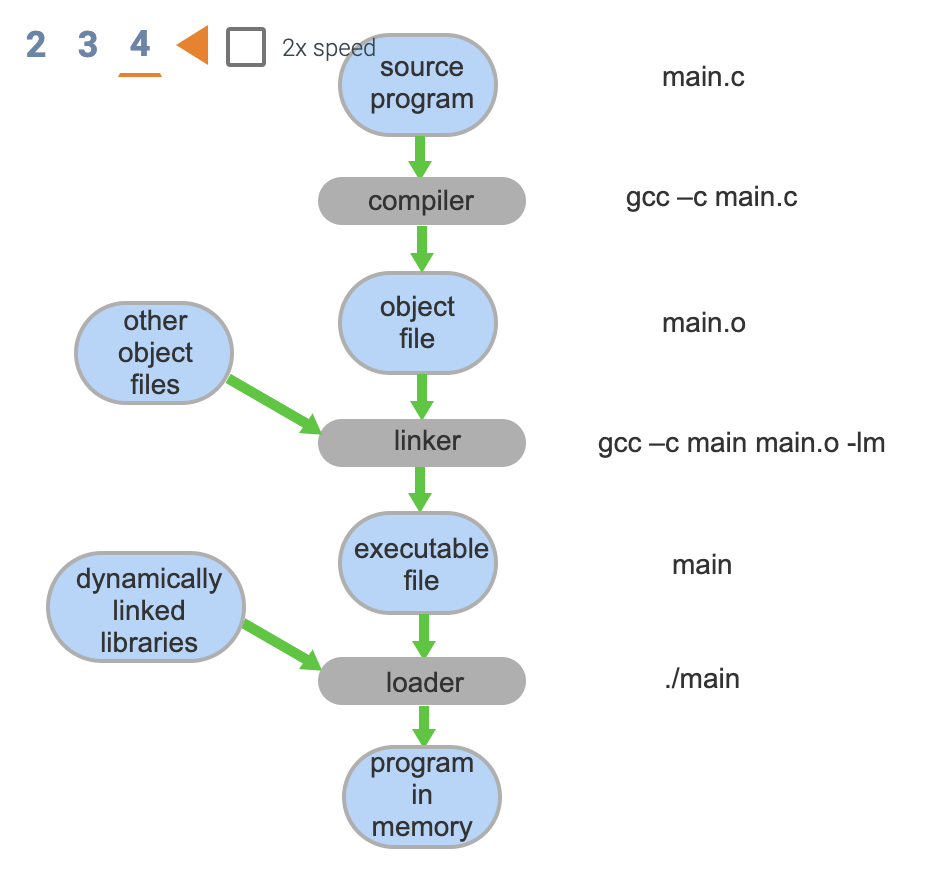
Source files are compiled into object files that are designed to be loaded into any memory location (relocatable object file)...the linker then creates an executable
The loader loads the binary executable into memory
When a program name is entered on the command line on UNIX systems—for example, ./main—the shell first creates a new process to run the program using the fork() system call. The shell then invokes the loader with the exec() system call, passing exec() the name of the executable file. The loader then loads the specified program into memory using the address space of the newly created process. (When a GUI interface is used, double-clicking on the icon associated with the executable file invokes the loader using a similar mechanism.)
DLL's or dynamically linked libraries are loaded if required during runtime
# 2.6 Why applications are operating-system specific
Since different Operating Systems have different system calls, we can run into issues with running programs. Typically this is dealt with in three ways
- The application can be written in an interpreted language (python, ruby, etc) and then the interpreter makes the system calls
- The application can be written in a language that includes a virtual machine
- The developer uses a standard language or api which generates binaries in a machine and operating system specific language.
# 2.7 Operating-system design and implementation
Design goals
Can be divided into two basic groups
- user goals
- system goals
Mechanisms and Policies
Mechanisms determine how, Policy determines what
Implementation
Once an operating system is designed, it must be implemented. Because operating systems are collections of many programs, written by many people over a long period of time, it is difficult to make general statements about how they are implemented.
Most Operating Systems are written in higher level languages such as C or C++ with small amounts of the system written in assembly language.
2.8 Operating-System Structure
Because operating systems are complex, it's not uncommon to partition a task into small components or modules rather than one single system. Think of it like separating methods and classes from a main() function.
Monolithic Structure
The simplest structure for organizing an operating system is no structure at all. That is, place all of the functionality of the kernel into a single, static binary file that runs in a single address space. This is known as a monolithic structure.
Unix
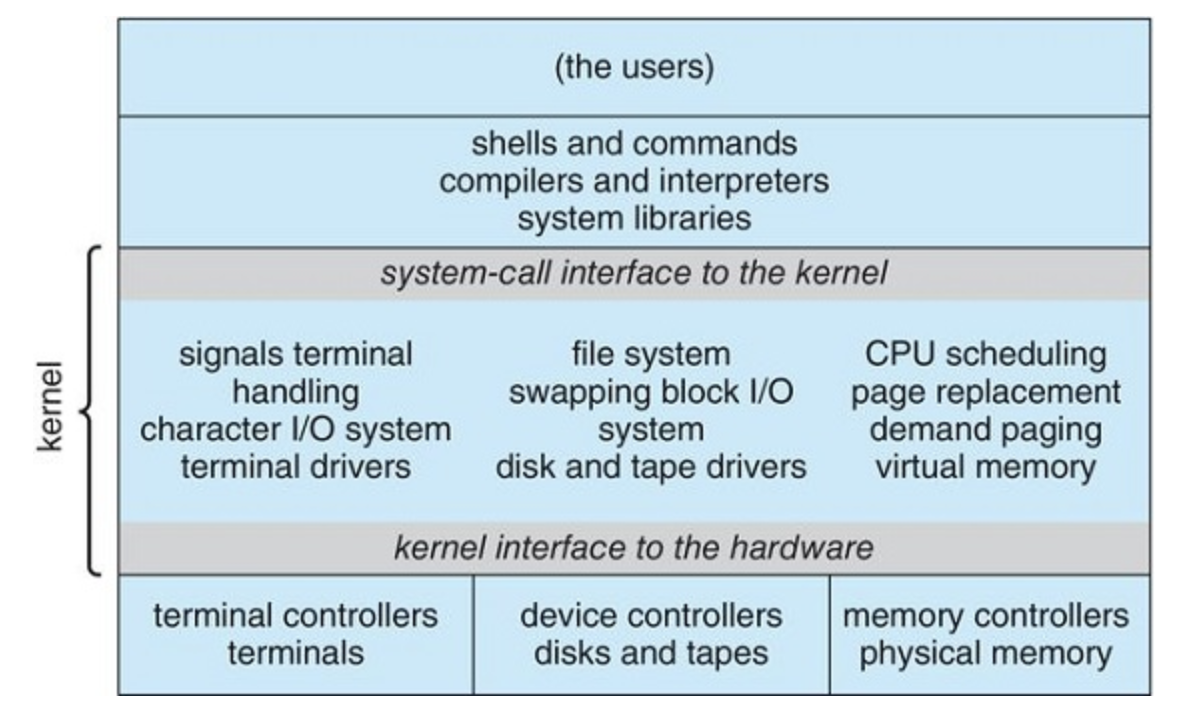
For example, the original UNIX system exted of only two parts. The Kernel and the system programs.
The kernel is then separated into interfaces and device drivers.
Everything below the system-call interface and above the physical hardware is the kernel. The kernel provides the file system, CPU scheduling, memory management, and other operating-system functions through system calls. Taken in sum, that is an enormous amount of functionality to be combined into one single address space.
Linux
Linux is derived from UNIX and is therefore structured similarly. Applications usually use the glibc library when communicating with the system call interface.
The Linux kernel is monolithic (since it runs in a single address space), however, it does have a modular design that allows for modification during run time
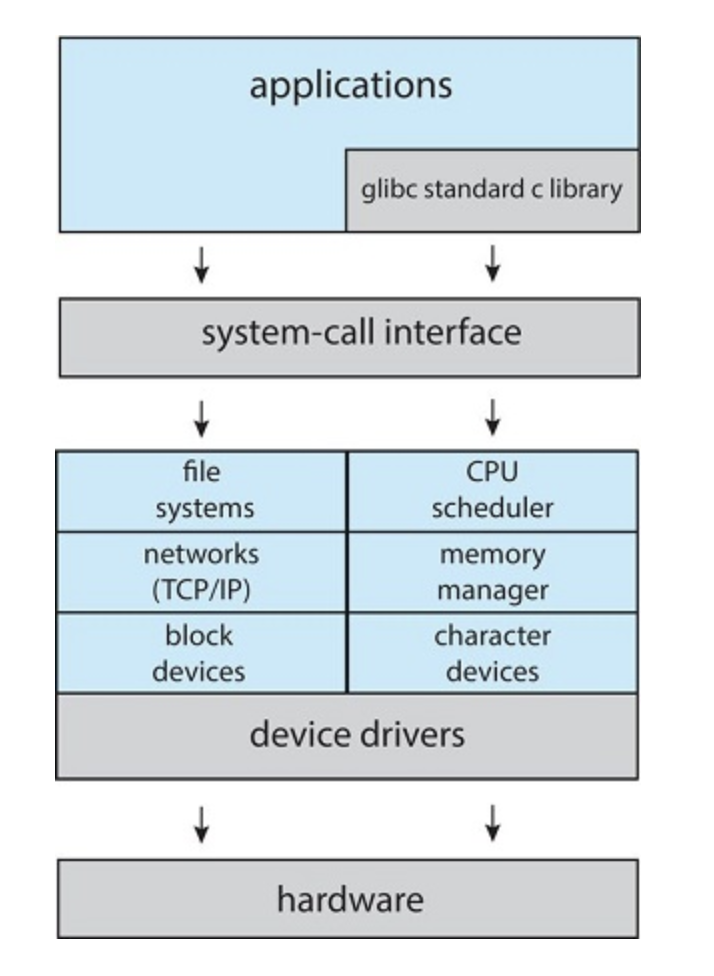
Monolithic kernels are difficult to implement and extend, however, there is little overhead in the system call interface which makes it fast. Speed is why we still see them used
Layered Approach
Monolithic kernels are generally Tightly Coupled
An alternative approach is to design a Loosely coupled system. In this style, the system is divided into components that have specific, limited functionality. When combined, these form the kernel
In a modular approach, changes to one component only affect that component.
In a layered approach, the operating system is broken into layers(or levels). The bottom most layer (0) is the hardware, the highest(N) is the UI.
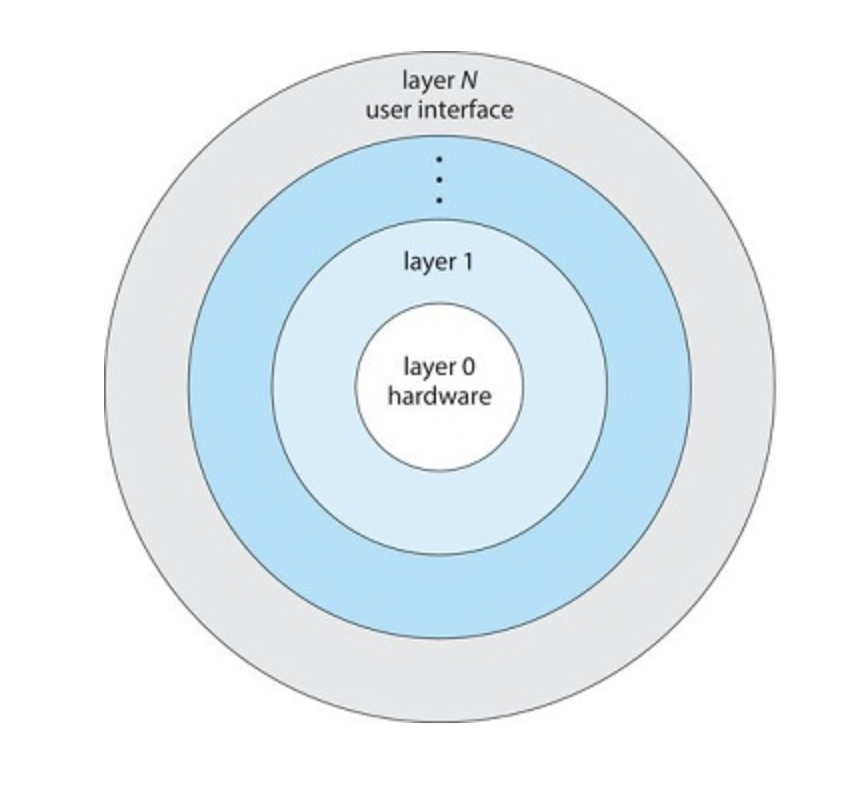
A layer is comprised of data structures and functions that can be invoked by higher level layers, and can invoke lower level layers
Each layer uses functions of lower level layers
Microkernels
This method structures the operating system by removing all nonessential components from the kernel and implements them as user level programs in separate address spaces. This creates a smaller kernel.
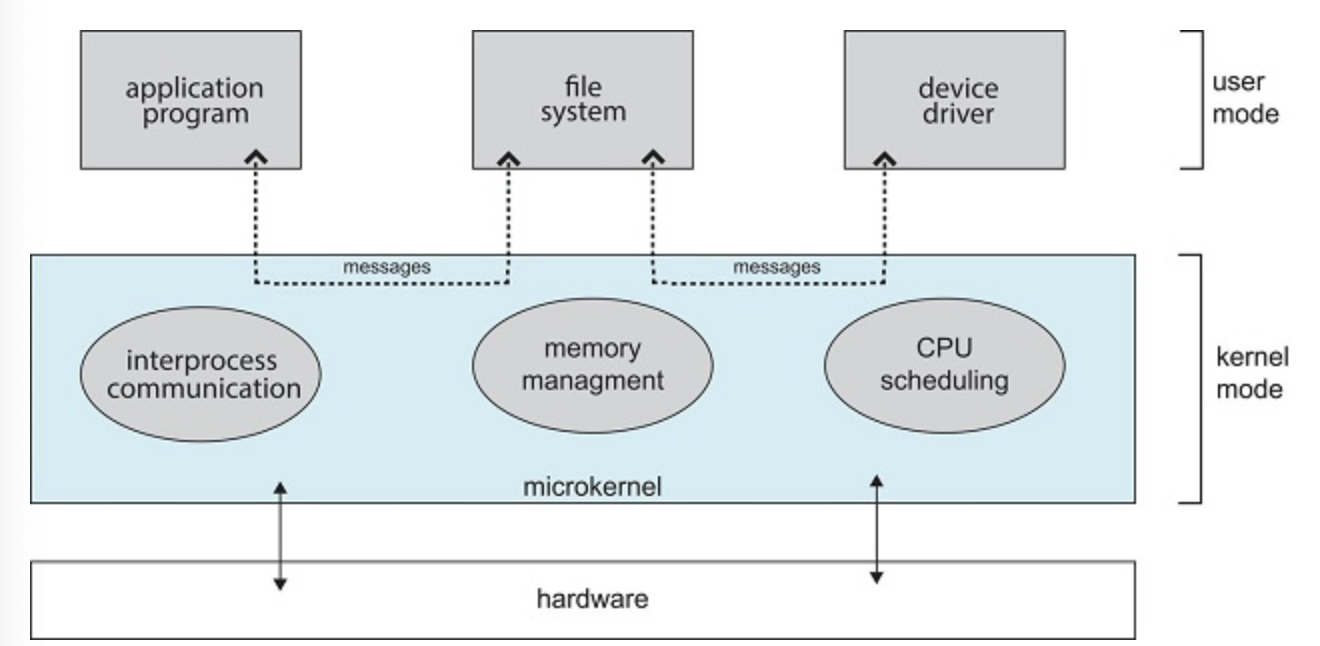
The microkernel provides communication between a client program and various services running in the user space through message passing.
Microkernels make extending the os easier, however performance can suffer due to increased function overhead
Modules
Loadable Kernel Module: the kernel has a set of core components and can link in additional services via modules either at boot time or during run time
This type of design is common in modern implementations of UNIX, such as Linux, macOS, and Solaris, as well as Windows.
The kernel provides core services, while other services are implemented dynamically as the kernel is running.
we might build CPU scheduling and memory management algorithms directly into the kernel and then add support for different file systems by way of loadable modules.
In this system, the result resembles a layered system, but it's much more flexible
Hybrid Systems
Most OS's adopt a hybrid approach
MacOS/iOS Architecture
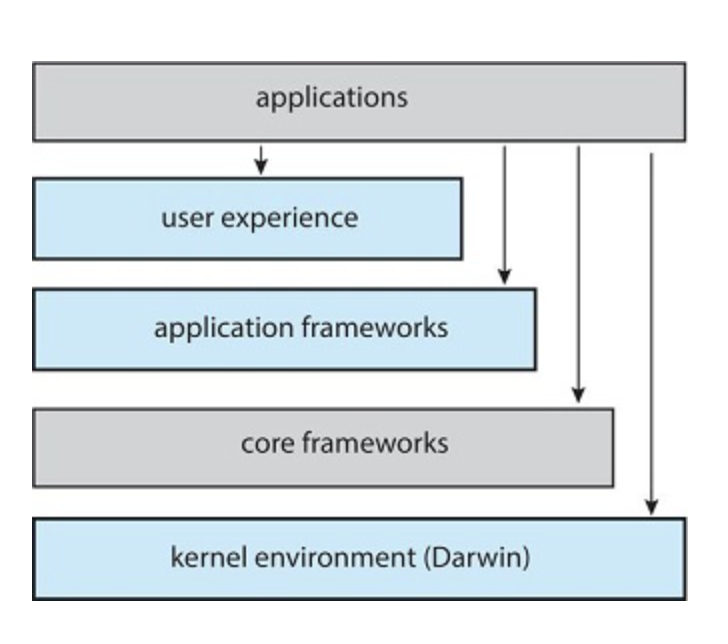
Darwin Architecture
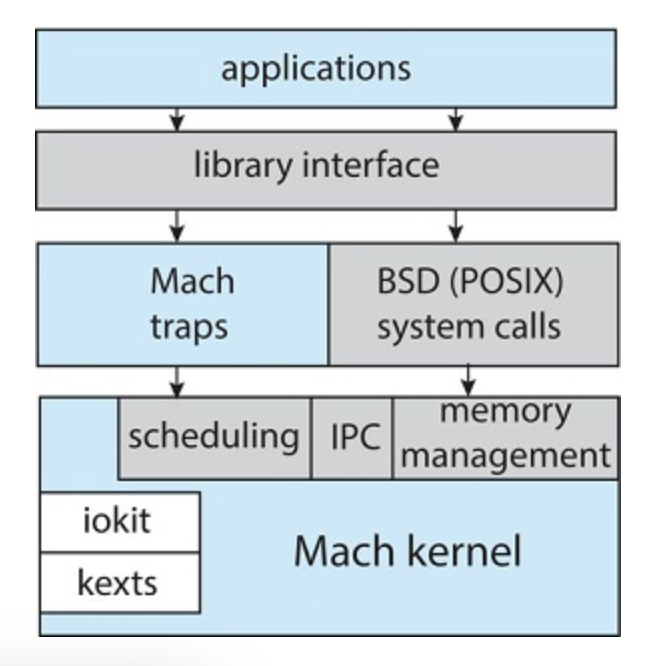
Darwin provides two system call interfaces (Mach and BSD)
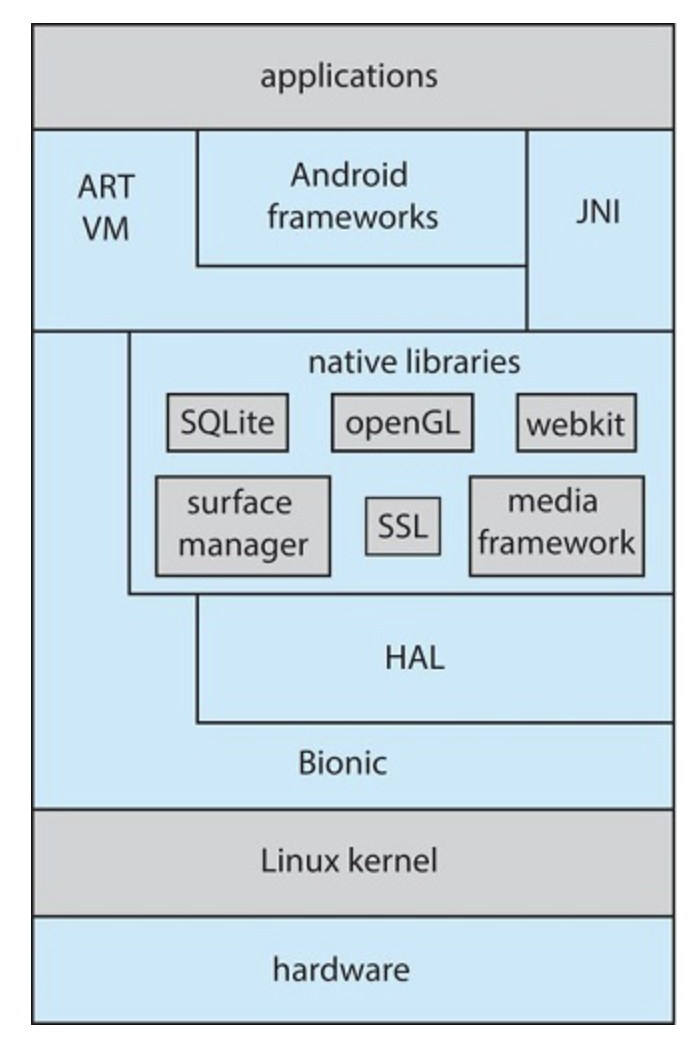
Android Architecture
2.9 Building and booting an operating system
Operating-system generation
If you are building an OS from scratch, you must follow the following steps
- Write the operating system source code (or obtain previously written source code).
- Configure the operating system for the system on which it will run.
- Compile the operating system.
- Install the operating system.
- Boot the computer and its new operating system.
System Boot
After a system is generated, it is made available for use by the hardware.
Booting: the process of starting a computer by loading the kernel. The process usually proceeds as follows
- A small piece of code known as the bootstrap program or boot loader locates the kernel.
- The kernel is loaded into memory and started.
- The kernel initializes hardware.
- The root file system is mounted.
Some computers use a nonvolatile firmware known as BIOS, this loads a second boot loader at a fixed location called a boot block.
More recently, computers have replaced BIOS with UEFI which is faster as it's a complete boot manager
In addition to loading the file containing the kernel program into memory, it also runs diagnostics to determine the state of the machine—for example, inspecting memory and the CPU and discovering devices. If the diagnostics pass, the program can continue with the booting steps. The bootstrap can also initialize all aspects of the system, from CPU registers to device controllers and the contents of main memory. Sooner or later, it starts the operating system and mounts the root file system.
GRUB is an open-source bootstrap program for Linux and UNIX
the Linux kernal image is a compressed file that is extracted after loaded into memory
# 2.10 Operating-system debugging
Failure Analysis
If a process fails, most operating systems write an error to a log file.
The operating system can also take a core dump which is a capture of the memory of the process
A failure of the kernel is called a crash
Performance monitoring and tuning
The operating system must have some means of computing and displaying measures of system behavior.
We can categorize tools as providing either per-process or system wide observations using one of two approaches, counters or tracing
Counters
Operating systems keep track of system activity through a series of counters, such as the number of system calls made or the number of operations performed to a network device or disk.
Per-process
ps- reports information for a single process or selection of processestop- reports real time stats for current processes
System-Wide
vmstat- memory usage statsnetstat- network interface statisticsiostat- I/O usage for disks
Counters generally read stats from the /proc file system that exists only in kernel memory. Each PID (process ID) is a unique int that appears as a subdirectory below /proc.
Tracing
Tracing tools collect data for a specific event
Per-process
strace- traces calls invoked by a processgdb- a source level debugger
System-wide
perf- a collection of performance toolstcpdump- collects network packets