CSS 430 Discussion Questions
1
Which of the following instructions should be privileged?
- Set value of timer. - Privileged (Setting the value of a timer involves timer management, which makes the instruction privileged)
- Read the clock.
- Clear memory. - Privileged
(If an entire memory space is cleared, this is privileged. However, a user space can be cleared with bzero( ) by her/himself.) - Issue a trap instruction. - Privileged
- Turn off interrupts. - Privileged - (Turning of interrupts is a form of Interrupt management
- Modify entries in device-status table) Need to be privileged.
- Access I/O device. - Privileged
Question: Some computer systems do not provide a privileged mode of operation in hardware. Is it possible to construct a secure operating system for these computer systems? Give arguments both that it is and that it is not possible.
Possible
It is possible to construct a secure OS for computer systems that do NOT have a privileged mode of operation in hardware. To do so, you’ll need a way to distinguish between a User and Privileged mode of operation with being able to interface directly with the hardware. In order to accomplish that, an emulator can be created to mimic the hardware components. Once the emulator is running, an OS can be placed on top of that in order to simulate User (Non-privileged) and Kernel (Privileged) mode.
Not Possible
On the other hand, it might not be possible to construct a secure OS for computer systems that do NOT have a privileged mode of operation in hardware because in order for the OS to transfer between User and Kernel Mode (perform Dual Mode Operation), the OS needs to check if the Timer is set to interrupt. However, the Timer is hardware so by not having privileged access to hardware it would not be possible to securely check if this value is true or not.
Additionally, if a user is able to find a vulnerability in the emulator, they may be able to exploit the emulated version of the Timer in order to gain access to Kernel Mode. It is possible that the user can also find a vulnerability and execute malicious code to get root access.
Good. Also, memory space can be distinguished between user and kernel.
What is the purpose of interrupts? How does an interrupt differ from a trap? Can traps be generated intentionally by a user program? If so, for what purpose?
The purpose of interrupts is to indicate hardware change that requires immediate attention. They differ from traps in the sense that interrupts tend to be implemented through hardware where as traps are generally software interrupts raised by the Operating system. Traps can be intentionally triggered by a user program but I don’t think they can be created by them. An example would be a trap to detect an error state in a program. Example of an interrupt would be a controller informing the system that it has completed a task.
Discussion item 2: Early computers did not have interrupts, timers, and/or privileged instructions. What features was the OS unable to facilitate?
Without interrupts, timers, and/or privileged instructions, the OS would be unable to facilitate stopping any running programming and would end up running for an infinite amount of time, causing the CPU to not be able to run any other operating systems. Essentially, the CPU loses control over the operating system due to buggy processes that had already been started. Additionally, without the definition of privileged instructions, the users would be able to have too much fine tuned control over things like memory, which in today’s processes, would violate memory access control. Additionally, without interrupts, the CPU, in addition to the user would not have access to helpful interrupt vectors which, in today’s world, the CPU would use to handle the exception properly.
Keeping in mind the various definitions of operating system, consider whether the operating system should include applications such as web browsers and mail programs. Argue both that it should and that it should not, and support your answers.
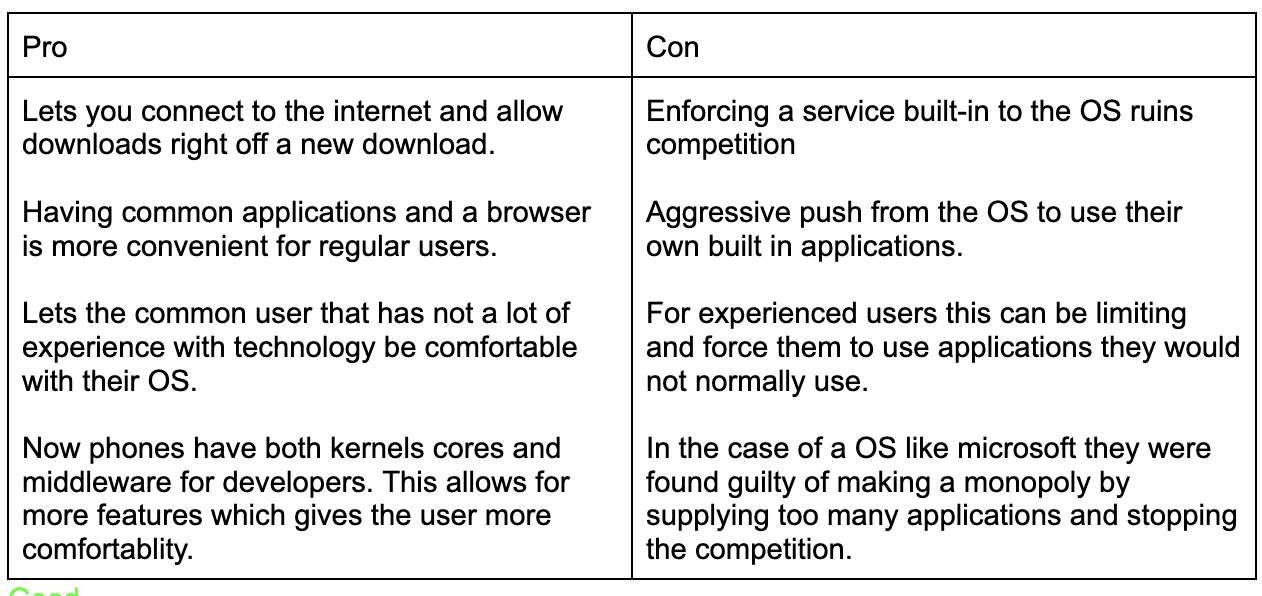
2
Mickey Mouse is an undergraduate research assistant. He received the following instruction from his advisor
- Login uw1-320-20 with our project account “project”.
- Go to the “~/src” directory.
- Compile all.cpp files into a.out.
- Check if the “project” account is running a.out in background. If so, make sure to terminate it.
- Run a.out with its priority 5 and save its standard output into the “result.txt” file.
- Archive all files under the “~/src” directory into “~/src.tar”.
- Mickey was using “uw1-320-21” with his “mickey” account before he followed this instruction. When he tried to run “a.out”, he found that the “project” account was running a.out in background and its PID was 1234.
Give a correct sequence of all Unix commands he typed to complete this instruction.
ssh project@uw1-320-20.edu
cd ~/src
g++ *.cpp
ps
kill -9 1234
nice -5 ./a.out > result.txt
tar -cvf - src > src.tar
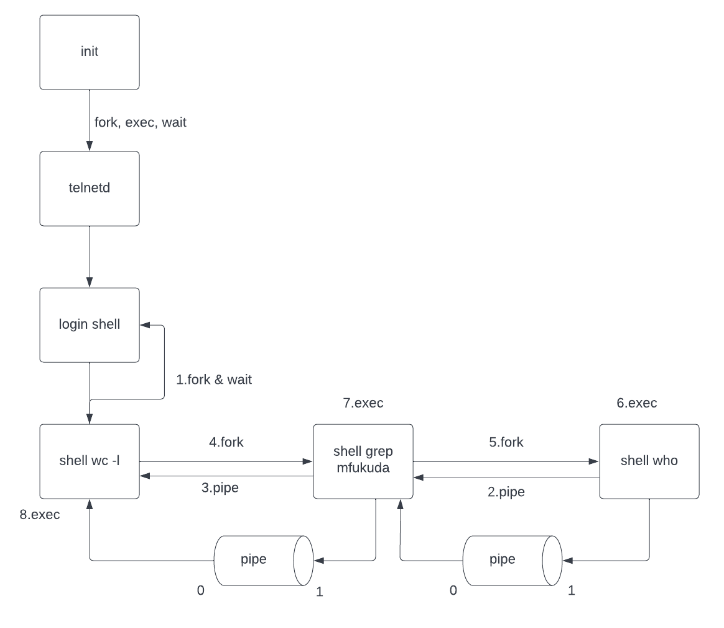
In Unix, the first process is called init. All the others are descendants of “init”. The init process spawns a telnetd process that detects a new telnet connection. Upon a new connection, telnetd spawns a login process that then overloads a shell on it when a user successfully log in the system. Now, assume that the user types who | grep mfukuda | wc –l. Draw a process tree from init to those three commands. Add fork, exec, wait, and pipe system calls between any two processes affecting each other.
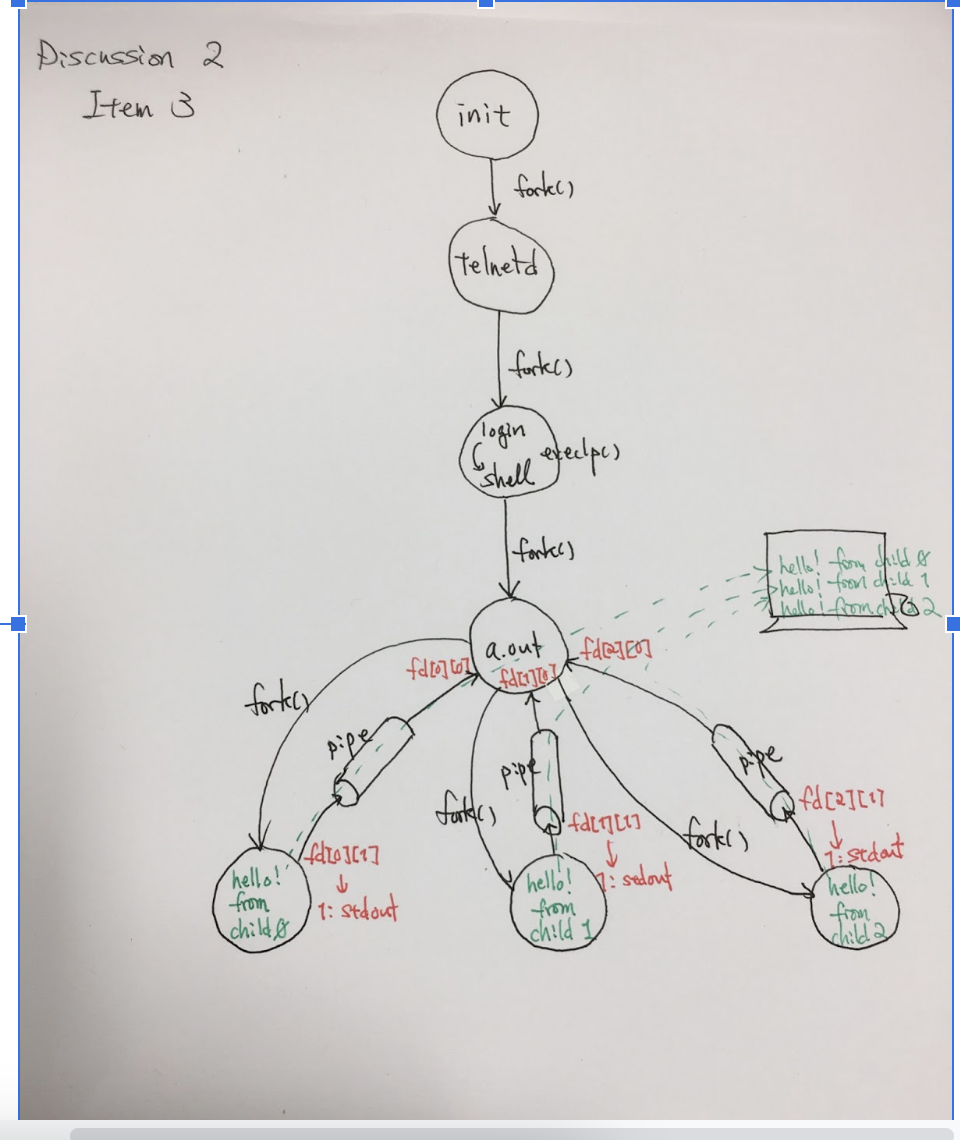
In Unix, the first process is called init. All the others are descendants of “init”. The init process spawns a telnetd process that detects a new telnet connection. Upon a new connection, telnetd spawns a login process that then overloads a shell on it when a user successfully logs in the system. Now, assume that the user has typed a.out | grep hello, where a.out is an executable file compiled from the following C++ program. Draw a process tree from init to those two programs, (i.e. a.out and grep). (Note that your tree may have more three processes.) Add fork, exec, wait, and pipe system calls between any two processes affecting each other. For each pipe, indicate its direction with an arrow, (i.e., →).
3
Using the program shown below, explain what the output will be at LINE A.
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int value = 5;
int main()
{
pid_t pid;
pid = fork();
if (pid == 0) { /* child process */
value += 15;
return 0;
}
else if (pid > 0) { /* parent process */
wait(NULL);
printf("PARENT: value = %d",value); /* LINE A */
return 0;
}
}
What output will be at Line A?
PARENT: value = 20 (when the child is successfully created)
PARENT: value = 5 (when the fork fails)
Including the initial parent process, how many processes are created by the program shown below?
#include <stdio.h>
#include <unistd.h>
int main()
{
/* fork a child process */
fork();
/* fork another child process */
fork();
/* and fork another */
fork();
return 0;
}
How many processes are created?
We are forking the created children as well
So 1 becomes 2
2 become 4
4 becomes 8 after 3 forks
8 processes
processes =
Using the program shown in the figure below, explain what the output will be at lines X and Y.
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
#define SIZE 5
int nums[SIZE] = {0,1,2,3,4};
int main()
{
int i;
pid t pid;
pid = fork(); // fork the process
if (pid == 0) { // child process
for (i = 0; i < SIZE; i++) { // size == 5
nums[i] *= -i;
printf("CHILD: %d ",nums[i]); /* LINE X */ nums[5] = {0, -1, -4, -9, -16}
}
}
else if (pid > 0) { // parent
wait(NULL);
for (i = 0; i < SIZE; i++) {
printf("PARENT: %d ",nums[i]); /* LINE Y */ nums[5] = {0, 1, 2, 3, 4}
}
return 0;
}
When a process creates a new process using the fork() operation, which of the following states is shared between the parent process and the child process?
Shared Memory Segments are the only one of the three states that is shared. The stack and heap are copied from the parent process to the newly forked child process, while the memory is still shared. The reason for this is that several processes can read/write in a particular memory segment without the need to call OS functions, which can be quite expensive.
Using the program in the figure below, identify the values of pid at lines A, B, C, and D. (Assume that the actual pids of the parent and child are 2600 and 2603, respectively.)
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
pid_t pid, pid1;
/* fork a child process */
pid = fork();
if (pid < 0) { /* error occurred */
fprintf(stderr, "Fork Failed");
return 1;
}
else if (pid == 0) { /* child process */
pid1 = getpid();
printf("child: pid = %d",pid); /* A */ 0
printf("child: pid1 = %d",pid1); /* B */ 2603
}
else { /* parent process */
pid1 = getpid();
printf("parent: pid = %d",pid); /* C */ 2603
printf("parent: pid1 = %d",pid1); /* D */ 2600
wait(NULL);
}
return 0;
}
4
Consider four different types of inter-process communication.
a)Pipe: implemented with pipe, read, and write
b)Socket: implemented with socket, read, and write
c)Shared memory: implemented shmget, shmat, and memory read/write
d)Shared message queue: implemented with msgget, msgsnd, and msgrcv
1.Which types are based on direct communication?
a) pipe
b) socket
Direct Communication links are implemented when the processes use a specific process identifier for the communication, but it is hard to identify the sender ahead of time.
2.Which types of communication do not require parent/child process relationship?
b) Socket: implemented with socket, read, and write
c) Shared memory: implemented shmget, shmat, and memory read/write
d) Shared message queue: implemented with msgget, msgsnd, and msgrcv
Pipes and sockets are types of inter-process communication (IPC) that do not require a parent-child process relationship. Shared memory and message queues can be used by unrelated processes to communicate with each other.
3.If we code a produce/consumer program, which types of communication require us to implement process synchronization? (Opposite of direct communication)
c) Shared memory: implemented shmget, shmat, and memory read/write
d) Shared message queue: implemented with msgget, msgsnd, and msgrcv
In a producer-consumer program, the producer and consumer processes share a common resource, such as a shared buffer, to communicate with each other. When using shared memory or message queues, it is necessary to implement process synchronization mechanisms, such as semaphores or mutexes, to ensure that the shared resource is accessed safely by multiple processes. This ensures that the producer and consumer processes do not overwrite or read from the shared resource simultaneously, which could lead to data corruption. Pipes and sockets do not require explicit process synchronization as they are typically implemented with buffering and flow control mechanisms that handle the synchronization between the processes.
4.Which types of communication can be used to communicate with a process running on a remote computer?
b) Socket: implemented with socket, read, and write
Sockets can be used to communicate with a process running on a remote computer. They provide a standardized interface for communication over a network, and can be used to send and receive data using various network protocols such as TCP or UDP. Pipes, Shared memory, and Shared message queues are typically used for inter-process communication (IPC) within a single machine and not to communicate over the network with a process running on a remote computer.
5.Which types of communication must use file descriptors?
a)Pipe: implemented with pipe, read, and write
b)Socket: implemented with socket, read, and write
Pipes and sockets both use file descriptors. A file descriptor is a non-negative integer that the operating system assigns to an open file or other I/O resource, such as a pipe or a socket. File descriptors are used to identify the resource when performing I/O operations, such as read and write.
Shared memory and Shared message queue can be accessed using memory addresses or queue ids, they don't use file descriptor.
6. Which types of communication need a specific data structure when transferring data?
d) Shared message queue: implemented with msgget, msgsnd, and msgrcv
Shared message queues typically use a specific data structure, known as a message, to transfer data between processes. The message structure includes a message type, which is used to identify the message, and a message body, which is the actual data being transferred. The msgsnd and msgrcv system calls are used to send and receive messages, respectively, and the msgget system call is used to create and access message queues.
Pipes, Sockets and Shared memory can be used to transfer data without any specific data structure. They transfer the data as a raw stream of bytes.
Why can threads perform their context switch much faster than processes?
Because they share the same process resources as the parent process, it’s quicker for threads to switch contexts. It does not need to restore the memory space (Good, more specifically, no need to restore TLB)
What data structure must threads carry by their own resource?
Stack, program counter, register contents
What data structure can they share?
Data, Code, Heap, files, Address space,
What are the benefits and the disadvantages of each of the following? Consider both the system level and the programmer level.
Synchronous Communication
| Benefits | Disadvantages |
|---|---|
| Faster to complete each specific task (more compute power) | Unable to perform multiple processes simultaneously |
| Simple Design | Blocking of resources which may take a longer overall time to complete certain tasks. |
| Deadlock-free | Limited fault tolerance as all the resources are being spent on one process |
| More straightforward to debug | Limited fault tolerance as all the resources are being spent on one process |
| Use-level synchronization is not needed thus User programs are simple. | Blocking may cause deadlocks., Blocking may waste time if there are many small talks. |
Asynchronous Communication
| Benefits | Disadvantages |
|---|---|
| Able to run multiple processes simultaneously (slower) | Slower because it has to split & share resources to run a certain number of processes |
| Better for real-time systems where users are interacting with several processes | More complex to design |
| Potential Deadlocks |
Fixed-sized and variable-sized messages (buffering issues)
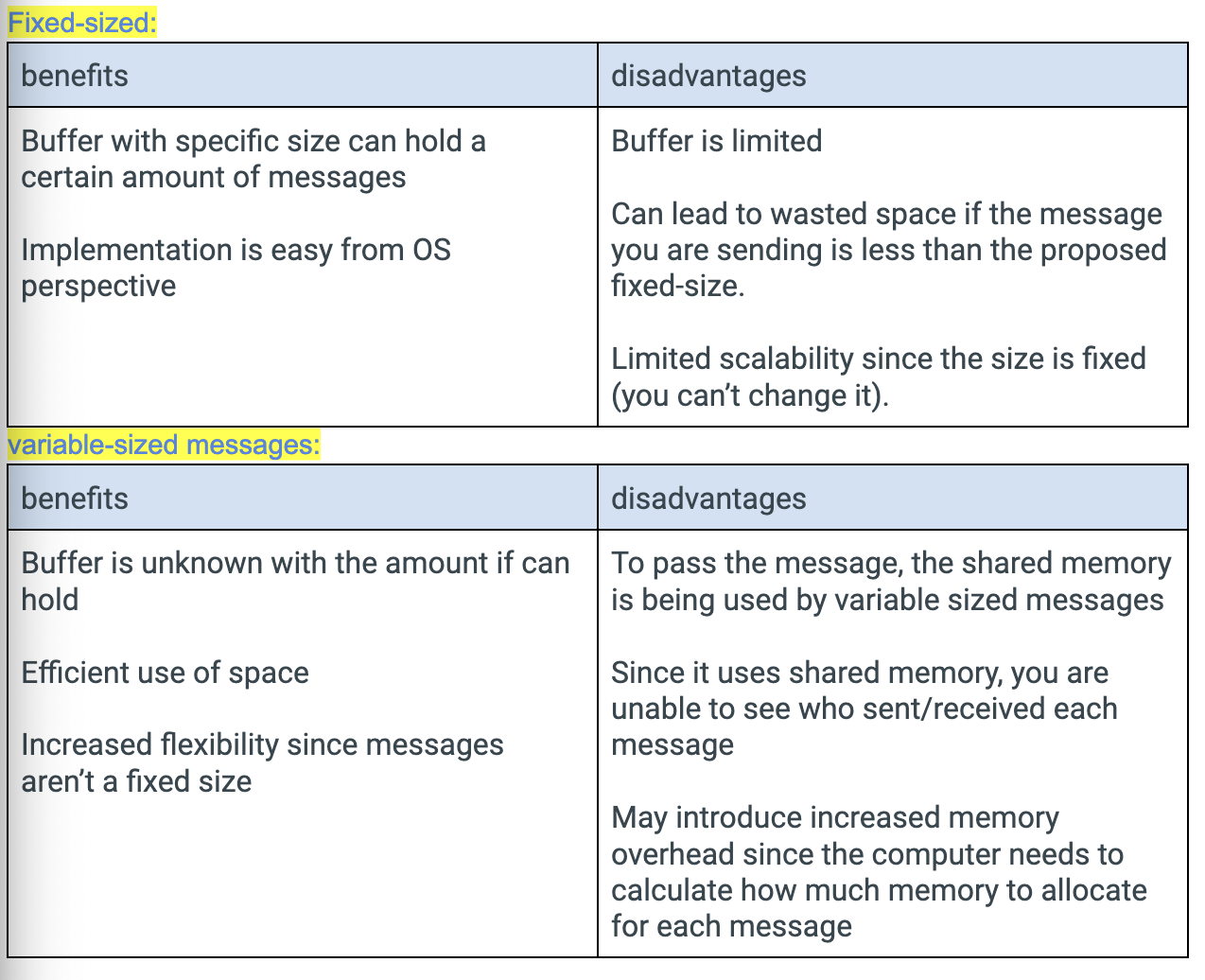
Basically Fixed: system design is simple. User programs get more complicated to use fixed buf.
Variable: User programs get simple to send any size of data. System needs to fragment user data into frames.
5
Consider the following code segment:
pid_t pid;
pid = fork(); //1: 2 t processes (original process) / 2 thr
if (pid == 0) { /* child process */
fork(); //2. 3 processes (child) / 3 threads
thread_create( . . .); //3. 3 processes / 5 thr (2 unique threads created)
}
fork(); 4. //6 total processes here, all processes executing this fork() / 8 threads
How many unique processes are created?
5 unique processes (6 total processes)
How many unique threads are created?
2 unique threads (8 total threads)
Each process starts single thread. There are 2 processes going into the if statement, so once it reaches ‘thread_create’, that is when 2 threads are created
As described in Section Linux threads, Linux does not distinguish between processes and threads. Instead, Linux treats both in the same way, allowing a task to be more akin to a process or a thread depending on the set of flags passed to the clone() system call. However, other operating systems, such as Windows, treat processes and threads differently. Typically, such systems use a notation in which the data structure for a process contains pointers to the separate threads belonging to the process. Contrast these two approaches for modeling processes and threads within the kernel.
In windows a thread has a user stack and kernel stack, a thread ID, a register set, a program counter, and a private storage area used by run-time libraries and linked libraries, In linux the address space is shared. When clone() is called to create new threads in Linux, the set of flags passed in can be used to determine how much sharing takes place between a parent and its child, however, if no flags are specified then no sharing takes place which makes it more similar to the fork() system call. When a new task is created using clone(), rather than copying all data structures, the new task points to the data structures of the parent flag. This is helpful as it is more efficient in resource sharing and flexibility.
The program shown in the figure below uses the Pthreads API. What would be the output from the program at LINE C and LINE P?
#include <pthread.h>
#include <stdio.h>
int value = 0;
void *runner(void *param); /* the thread */
int main(int argc, char *argv[])
{
pid_t pid;
pthread_t tid;
pthread_attr_t attr;
pid = fork();
if (pid == 0) { /* child process */
pthread_attr_init(&attr);
pthread create(&tid,&attr,runner,NULL);
pthread_join(tid,NULL);
printf("CHILD: value = %d",value); /* LINE C */
}
else if (pid gt; 0) { /* parent process */
wait(NULL);
printf("PARENT: value = %d",value); /* LINE P */
}
}
void *runner(void *param) {
value = 5;
pthread_exit(0);
}
LINE C Output: “CHILD: value = 5”
LINE P Output: “PARENT: value = 0”
6
Push Migration vs Pull Migration
Push works well if there are only a few busy CPU cores but not if there are many busy CPU cores.
Pull is opposite where it works if there are only a few idle CPUs but not if there are many idle CPUs.
8
Can you implement P and V functions using the TestAndSet instruction? If so, how? Briefly design the algorithm you thought.
P( int sem )
while( true ) {
while( test_and_set( lock ) == true ) ;
sem--;
if ( sem < 0 ) {
lock = false;
continue;
else {
lock = false;
break;
}
}
}
V( int sem ) {
while( test_and_set( lock ) == true );
sem++;
lock = false;
}
Compare Test and Set & Semaphore
Test & set:
Pros: Fast if used in multi-processors
Cons: Slow and wasting CPU time if used on a single CPU system
Semaphore
Pros: Quickly switching process/thread contexts if used on a single CPU system
Cons: Slow in particular used in multi-processors as OS needs to be called.
Midterm Review
Q1.
- 1 The following is what we discussed in discussion 2.
Mickey Mouse is an undergraduate research assistant. He received the following instruction from his advisor:
• Login uw1-320-20 with our project account “project”.
• Go to the “~/src” directory.
• Compile all.cpp files into a.out.
• Check if the “project” account is running a.out in background. If so, make sure to terminate it.
• Run a.out with its priority 5 and save its standard output into the “result.txt” file.
• Archive all files under the “~/src” directory into “~/src.tar”.
• Mickey was using “uw1-320-21” with his “mickey” account before he followed this instruction. When he tried to run “a.out”, he found that the “project” account was running a.out in background and its PID was 1234.
Give a correct sequence of all Unix commands he typed to complete this instruction.

List three distinct types of events upon which OS can get back CPU from the current user program.
- System calls made from a user process
- Hardware interrupts including timer interrupts
- CPU traps such as illegal instructions, seg faults, etc
Which of the above events in Q1-2 may occur upon executing each statement of the following main function? Mark appropriate blanks with √. Note that some statements may not cause any events or the others may cause multiple events.
int main( ) {
int *array = new int[1000000]; //System Call (malloc)
cin >> array[0];// Sys Call (std in) and Interrupts
*(a + 999999) = 123; //None
*(a – 100) = 456;// Traps (accessing memory out of range)
}
Consider the following five options to implement synchronization between a producer and a consumer, both accessing the same bounded buffer. When we run a producer and a consumer on shared-memory-based dual-processor computer, which of the following implementation is the fastest? Justify your selection. Also select the slowest implementation and justify your selection. (After you have studied synchronization, come back here and solve this exercise.)
(1) Use the many-to-one thread mapping model, allocate a user thread to a producer and a consumer respectively, and let them synchronize with each other using test-and-set instructions.
(2) Use the many-to-one thread mapping model, allocate a user thread to a producer and a consumer respectively, and let them synchronize with each other using semaphore.
(3) Use the one-to-one thread mapping model, allocate a user thread, (i.e., a kernel thread) to a producer and a consumer respectively, and let them synchronize with each other using test-and-set instructions.
(4) Use the one-to-one thread mapping model, allocate a user thread, ( i.e., a kernel thread) to a producer and a consumer respectively, and let them synchronize with each other using semaphores.
(5) Allocate a different process to a producer and a consumer respectively, and let them synchronize with each other using semaphores. (Note that a bounded buffer is mapped onto the shared memory allocate by those processes through shmget and shmat.)
3 = fastest
1 = slowest
What outputs do you get when running the following code? (Related to HW2A)
#include <setjmp.h> // setjmp( )
#include <signal.h> // signal( )
#include <unistd.h> // sleep( ), alarm( )
#include <stdio.h> // perror( )
#include <stdlib.h> // exit( )
#include <iostream> // cout
using namespace std;
static jmp_buf env;
static void sig_alarm( int signo ) {
static int value = 2;
value = ( value == 1 ) ? 2 : 1; //value always equals 1
siglongjmp( env, value );
}
int main( void ) {
int ret_value = 0;
if ( signal( SIGALRM, sig_alarm ) ==SIG_ERR ) {
perror( "signal function" );
exit( -1 );
}
ret_value = sigsetjmp( env, 1 );//returns 0
switch ( ret_value ) {
case 0:
alarm( 1 );
cout << "0" << endl;
sleep( 2 );
break;
case 1:
alarm( 1 );
cout << "1" << endl;
sleep( 2 );
break;
case 2:
alarm( 1 );
cout << "2" << endl;
sleep( 2 );
break;
}
return 0;
}

Write processes.cpp where:
A parent process writes a message to:
cout << “okay?” << endl;
But stdout is redirected to pipe 1(0). dup2(fd[0][1],1)
A child process read the above message from
cin >> message;
But stdin is redirected to pipe 1(0). //std in = dup2(x,0)
dup2(fd[0][0],0)
A child process then writes a response to:
cout << “yes!” << endl;
But stdout is redirected to pipe 2(1). //std out = dup2(x,1)
dup2(fd[1][1],1)
A parent process reads the above response from
cin >> response;
But stdin is redirected to pipe 2.
dup2(fd[1][0],0)
Then, the parent write this response to stderr like:
cerr << response;
#include <sys/types.h> // for fork, wait
#include <sys/wait.h> // for wait
#include <unistd.h> // for fork, pipe, dup, close
#include <stdio.h> // for NULL, perror
#include <stdlib.h> // for exit
#include <iostream> // for cout
using namespace std;
int main( int argc, char** argv ) {
int fd[2][2]; // fd[0][] parent-->child; fd[1][] child-->parent
int pid; // process ID
char response[10], message[10];
if ( pipe( fd[0] ) < 0 ) { // parent wants to create pipe fd[0]
perror( "pipe fd[0] error" );
exit( -1 );
}
if ( pipe( fd[1] ) < 0 ) { // parent also wants to create pipe fd[1]
perror( "pipe fd[1] error" );
exit( -1 );
}
if ( ( pid = fork( ) ) < 0 ) {
perror( "fork a child: error" );
exit( -1 );
}
if ( pid > 0 ) { // parent
close( fd[0][0] ); //close parent-->child read pipe as it's not used
dup2( fd[0][1], 1 ); //dup2 redirect pipe write 0 to stdout
close( fd[1][1] ); //close child--> parent write pipe as it's not used
dup2( fd[1][0], 0 );//redirect read of pipe 1 to std in
cout << "okay?" << endl;
cin >> response;
cerr << response;
}
else { // child
close( fd[0][1] ); //close parent-->child write pipe
dup2( fd[0][0], 0 ); //duplicate parent-->child read pipe to stdin
close( fd[1][0] ); //close child--> parent read pipe
dup2( fd[1][1], 1 );//redirect write pipe of childparent to std out
cin >> message;
cout << "yes!" << endl;
}
}