CSS 430 Operating Systems - Lecture Notes
What is the point of operating systems?
Definitions
| Term | Definition |
|---|---|
| Resource Allocator | manages and allocates resources |
| Control Program | controls the execution of user programs and operations of I/O devices |
| Kernel | The one program running at all times |
Lecture 1 2023-01-03
- execute user programs and simplify problem solving
- making a system simple to use
- use the hardware efficiently
- Contro
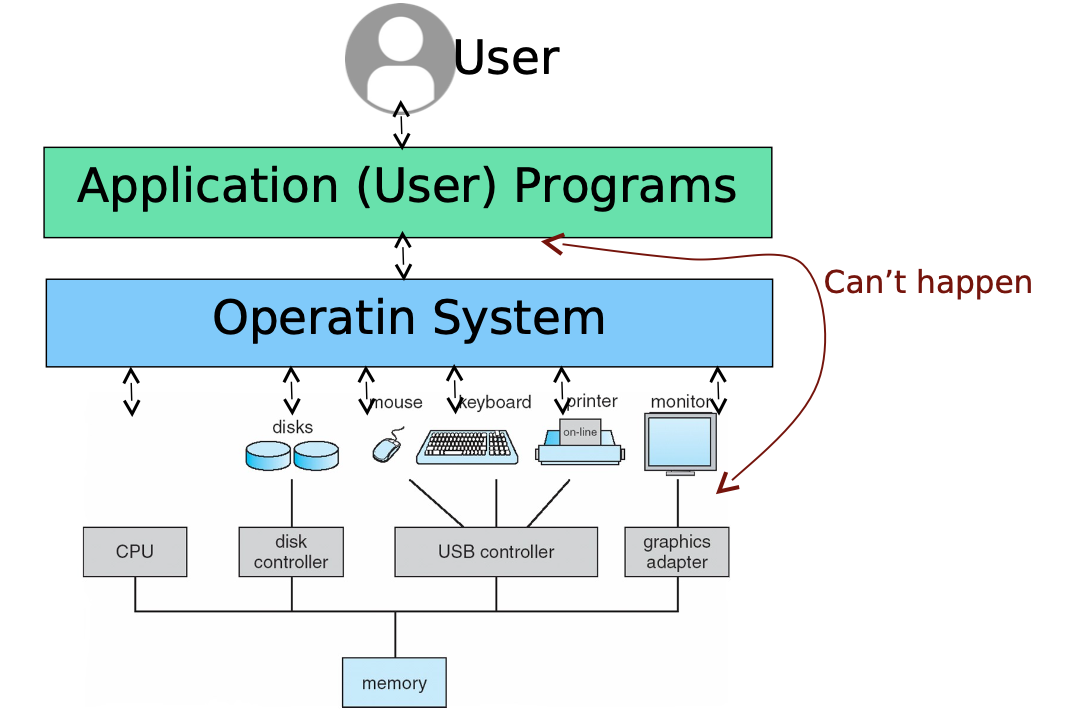
OS To Manage Hardware
A job is a process or a task
IBM Mainframe uses "Job", Unix uses "process", Windows/Linux uses "task"
Difference Between Java and C++
Operating Systems History
- Batch Systems
- Multiprogramming: IBM 360
- Time-Sharing systems: Multics, Unix
- Personal-computer Systems: Windows, Linux
- Symmetric multiprocessors
- Dual-Core systems: Intel Core 2 Duo
- Cluster Systems: RPC, Servers Etc
Batch Systems - 50's
A job is assembled of the program data and control cards
Programmers pass their jobs to an operator and the operator batched jobs together
The OS transfers control from one job to another, and each job output is sent back to the programmer
Interaction from User to OS
The Operating system cannot access the mode bit as it determines system mode.
User Mode: execution done on behalf of the user
Monitor Mode- execution done on behalf of the operating system
Synchronous I/O
- During execution, each program needs I/O operations to receive keyboard inputs, open files...and print out results.
- Early in the computer era, a program had to wait for an I/O operation to be completed before it could continue
- This causes a lot of CPU idle time
Think POLLING
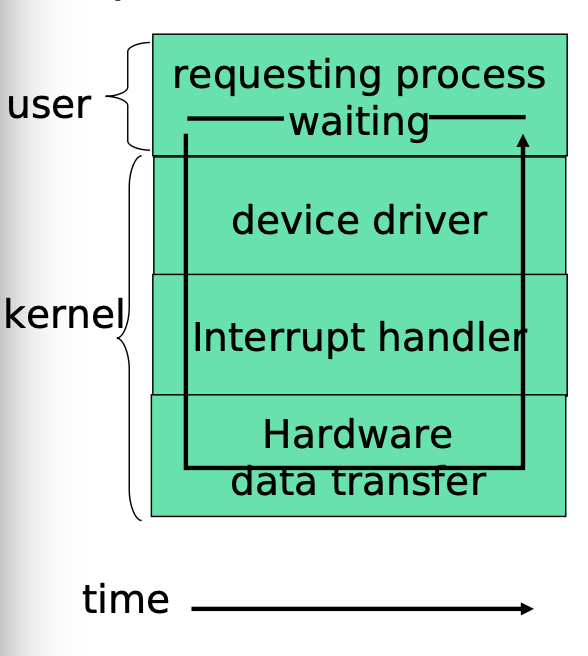
Async I/O and Interrupts
- Asynchronous I/O returns control to a user program without waiting for the I/O cycle to complete
- when the I/O is completed, an interrupt occurs to CPU that temporarily suspends the user program and handles the I/O device
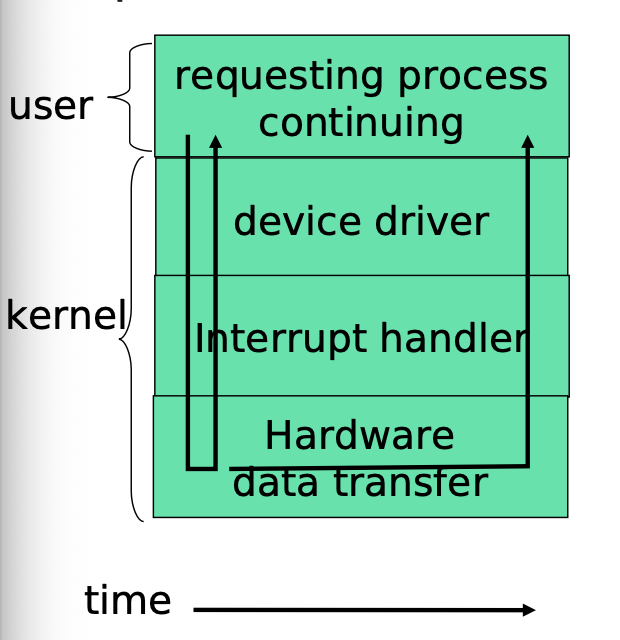
Multiprogramming
- A continuation of Async I/O and interrupts
- Several jobs are kept in main memory at the same time
- OS picks one of them to execute
- The job may have to wait for a slow I/O operation to complete
- OS switches to and executes another job
- to facilitate multiprogramming, OS needs:
- Job Scheduling
- Memory management
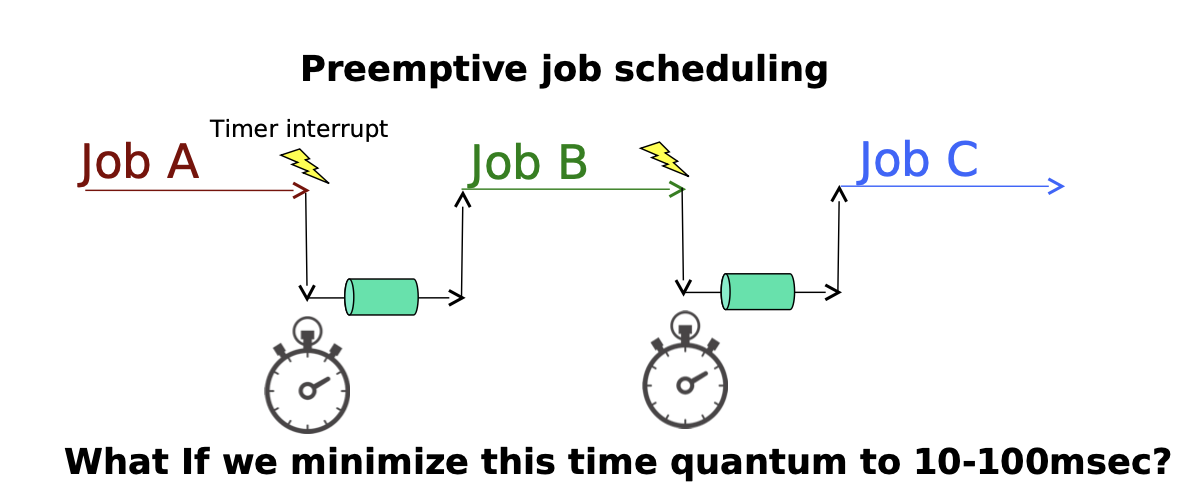
Timer Interrupt
- if all jobs request I/O services (eg disk access) frequently enough, OS can allocate CPU to them equally
- What if some jobs are computation-insensitive?
Time Sharing Systems
- A logical extension of multiprogramming
- Each user has at least one separate program in memory
- a program in execution is called a process
- Process switch occur so frequently that users can interact with each program while it's running
- file system allows users to access data and program interactively
Advanced Hardware
Exercise 1.1
Exercise 1.6
Exercise 1.8
Zybooks 1.14.1, 1.14.6, 1.14.8
- Another type of multiprocessor system is a clustered system, which gathers together multiple CPUs. Clustered systems differ from the multiprocessor systems described in Section Multiprocessor systems in that they are composed of two or more individual systems—or nodes—joined together; each node is typically a multicore system. Such systems are considered loosely coupled.
- A layer of cluster software runs on the cluster nodes. Each node can monitor one or more of the others (over the network). If the monitored machine fails, the monitoring machine can take ownership of its storage and restart the applications that were running on the failed machine.
To an extent, yes. Most embedded systems don't have a privileged mode set in hardware
- Magnetic Tapes
- Optical Disks
- Hard-Disk Drives
- Non-Volatile Memory
- Main Memory
- Cache
- Registers
Early Computers did not have interrupts, timers, or privileged instructions, What features was OS unable to facilitate?

- System Calls
- Interrupts (timer, disk, network)
- Traps/Exceptions(Seg Fault)
Set value of timer (privileged).
Read the clock(not privileged).
Clear memory(not necessarily but maybe).
Issue a trap instruction(.
Turn off interrupts.
Modify entries in device-status table.
Access I/O device.
Lecture 2 2023-01-05
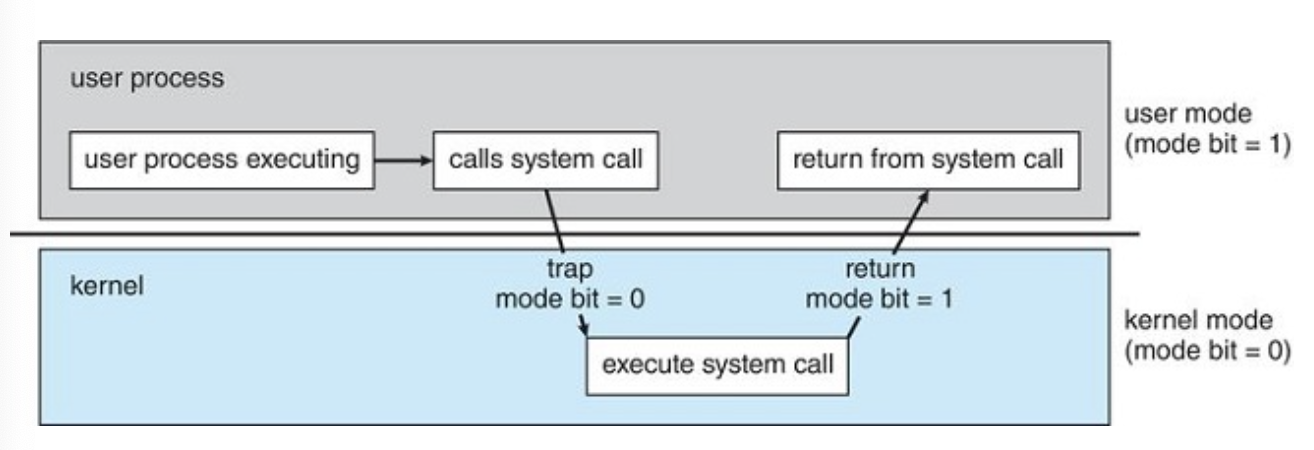
System Calls
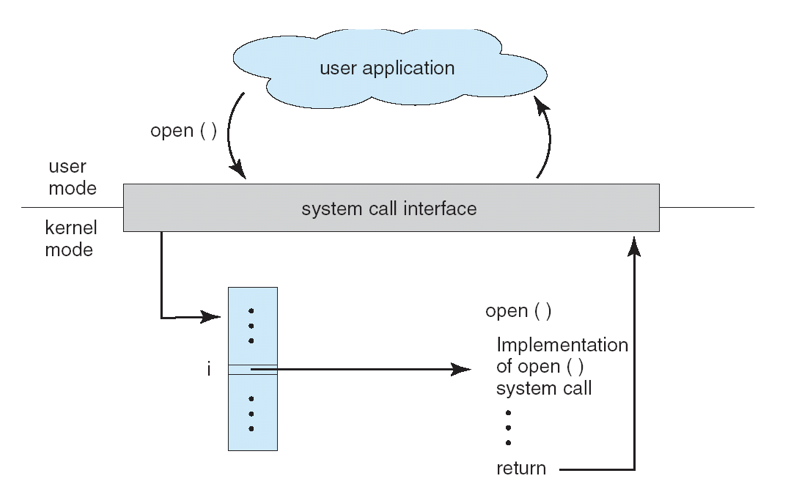
When a user program executes a special instruction like trap
- CPU recognizes it as an interrupt
- the mode shifts to kernel mode
- control jumps to the appropriate vector
- The OS saves the user program context
- it begins system call
- the OS restores the registers
- it shifts back to user mode
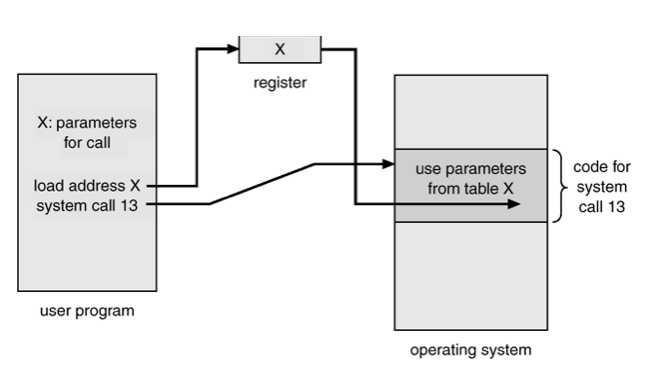
When implemented via C++, this will be converted into assembly code

With C++ the compiler will insert the trap into your assembly code, however with Assembly, you need to call it manually
G
Command Interpreters
The program that reads and interprets control statements
- CLI in DOS
- Shell in UNIX
- GUI in Mac windows and linux
- program execution: a.out, g++
- process management: ps, kill, sleep, top, nice, pstack
- I/O operation: lpr, clear, lprm, mt
- File System Manipulation: ls, mkdir, mv, rm, chmod, [u]mount
- Communication: write, ping, msg
Shell
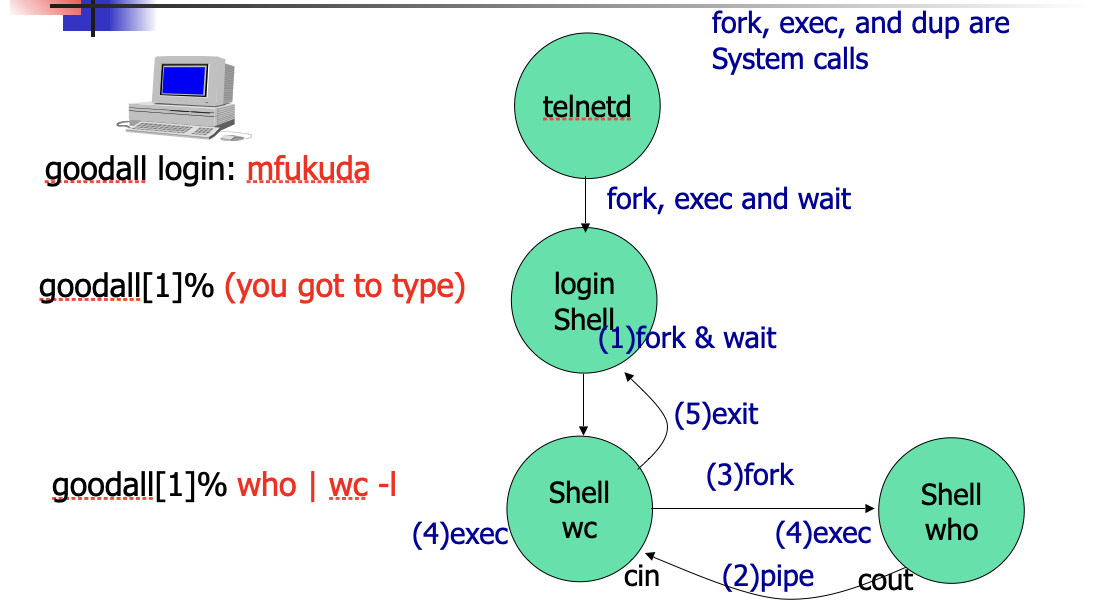
Now we more often use sshd instead of telnetd
Pipe chains the standard output of one process into the standard input of another input. It is a communication channel
Process
ps lists processes running (process status)
PID is process ID
A program in execution. Process execution must progress in sequential fashion
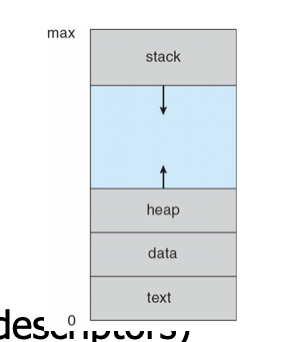
A process includes:
- Program Counter
- Stack(local variables)
- Data section (global Data)
- Text (code)
- Heap (dynamic data)
- Files (cin, cout, cerr, etc)
Process Creation
Parent process creates children processes
Resource sharing
- Resources inherited by children: file descriptors, shared memory, and system queues
- Resources not inherited by children: address space
Execution - parent and child execute concurrently
- parent waits by
waitsystem call until the children terminate
UNIX examples forksystem call creates new processexeclpsystem call used afterforkto replace the processes memory space with a new program

Process termination
Process termination occurs when
- it executes the last statement
- it executes the
exitsystem call explicitly
Upon process termination
- Termination code is passed from child (via
exit) to parent (viawait) - Process' resources are deallocated by OS
Parent may terminate execution of children processes (via kill)) when
- Child has exceeded allocated resources
- task assigned to child is no longer required
- parent is exiting (cascading termination)
- Some operating systems don't allow child to continue if its parent terminates
Producer-Consumer Problems
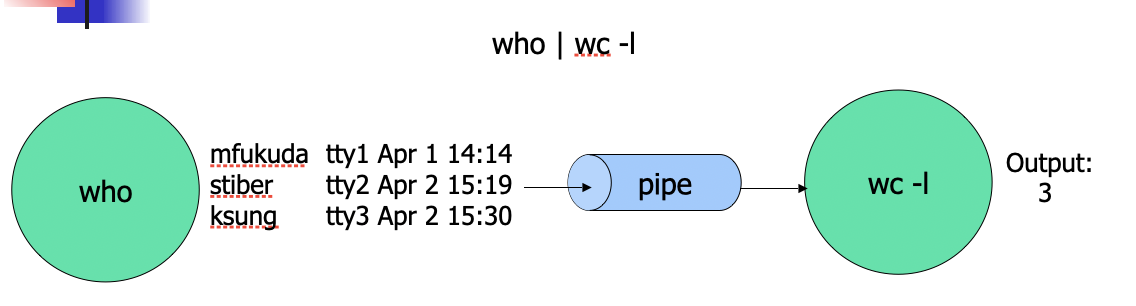
Producer Process
- Who produces a list of current users
Consumer Process - wc receives it for counting number of users
Communication link - OS provides a pipe
Direct Communication Example: Pipe
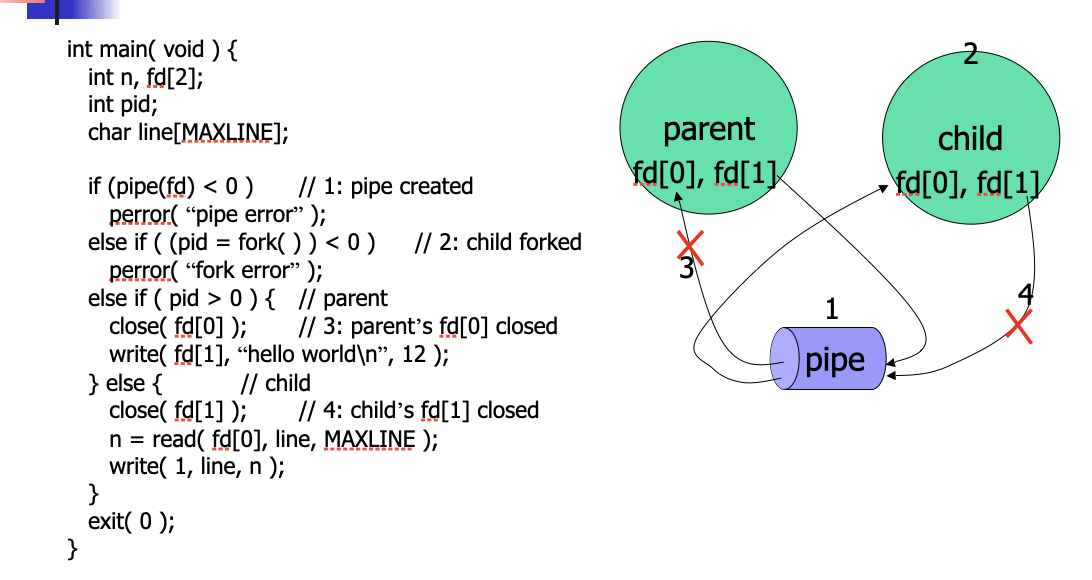
if (pipe<0){
//error
}
else
We will use dup2 to change the standard output and standard input
Discussion 1
-
Mickey Mouse is an undergraduate research assistant. He received the following instruction from his advisor:
- Login uw1-320-20 with our project account “project”.
- Go to the “~/src” directory.
- Compile all.cpp files into a.out.
- Check if the “project” account is running a.out in background. If so, make sure to terminate it.
- Run a.out with its priority 5 and save its standard output into the “result.txt” file.
- Archive all files under the “~/src” directory into “~/src.tar”.
- Mickey was using “uw1-320-21” with his “mickey” account before he followed this instruction. When he tried to run “a.out”, he found that the “project” account was running a.out in background and its PID was 1234.
-
Give a correct sequence of all Unix commands he typed to complete this instruction.
Discussion 2
- In Unix, the first process is called
init. All the others are descendants of “init”. Theinitprocess spawns atelnetdprocess that detects a new telnet connection. Upon a new connection,telnetdspawns a login process that then overloads ashellon it when a user successfully log in the system. - Now, assume that the user types
who | grep mfukuda | wc –l. Draw a process tree frominitto those three commands. Addork,exec,wait, andpipesystem calls between any two processes affecting each other.
Discussion 3
- In Unix, the first process is called
init. All the others are descendants of “init”. Theinitprocess spawns atelnetdprocess that detects a new telnet connection. Upon a new connection,telnetdspawns a login process that then overloads a shell on it when a user successfully logs in the system. Now, assume that the user has typeda.out | grep hello, where a.out is an executable file compiled from the following C++ program. Draw a process tree frominitto those two programs, (i.e. a.out and grep). (Note that your tree may have more three processes.) Addfork,exec,wait, andpipesystem calls between any two processes affecting each other. For each pipe, indicate its direction with an arrow, (i.e., →).
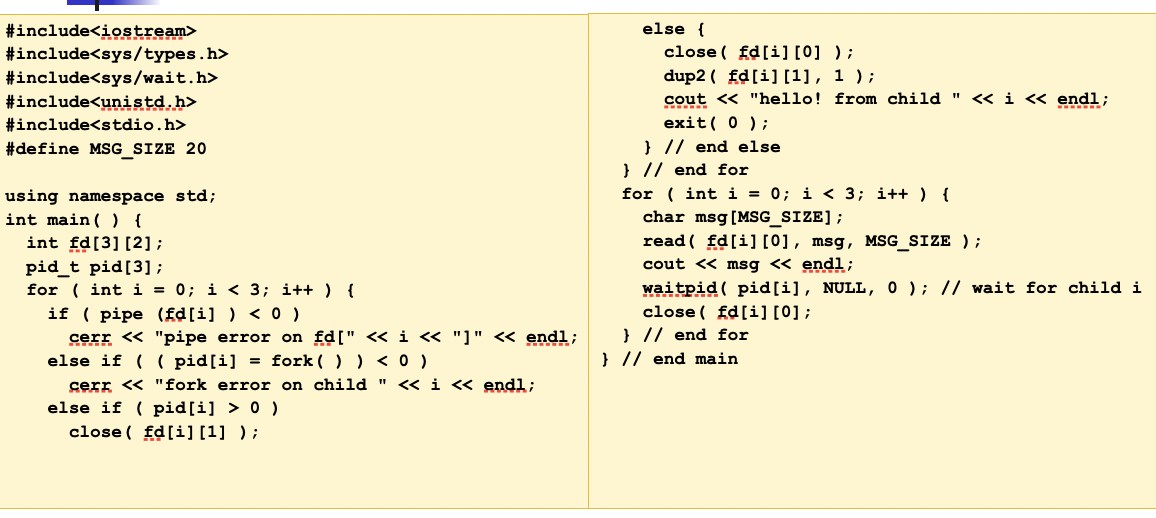
Lecture 3 2023-01-010
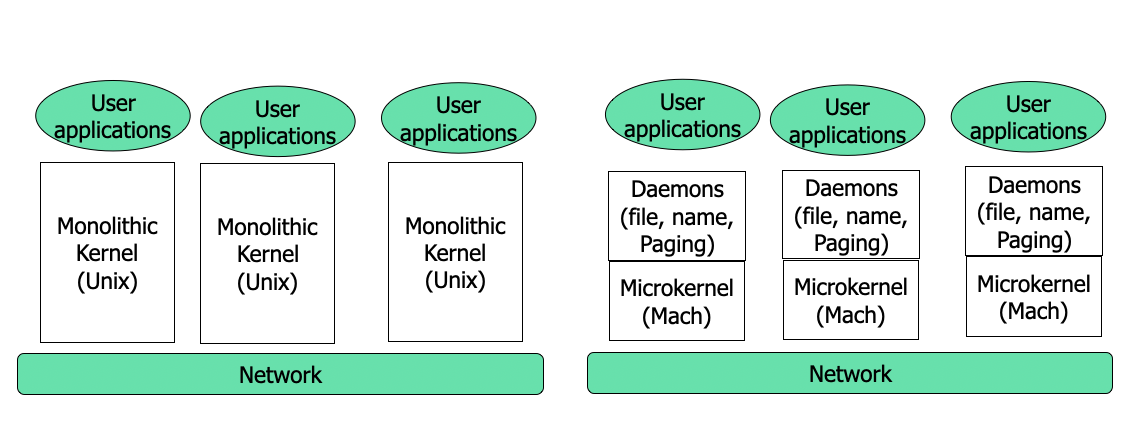
Monolithic vs Micro Kernels
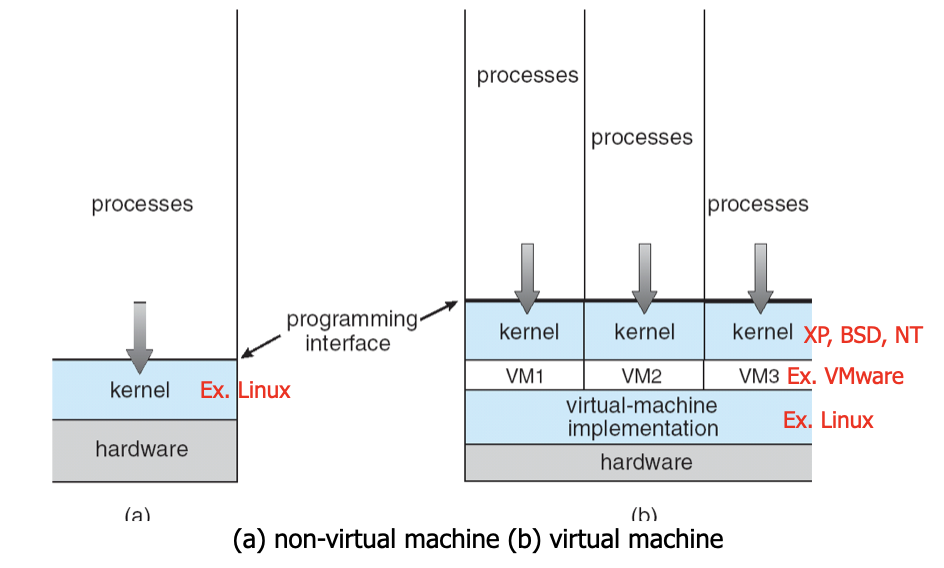
Virtualization
Process Tree
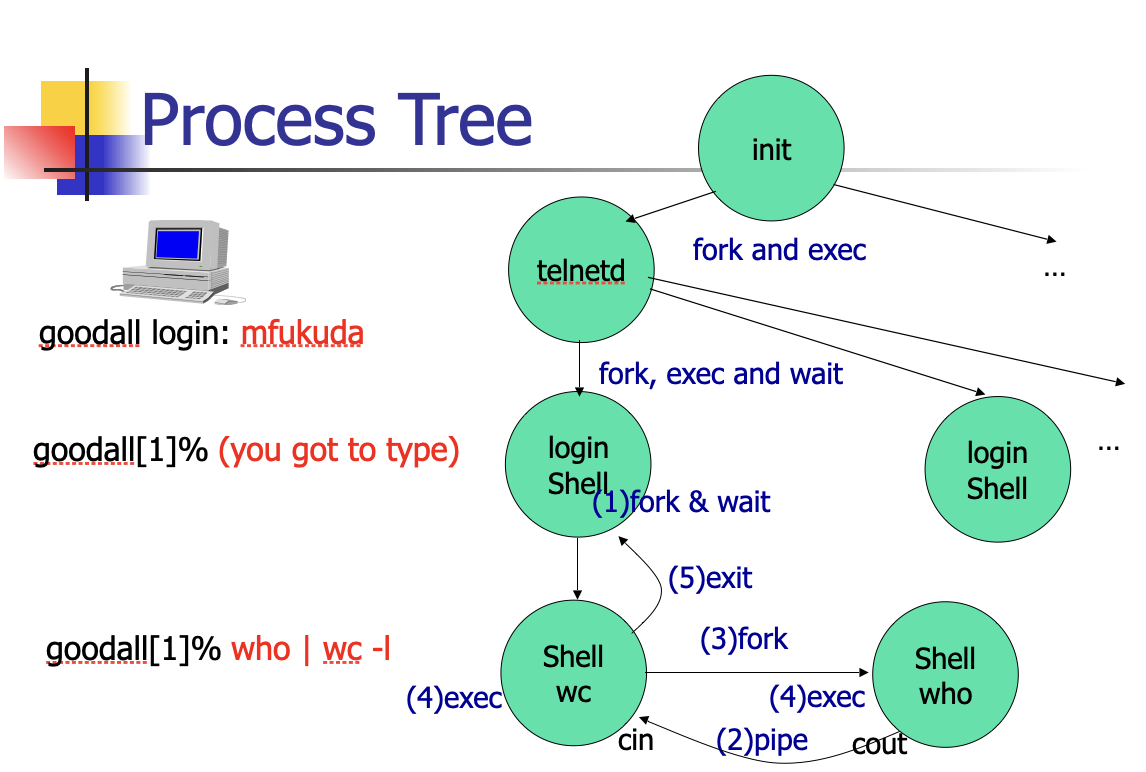
Will wait for the termination of the child process.
Process Control Block

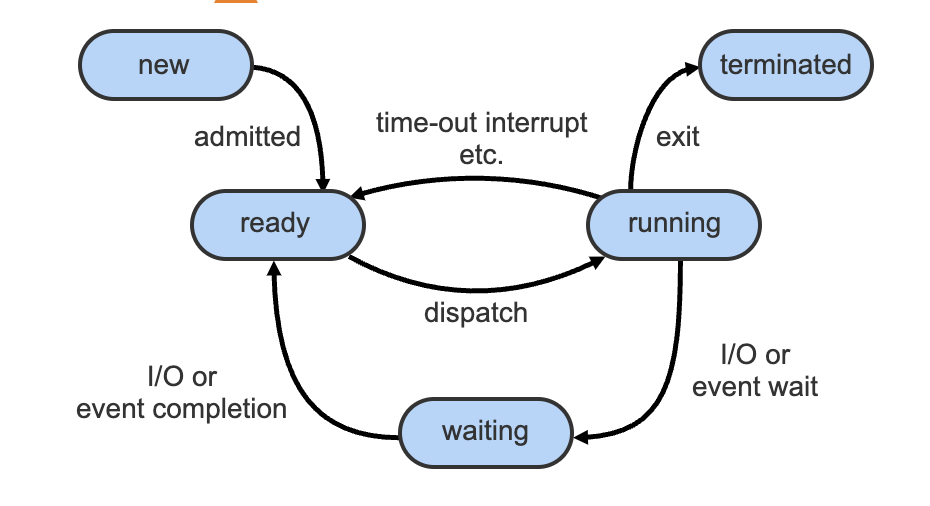
Process State
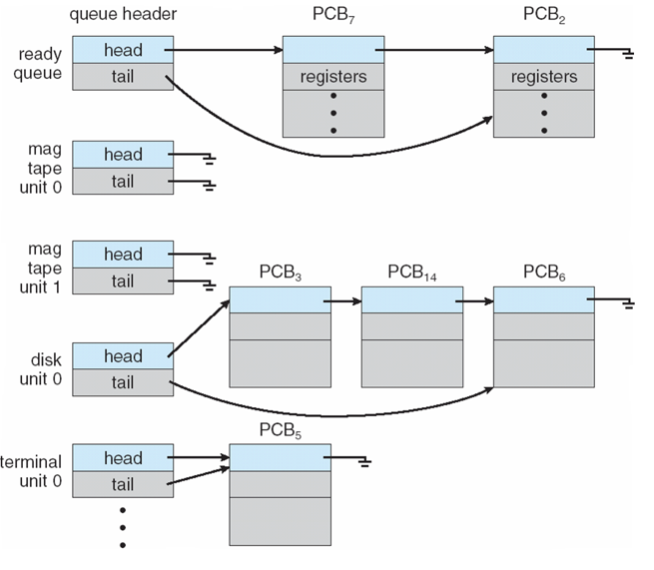
Process Scheduling Queues
Inter-Process Communication
Exit()wait()parameters passing from child to parent process- Shared memory: indirect communication - Unix
shmget - Message passing:
- direct communication: pipe and socket
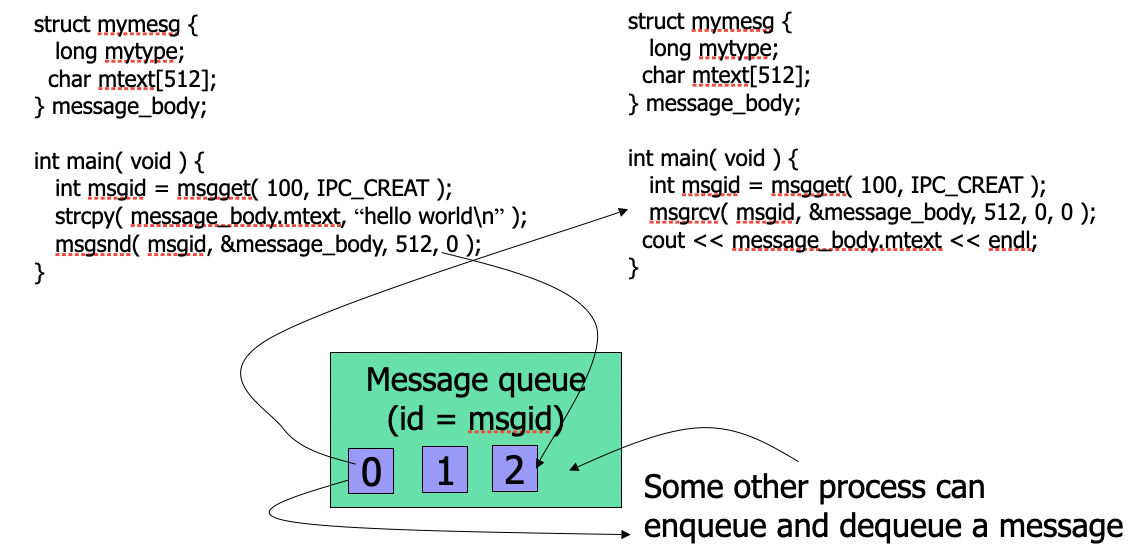
- Indirect communication: Unix message queue
Communication Models
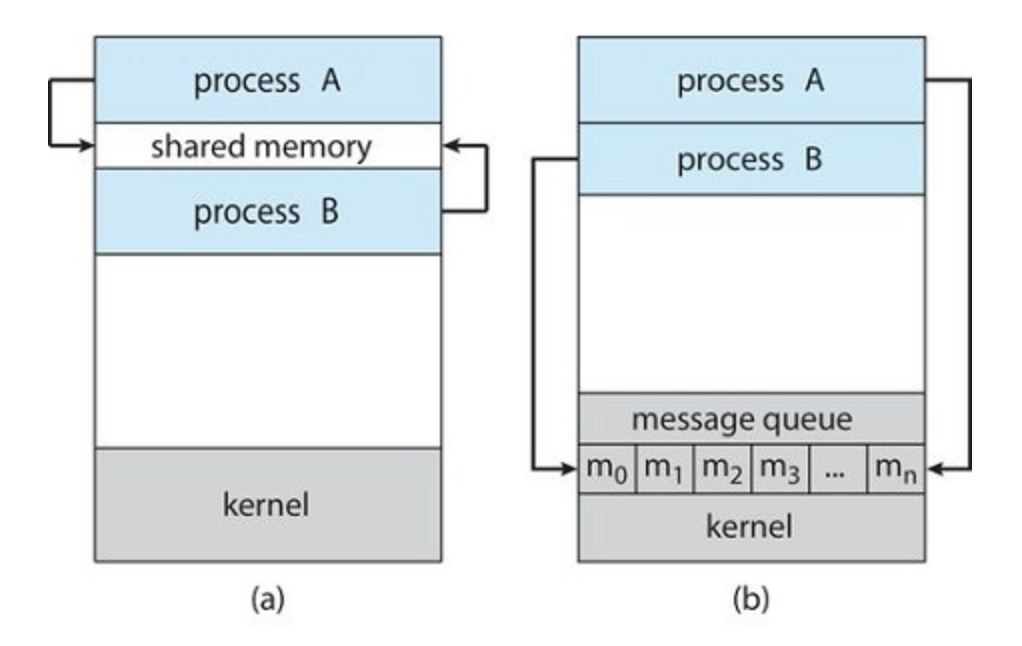
Shared Memory
- communication link or media has a bounded space to buffer in transfer data
import java.util.*;
public class BoundedBuffer
{
public BoundedBuffer( ) {
count = 0;
in = 0;
out = 0;
buffer = new Object[BUFFER_SIZE];
}
public void enter( Object item ) { }
public Object remove( ) { }
public static final int BUFFER_SIZE = 5;
private int count; // #items in buffer
private int in; // points to the next free position
private int out; // points to the next full position
private Object[] buffer; // a reference to buffer
}
group 8
In Unix, the first process is called init. All the others are descendants of “init”. The init process spawns a telnetd process that detects a new telnet connection. Upon a new connection, telnetd spawns a login process that then overloads a shell on it when a user successfully log in the system. Now, assume that the user types who | grep mfukuda | wc –l. Draw a process tree from init to those three commands. Add fork, exec, wait, and pipe system calls between any two processes affecting each other. If it’s tedious to draw an illustration directly here, draw an illustration on scratch paper, photograph it, and paste it to this google doc.
Mickey Mouse is an undergraduate research assistant. He received the following instruction from his advisor:
Login uw1-320-20 with our project account “project”.
Go to the “~/src” directory.
Compile all.cpp files into a.out.
Check if the “project” account is running a.out in background. If so, make sure to terminate it.
Run a.out with its priority 5 and save its standard output into the “result.txt” file.
Archive all files under the “~/src” directory into “~/src.tar”.
Mickey was using “uw1-320-21” with his “mickey” account before he followed this instruction. When he tried to run “a.out”, he found that the “project” account was running a.out in background and its PID was 1234.
ssh project@uw1-320-20.edu
cd ~/src
g++ *.cpp
ps
kill -9 1234
nice -5 ./a.out > result.txt
tar -cvf - src > src.tar
In Unix, the first process is called init. All the others are descendants !of “init”. The init process spawns a telnetd process that detects a new telnet connection. Upon a new connection, telnetd spawns a login process that then overloads a shell on it when a user successfully logs in the system. Now, assume that the user has typed a.out | grep hello, where a.out is an executable file compiled from the following C++ program. Draw a process tree from init to those two programs, (i.e. a.out and grep). (Note that your tree may have more three processes.) Add fork, exec, wait, and pipe system calls between any two processes affecting each other. For each pipe, indicate its direction with an arrow, (i.e., →).
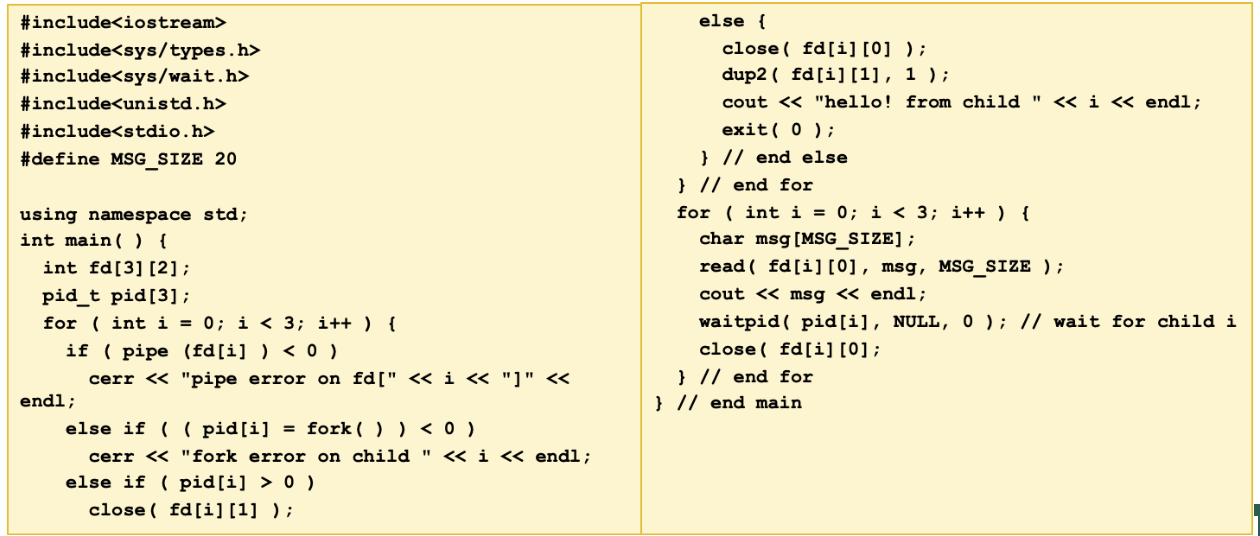
!Pasted image 20230112201345.png
Lecture 4 2023-01-12
Carry over from last lecture
When no other processes are running, init process (process 0) goes into HLT (halt)
Shared memory (why you may not want to use) - number of computing loads (beyond say, 20) - synchronizationWith shared memory, make sure there is inter process syncronization
Message Passing
- Message sysstem: processes communicate without shared variables
- IPC provides two operations
- send(message) message size fixed or variable
- receive(message)
If P and Q wish to communicate - establish communication link
- exchange messages via send and receive
Implementation - physical(shared memory, hardware bus)
- logical (logical properties)
Direct Communication
- Processes must name each other explicitly
- send(p, message) - send a message to process P
- receive(q, message) - receive a message from q
- Processes are created and terminated dynamically
- direct communication takes place between a parent and it's chiled
- example: pipe()
Socket
Socket is good for multiple computers
All I/O including IPC is handled with file descriptors (fd)
Indirect Communication
- Messages are directed and received from mailboxes (also referred to as ports)
- each mailbox has a unique ID
- Processes can communicate only if they share a mailbox
- Processes must know only a mailbox id
- example: message queue
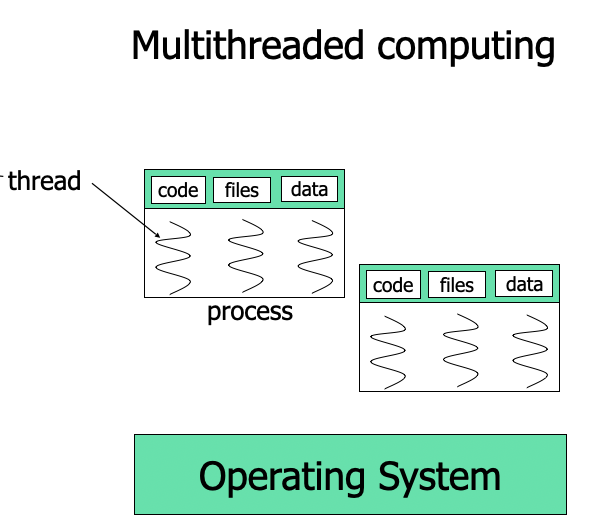
Thread Concepts
Process oriented computing
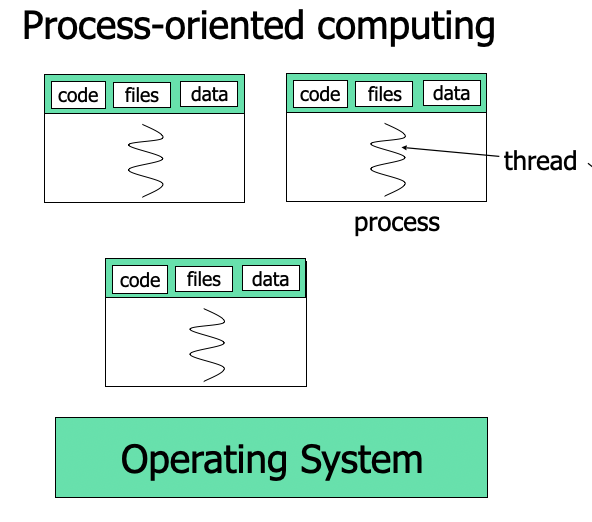
Multithreaded computing
main()
tid1 = pthread_create(func, args...){
}
tid2 = pthread_create(func, args...){
}
function(){
}
Single vs multithreaded Processes
- Processes
- Carries everything such as an address space, code, data, and files
- heavyweight in terms of creation/termination/context switching
- Threads
- shares an address space, code, data and files if they belong to same process
- lightweight in terms of creation/termination/context switching
- what is unique to each thread? (ID, register set, stack, program counter)
Java Threads
- created by:
- extending thread class
- implementing the runnable interface
Thread class extension
class Worker1 extends Thread {
public void run() {
while ( true )
System.out.println(“I am a Worker Thread”);
}
}
public class First {
public static void main(String args[]) {
First main = new First( );
}
First( ) {
Worker1 runner = new Worker1();
runner.start();
while ( true )
System.out.println(“I am the main thread”);
}
}
Runnable Interface Implementation
// This Runnable interface has been defined by system
public interface Runnable {
public abstract void run();
}
// You have to actually implement the run method.
class Worker2 implements Runnable extends myBaseClass {
public void run() {
while ( true )
System.out.println(“I am a Worker Thread”);
}
}
public class Second {
public static void main(String args[]) {
Second main = new Second( )
}
Second( ) {
Runnable runner = new Worker2();
Thread thrd = new Thread(runner);
thrd.start();
while ( true )
System.out.println(“I am the main thread”);
}
}
CSS430-Unique ThreadOS
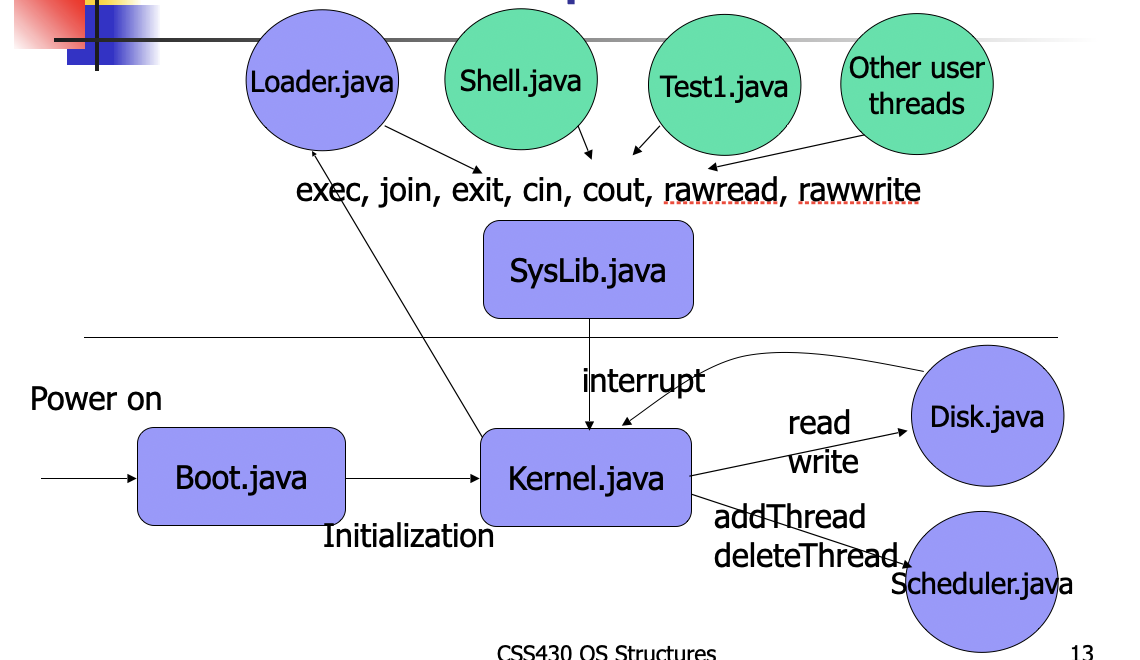
"java boot"
new thread is launched, thread id, parent id etc
Shell
ThreadOS Sys Lib
SysLib.exec( String args[] )loads the class specified in args[0], instantiates its object, simply passes the following elements of String array, (i.e., args[1], args[2], ...), and starts it as a child thread. It returns a child thread ID on success, otherwise -1.SysLib.join( )waits for the termination of one of child threads. It returns the ID of the child thread that has woken up the calling thread. If it fails, it returns -1.SysLib.sleep( long millis )sleeps the calling thread for given milliseconds.SysLib.exit( )terminates the calling thread and wakes up its parent thread if this parent is waiting on join( ).SysLib.cin( StringBuffer s )reads keyboard input to the StringBuffer s.SysLib.cout( String s )prints out the String s to the standard output. Like C's printf, it recognizes '\n' as a new-line character.SysLib.cerr( String s )prints out the String s to the standard error. Like C's printf, it recognizes '\n' as a new-line character.SysLib.rawread( int blkNumber, byte[] b )reads one block data to the byte array b from the block specified by blkNumber.SysLib.rawwrite( int blkNumber, byte[] b )writes one block data from the byte array b to the block specified by blkNumber.SysLib.sync( )writes back all on-memory data into a disk.
Prog 1BThreadOS Shell
import java.io.*;
import java.util.*;
class Shell extends Thread {
public Shell( ) {
}
public void run( ) {
for ( int line = 1; ; line++ ) {
String cmdLine = "";
do {
StringBuffer inputBuf = new StringBuffer( );
SysLib.cerr( "shell[" + line + "]% " );
SysLib.cin( inputBuf );
cmdLine = inputBuf.toString( );
} while ( cmdLine.length( ) == 0 );
String[] args = SysLib.stringToArgs( cmdLine );
int first = 0;
for ( int i = 0; i < args.length; i++ ) {
if ( args[i].equals( ";" ) || args[i].equals( "&" )
|| i == args.length - 1 ) {
String[] command = generateCmd( args, first, ( i==args.length - 1 ) ? i+1 : i );
if ( command != null ) {
// check if command[0] is “exit”. If so, get terminated
// otherwise, pass command to SysLib.exec( ).
// if aergs[i] is “&” don’t call SysLib.join( ). Otherwise (i.e., “;”), keep calling SysLib.join( )
}
first = i + 1; // go on to the next command delimited by “;” or “&”
}
}
}
}
Lecture 5 2023-01-17
Class Vs Interface
Why use runnable vs thread?
With runnable, it's more scalable, and you need to implement by yourself
Benefits of multithreading
- Responsiveness
- Deadlock avoidance
- Scalability, (utilization of multiprocess architecture)
- Resource sharing and economy
Responsiveness
Resource Sharing
| Process | Threads | |
|---|---|---|
| CPU Registers | Independent | Independent |
| Memory Space | Independent | Sharing text and heap |
| File/IO descriptors | Shared between a paretn and its child | Shared among threads |
Benefit 3: Economy
| Processes | Threads | |
|---|---|---|
| Page table | Independent | Shared |
| Memory Space | Copy on Write | Shared Except Stack |
| Creation | Heavy | Light |
| TLB | Necessary to flush | Shared |
| Memory accesses at the begging | DRAM X 2 | TLB |
| Context Switch | Slow | Fast |
Benefit 4: Utilization of multicore multiprocessor architecture
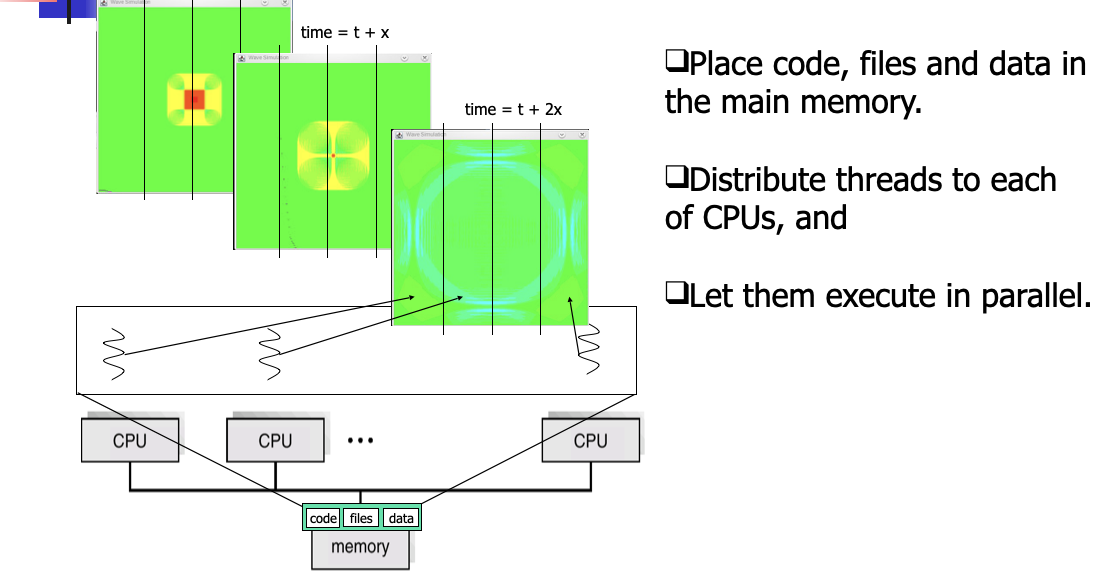
Many-to-one Model
Many threads mapped to a single kernel thread
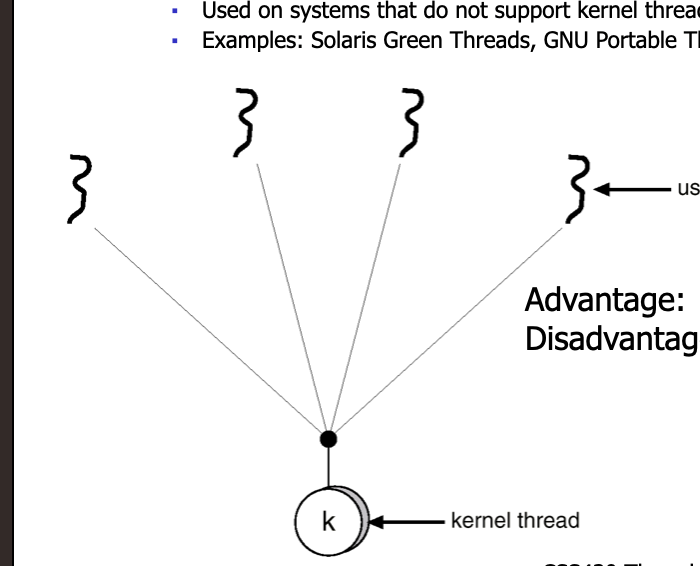
Advantage: Fast
Disadvantage: 1. Non preemption of very complicated to handle preemption and I/O, cannot utilize multiprocessor architecture
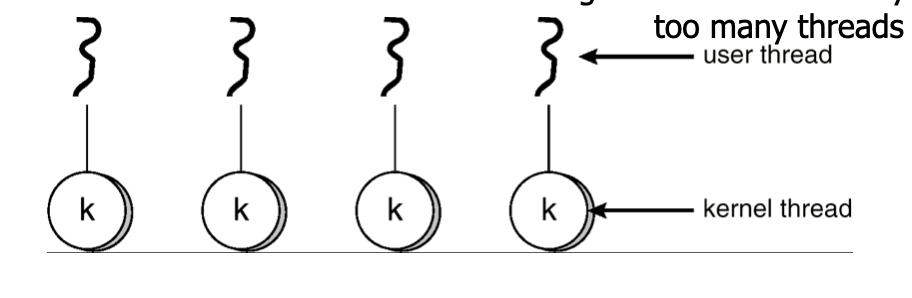
One-to-One Model
- Each user level thread mapped to kernel thread
- Examples
- Windows NT/XP/2k
- Linux
- Solaris 9
Advantage: Everything is supported by OS, Uses Multi-processor architecture
Disadvantage: slower than many-to-one model
Too many threads do not help.
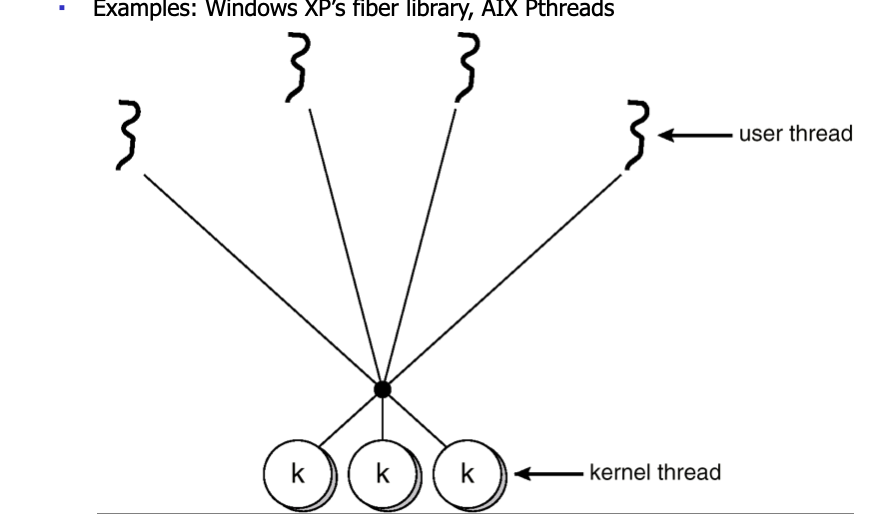
Many-to-Many Model
-covering the shortage of the previous two models
Examples:
- Window XP's fiber library
- AIX Pthreads
Process Structure
- Kernel schedules each LWP separately
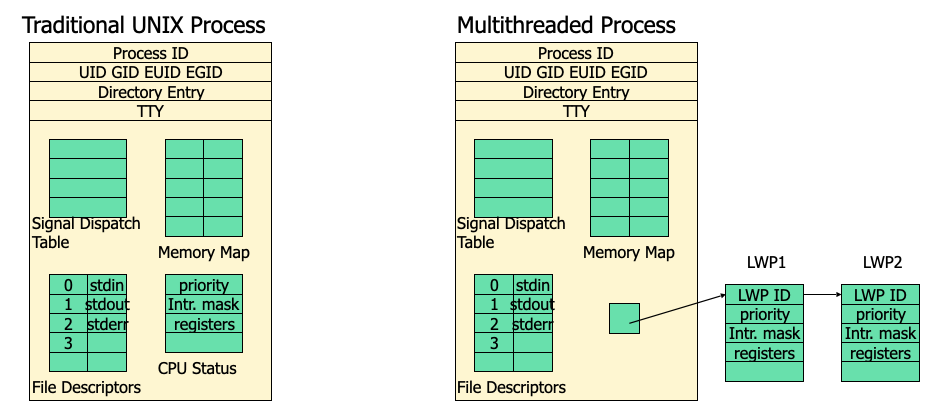
Thread Structures
- Thread library runs in a user space
- all threads shared the same address space
- each thread maintains its own information and stack space
- once a thread is mapped onto a LWP it runs on a CPU
Light weight process is the same as kernel thread
User Thread Emulation
- Strategy
- Register contents
- captured and restored with setjmp() and longjmp()
- Stack Contents
- Identified as a space between the current stack point (sp) and base pointer (bp)
- Register contents
setjmp() and longjmp()
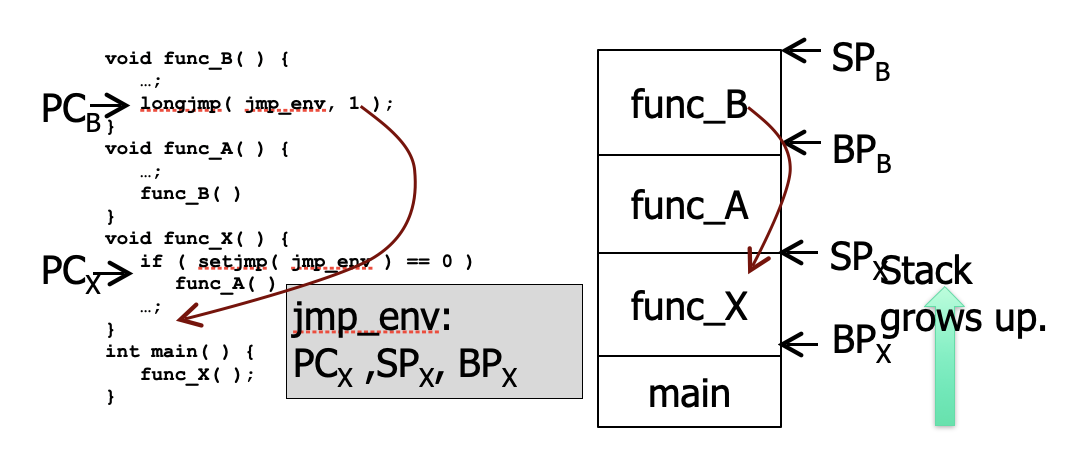
Program 2A

Lecture 6 2023-01-19
From Last Lecture
setjmp(registerset) to suspend current thread
longjump(registerset) to restore
Thread Private Resources:
- CPU Registers
- Stack
Base pointer is the base of the current stack, stack pointer is the top
CPU Scheduling
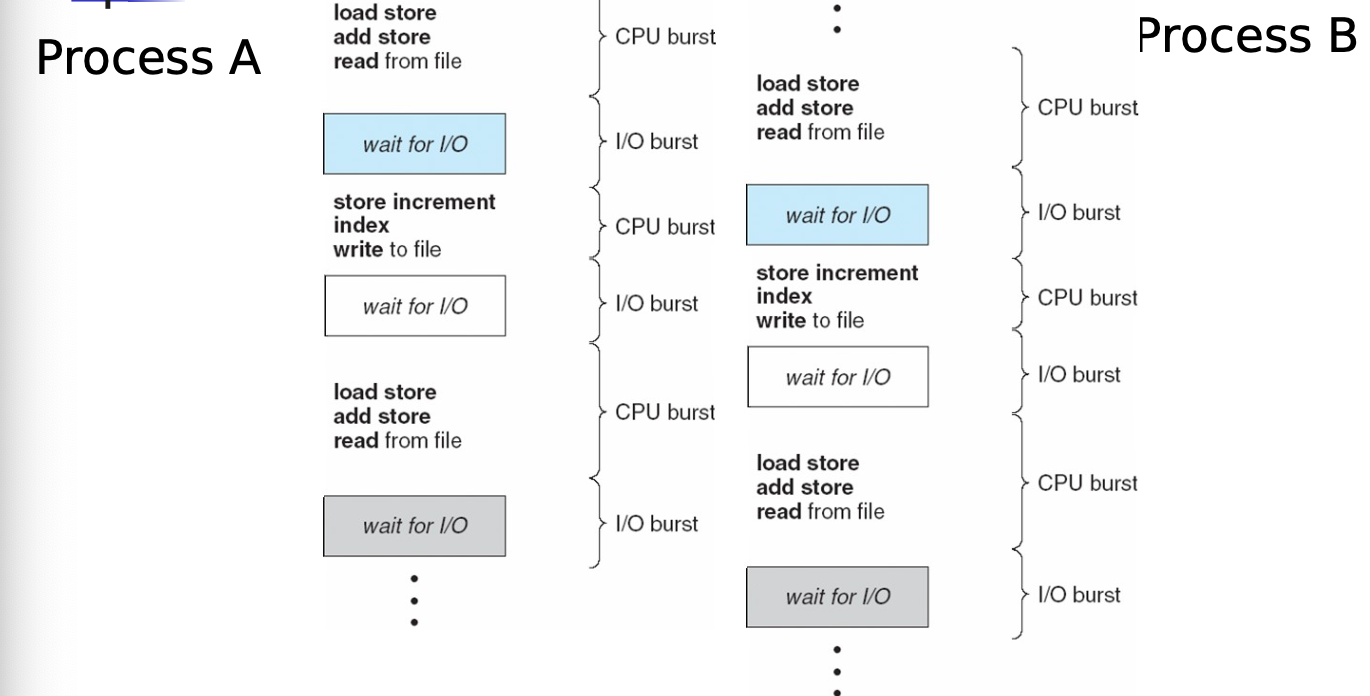
CPU I/O Burst Cycle
Histogram of CPU Burst Times
Dispatcher
Selects from among the processes in memory that are ready to execute, and allocates the CPU to one of them. (Short-term scheduler)
CPU scheduling decisions may take place when a process:
1. Switches from running to waiting state (by sleep).
2. Switches from running to ready state (by yield).
3. Switches from waiting to ready (by an interrupt).
4. Terminates (by exit).
Scheduling under 1 and 4 is nonpreemptive.
All other scheduling is preemptive.
Preemptive scheduling is usually done by timer interrupt
10ms - 100msG
Scheduling Criteria
- CPU utilization – keep the CPU as busy as possible
- Throughput – # of processes that complete their execution per time unit
- Turnaround time (TAT) – amount of time to execute a particular process
- Waiting time – amount of time a process has been waiting in the ready queue
- Response time – amount of time it takes from when a request was submitted until the first response is produced, not output (for time-sharing environment)
FCFS

SJF
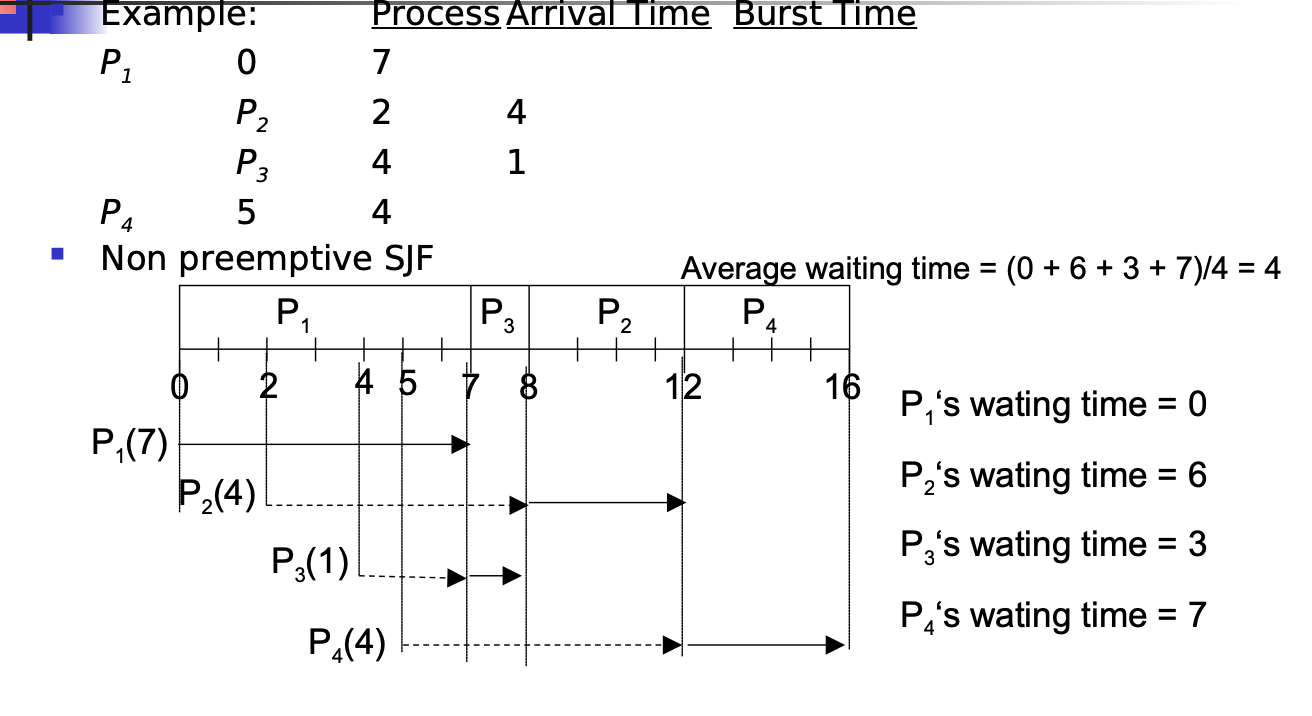
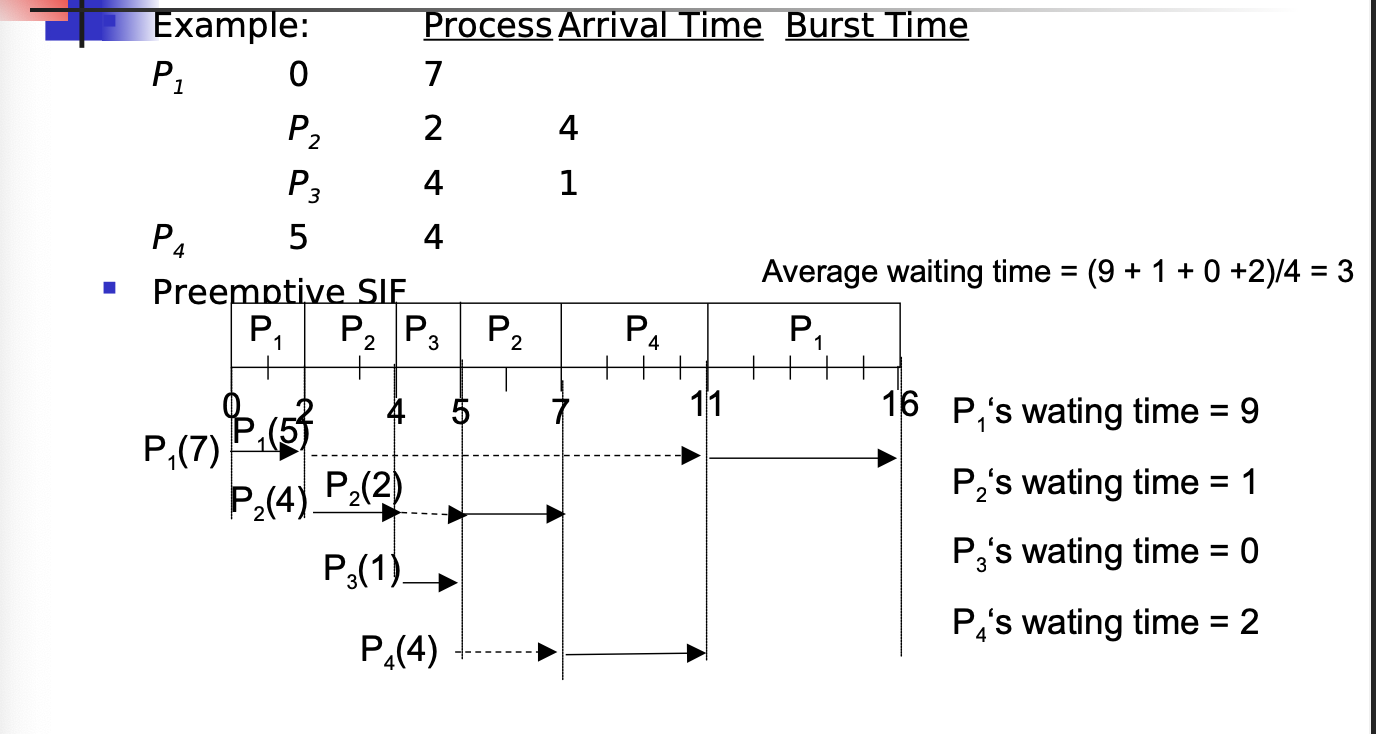
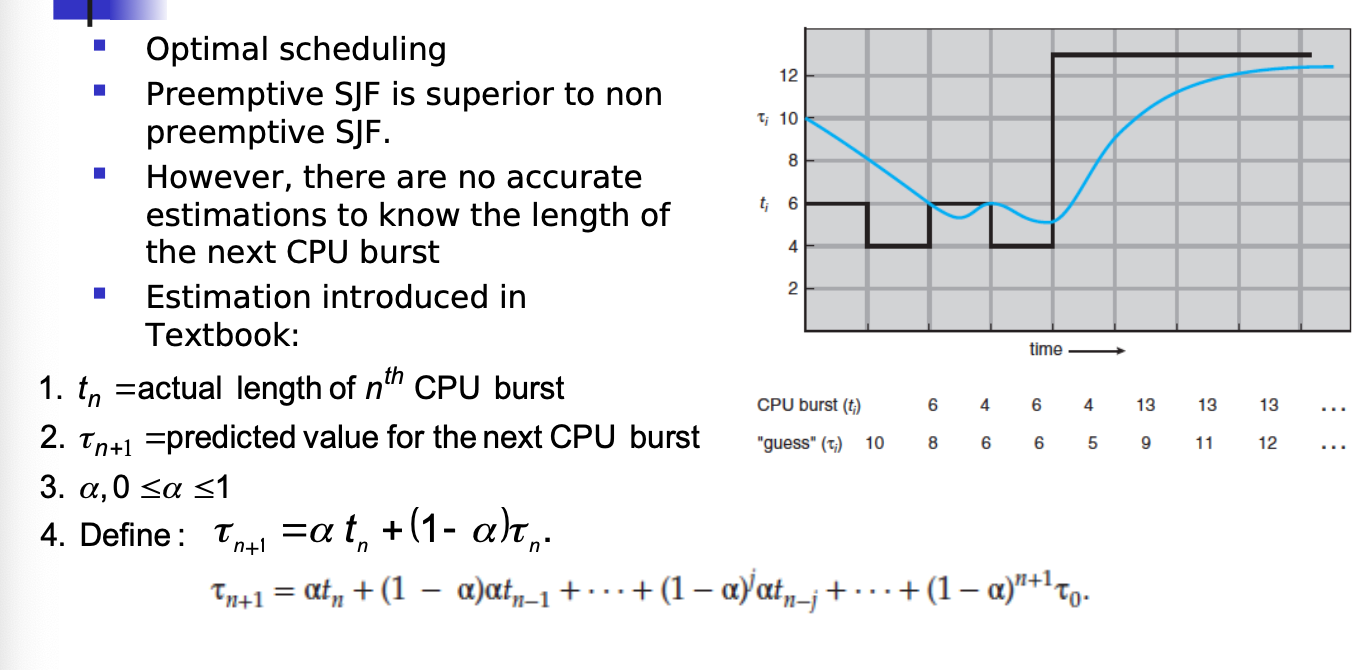
SJF With Preemption is the best scheduling algorithm
Priority Scheduling
-
A priority number (integer) is associated with each process
-
The CPU is allocated to the process with the highest priority (smallest integer == highest priority in Unix but lowest in Java).
- Preemptive
- Non-preemptive
-
SJF is a priority scheduling where priority is the predicted next CPU burst time.
-
Problem == Starvation – low priority processes may never execute.
-
Solution == Aging – as time progresses increase the priority of the process.
Round Robin Scheduling
- Each process is given CPU time in turn, (i.e. time quantum: usually 10- 100 milliseconds), and thus waits no longer than ( n – 1 ) * time quantum
- time quantum = 20
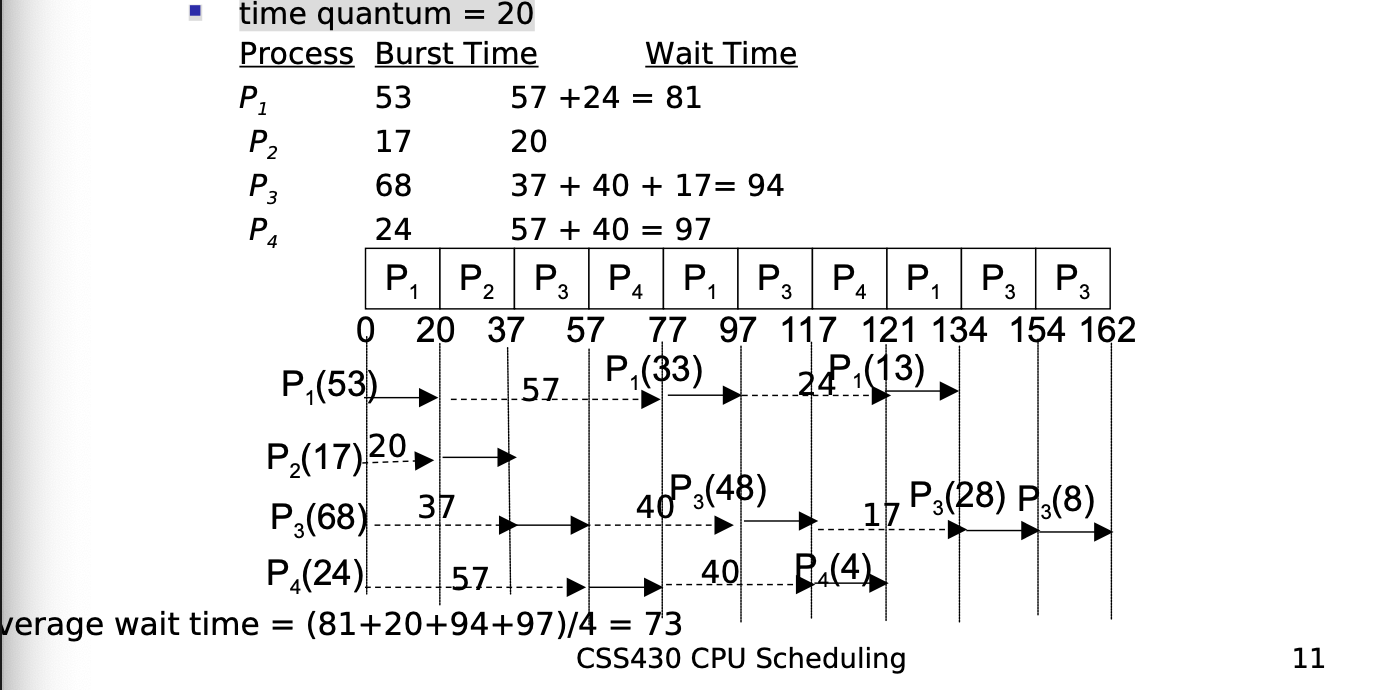
- Typically higher average turnaround than SJF but better response
- Performance
- q large -> FCFS
- q small -> q must be large with respect to context switch
Turnaround time varies with time quantum
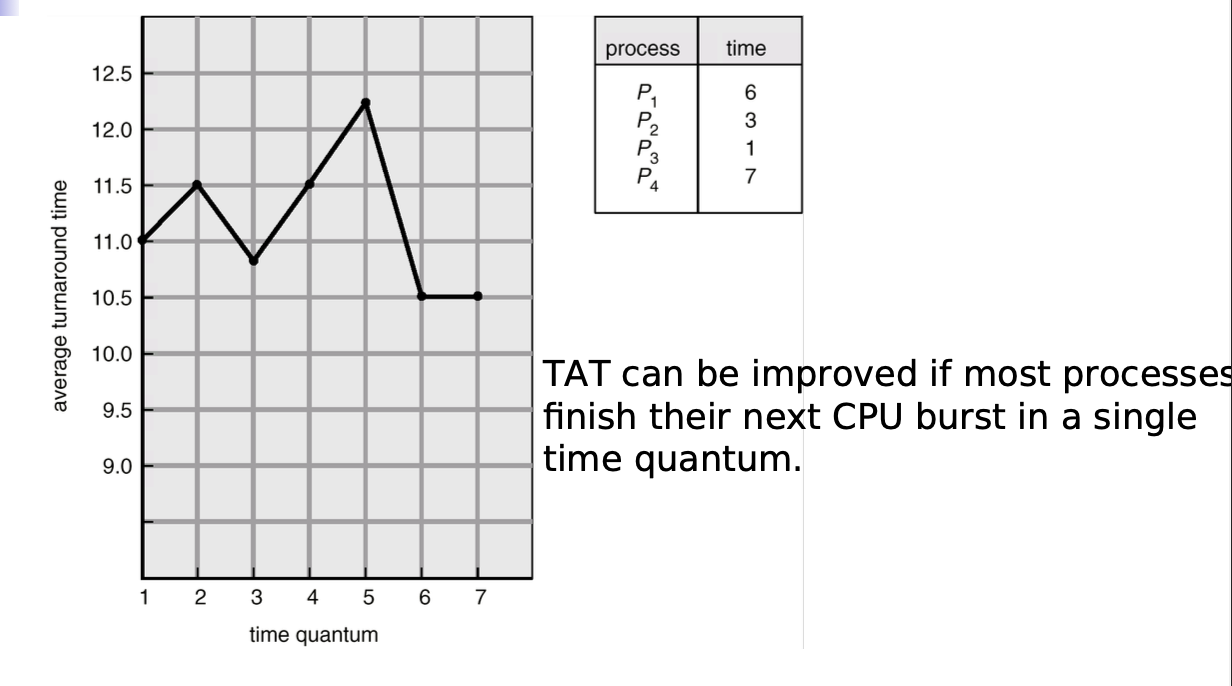
HW2A Round Robin Scheduling
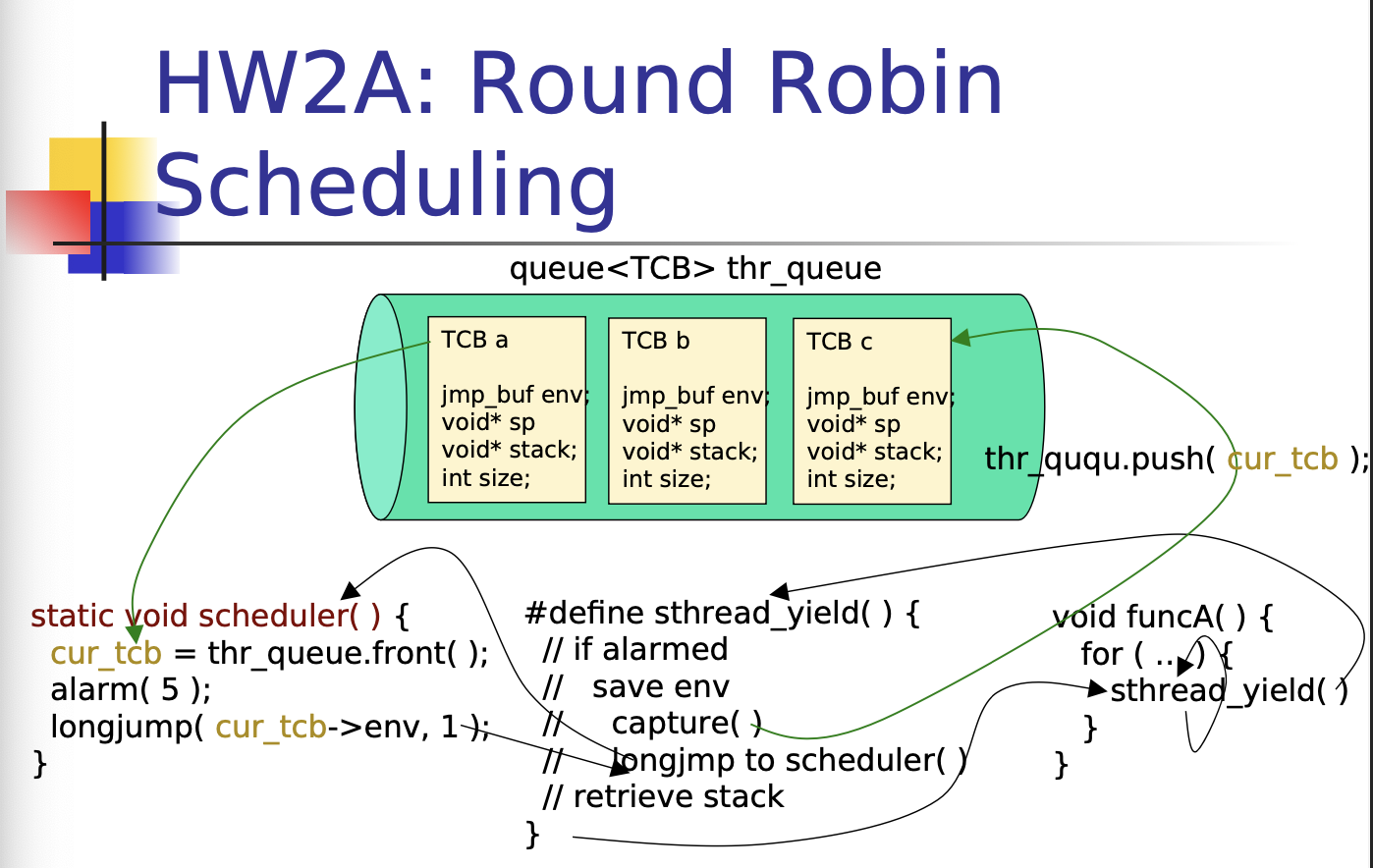
HW2A Stack Management
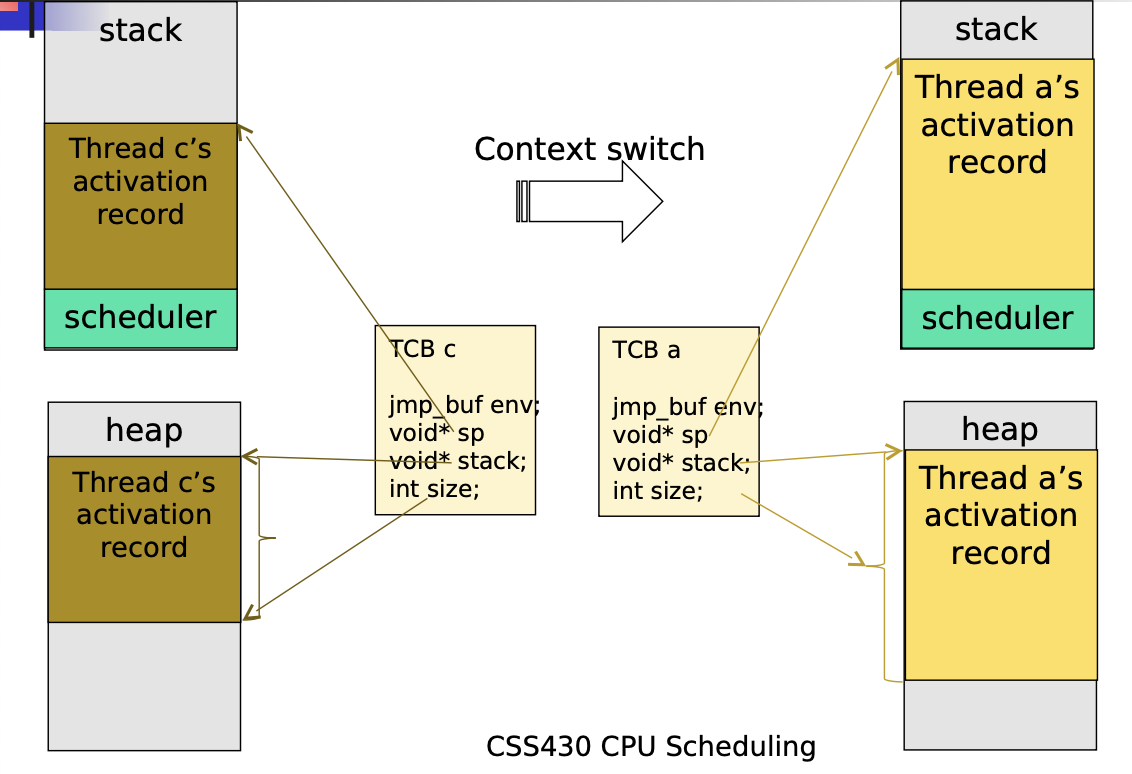
Lecture 7 2023-01-24
2A notes
Discussion
p1 wait = 0 8
p2 wait = 7.6 11.6
p3 wait = 10.6 11.6
tat ave = 10.4
sjf
p1 wait = 0 burst = 8 total 8
p3 wait = 8 burst = 1 total = 9
p2 wait = 8.6 burst = 4 total =12.6
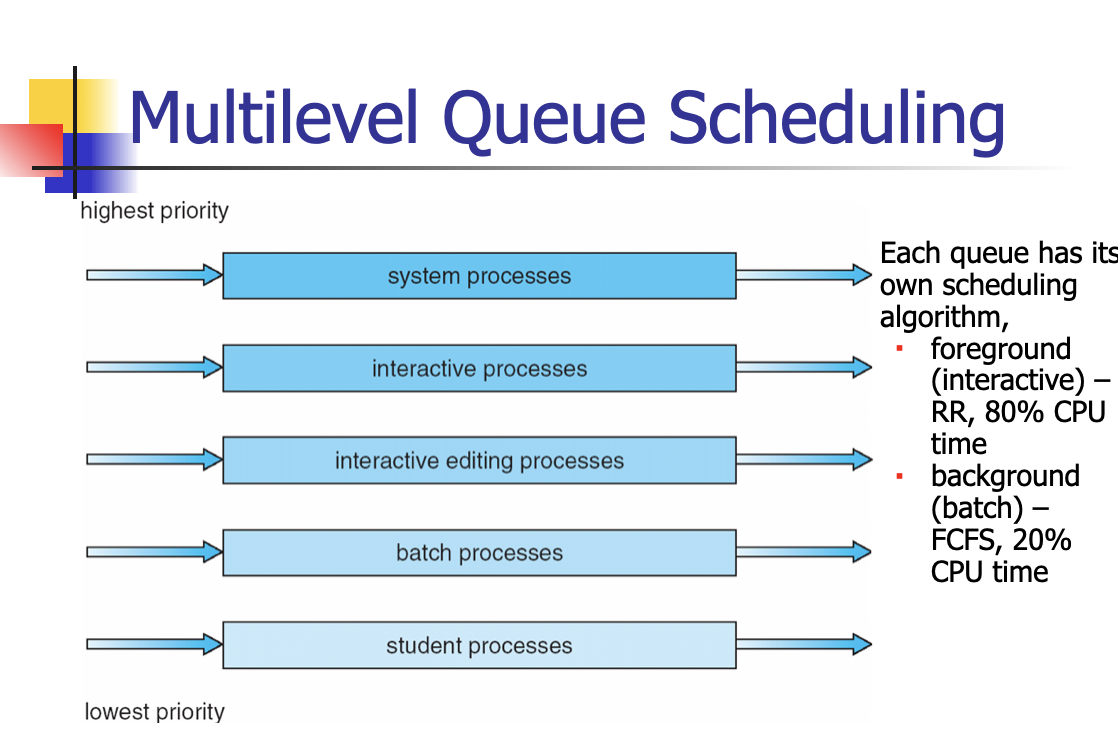
Multilevel Queue Scheduling
Multilevel Feedback-Queue Scheduling
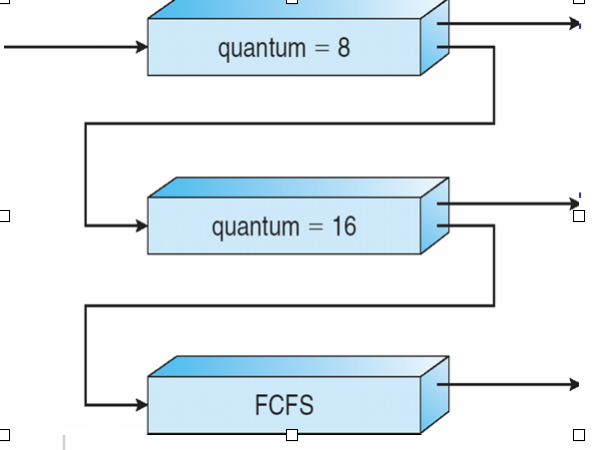
- A new job enters queue Q0 which is served FCFS. When it gains CPU, job receives 8 milliseconds. If it does not finish in 8 milliseconds, job is moved to queue Q1.
- At Q1 job is again served FCFS and receives 16 additional milliseconds. If it still does not complete, it is preempted and moved to queue Q2.
Cooperative Multithreading in java
A thread voluntary yielding control of the CPU is called cooperative multitasking
public void run( ) {
while ( true ) {
// perform a CPU-intensive task
…
// now yield control of the CPU
Thread.yield( );
}
}
- Thread.yield( ) is OS-dependent.
- Linux does not care about it.
- Solaris allows a thread to yield its execution when the corresponding LWP exhausts a given time quantum.
- Conclusion: Don’t write a program based on yield( ).
Java-based Round-Robin Scheduler
public class Scheduler extends Thread
{
public Scheduler( ) {
timeSlice = DEFAULTSLICE;
queue = new CircularList( );
}
public Scheduler( int quantum ) {
timeSlice = quantum;
queue = new CircularList( );
}
public void addThread( Thread t ) {
t.setPriority( 2 );
queue.addItem( t );
}
private void schedulerSleep( ) {
try {
Thread.sleep( timeSlice );
} catch ( InterruptedException e ) { };
}
public void run( ) {
Thread current;
this.setPriority( 6 );
while ( true ) {
// get the next thread
current = ( Thread )queue.getNext( );
if ( ( current != null ) && ( current.isAlive( ) ) {
current.setPriority( 4 );
schedulerSleep( );
current.setPriority( 2 );
}
}
}
private CircularList queue;
private int timeSlice;
private static final int DEFAULT_TIME_SLICE=1000;
}
Test Program
public class TestScheduler
{
public static void main( String args[] ) {
Thread.currentThread( ).setPriority( Thread.MAX_PRIORITY );
Scheduler CPUScheduler = new Scheduler( );
CPUScheduler.start( );
// uses TestThread, although this could be any Thread object.
TestThread t1 = new TestThread( “Thread 1” );
t1.start( );
CPUScheduler.addThread( t1 );
TestThread t2 = new TestThread( “Thread 2” );
t2.start( );
CPUScheduler.addThread( t2 );
TestThread t3 = new TestThread( “Thread 3” );
t3.start( );
CPUScheduler.addThread( t3 );
}
}
Why will this not work?
- Java: runs threads with a higher priority until they are blocked. (Threads with a lower priority cannot run concurrently.)
- This may cause starvation or deadlock.
- Java’s strict priority scheduling was implemented in Java green thread.
- In Java 2, thread’s priority is typically mapped to the underlying OS-native thread’s priority.
- OS: gives more CPU time to threads with a higher priority. (Threads with a lower priority can still run concurrently.)
- If we do not want to depend on OS scheduling, we have to use:
- Thread.suspend( )
- Thread.resume( )
HW2B Vector Queue TCB
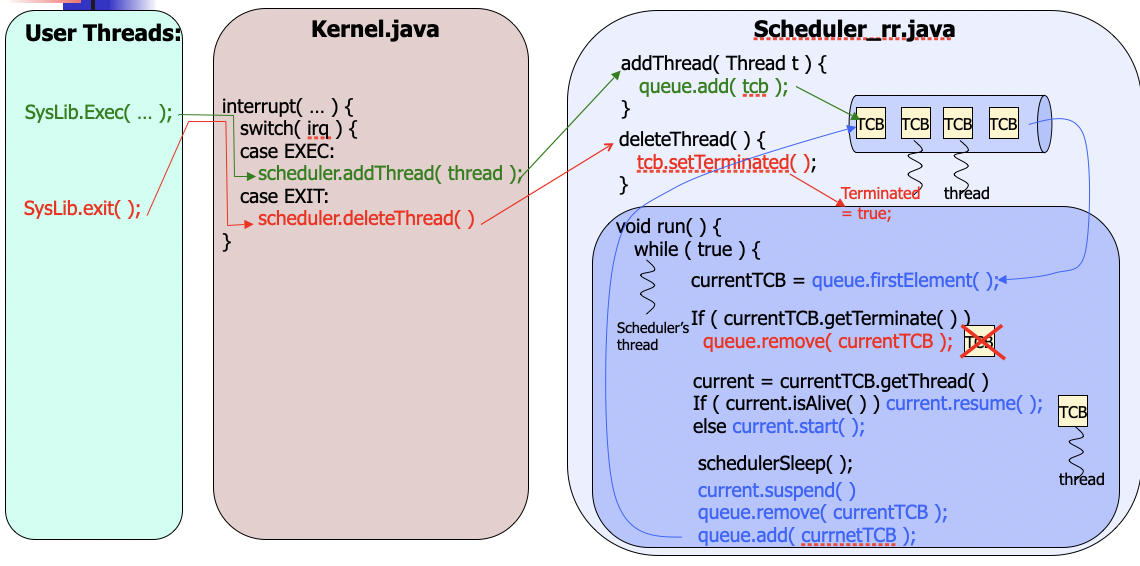
HW2B Multi-level feedback queue
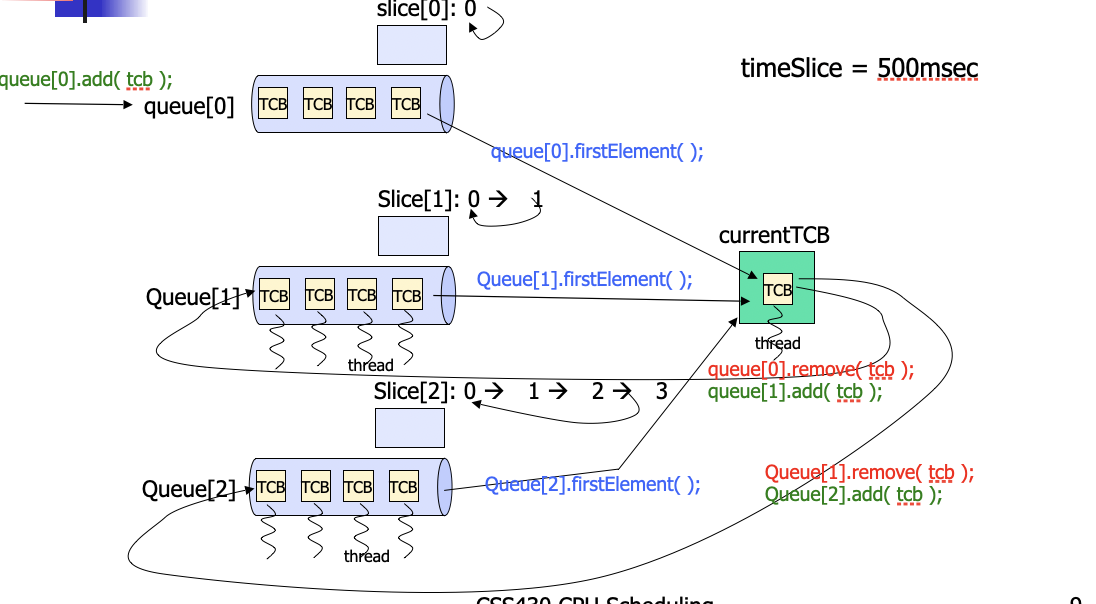
HW2B: MFQ Algorithm
class Scheduler {
public void run( ) {
while ( true ) {
for ( level = 0; level < 3; level++ ) {
if ( slice[level] == 0 ) {
if ( queue[level].size( ) == 0 )
continue;
currentTCB = ( TCB )queue[level].firstElement( );
break;
} else { // prevTCB was a previously currentTCB
currentTCB = prevTCB;
break;
}
}
if ( level == 3 )
continue;
// midlle: the same as Scheduler_rr.java: delete, start, resume, sleep(500), and suspend!
prevTCB = currentTCB;
// If slice[level] returns back to 0, currentTCB must go to the next level or stay queue[2]!
} }
Multiprocessor Scheduling
- OS code and user process mapping:
- Asymmetric multiprocessing (master-worker)
- Symmetric multiprocessing (SMP) – Win, Linux, Mac
- Common ready queue
- Per-core run queue
Scheduling criteria:
- Processor affinity
- Load balancing
Thread context switch: - Coarse-grained software thread
- Fine-grained hardware thread
Multicore Processors
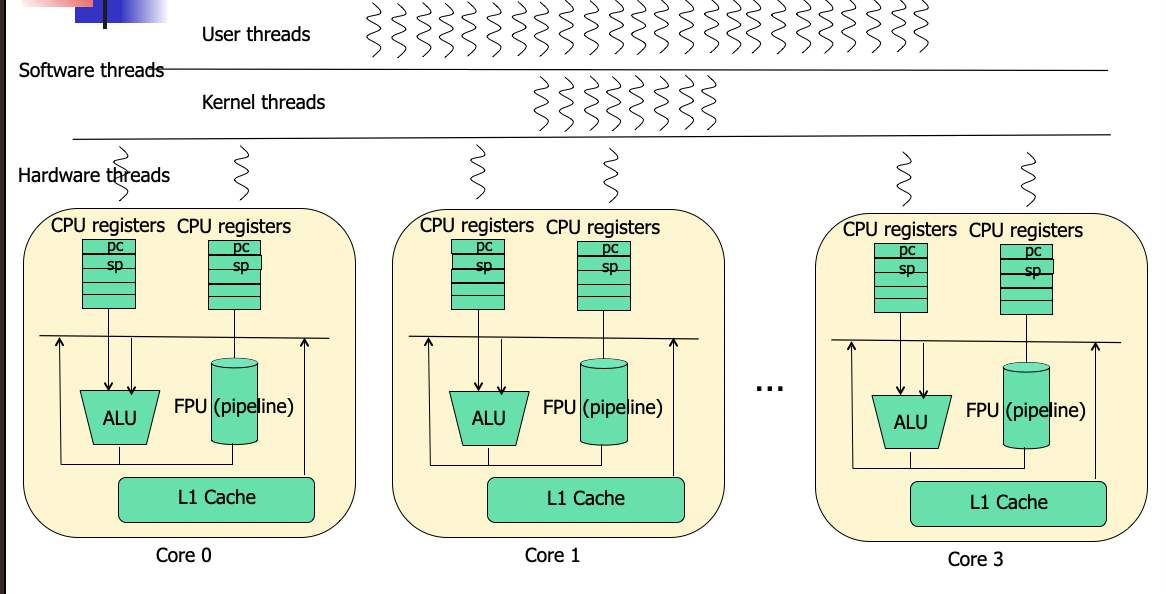
Load Balancing
- Push migration
- Threads actively search for and go to an idle CPU.
- Pull migration
- CPUs actively search for and pull busy threads into them.
Processor Affinity

Yarn
YARN is a cluster system job scheduler that supports Apache big-data computing tools: MapReduce, Spark, and Storm
Lecture 8
Revisiting bounded buffer
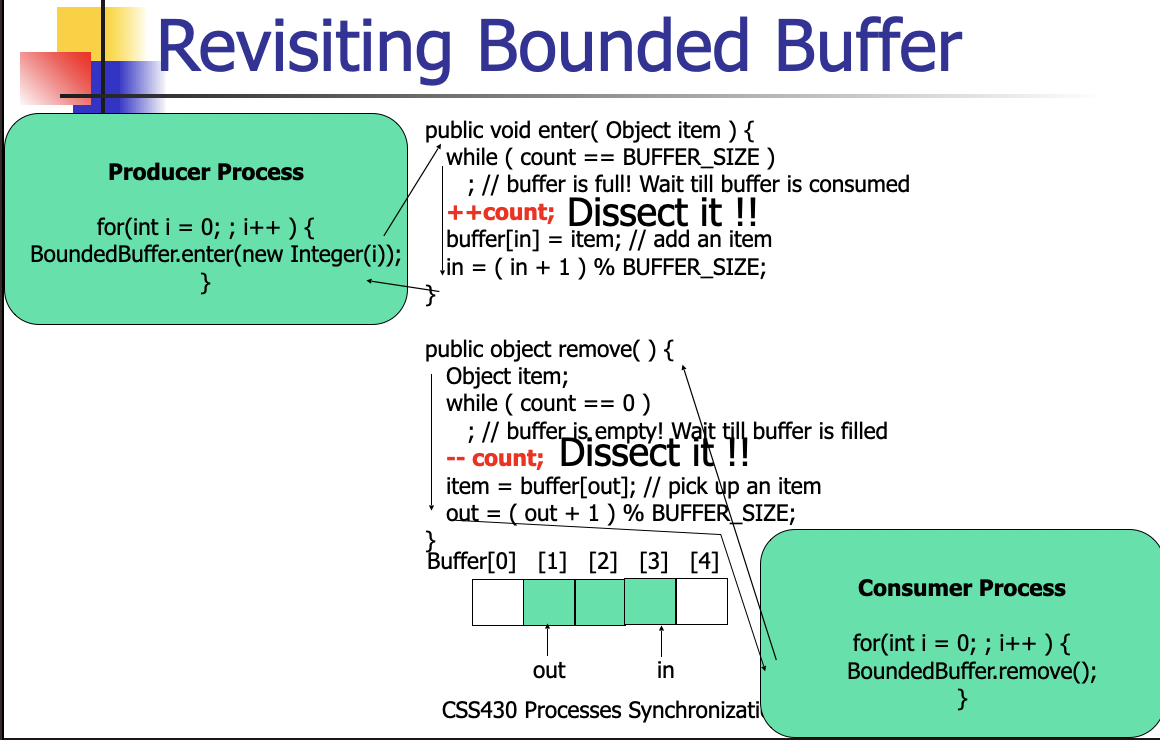
Race Condition
- The outcome of concurrent thread execution depends on the particular order in which the access takes place = race condition.

Critical Section
- Mutual Exclusion. If process Pi is executing in its critical section(CS), then no other processes can be executing in their critical sections.
- Progress. If no process is executing in its CS and there exist some processes that wish to enter their CS, then the selection of the processes that will enter the CS next cannot be postponed indefinitely.
- Bounded Waiting. A bound must exist on the number of times that other processes are allowed to enter their CS after a process has made a request to enter its CS and before that request is granted.
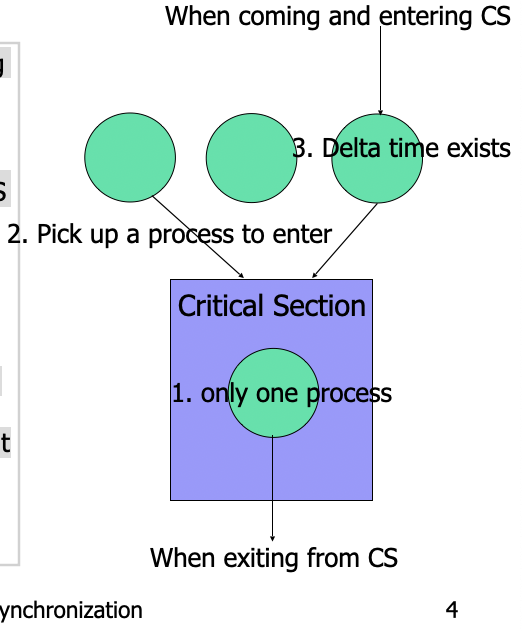
Progress <-> Deadlock
Bounded Waiting <-> starvation
Algorithm 1 (Yielding by turn)
public class Algorithm_1 extends MutualExclusion {
public Algorithm_1() {
turn = TURN_0;
}
public void enteringCriticalSection(int t) {
while (turn != t) // If it is not my turn,
Thread.yield(); // I will relinquish CPU
}
public void leavingCriticalSection(int t) {
turn = 1 - t; // If I’m thread 0, turn will be 1, otherwise 0
}
private volatile int turn; // turn placed in a register
}
Algorithm 2 (saying I’m using)
public class Algorithm_2 extends MutualExclusion {
public Algorithm_2() {
flag[0] = false;
flag[1] = false;
}
public void enteringCriticalSection(int t) {
int other = 1 - t; // If I am thread 0, the other is 1
flag[t] = true; // I declared I’ll enter CS
while (flag[other] == true) // If the other is in CS
Thread.yield(); // I’ll relinquish CPU.
}
public void leavingCriticalSection(int t) {
flag[t] = false; // I declared I’m exiting from CS
}
private volatile boolean[] flag = new boolean[2];
}
- Violate CS rule #2, #3 – progress
- Thread 0 sets flag[0].
- A context switch occurs.
- Thread 1 sets flag[1].
- Thread 1 finds out flag[0] is true, and wait for Thread 0.
- A context switch occurs.
- Thread 0 finds out flag[1] is true, and wait for Thread 1.
Algorithm 3 (Mixed of 1 and 2)
ublic class Algorithm_3 extends MutualExclusion {
public Algorithm_3( ) {
flag[0] = false;
flag[1] = false;
turn = TURN_0;
}
public void enteringCriticalSection( int t ) {
int other = 1 - t; // If I am thread 0, the other is 1
flag[t] = true; // I declared I’ll enter CS
turn = other; // Yield to another if both threads declared I’l enter CS
while ( ( flag[other] == true ) && ( turn == other ) )
Thread.yield(); // If the other declared and turn is in the other, wait!
}
public void leavingCriticalSection( int t ) { flag[t] = false; }
private volatile int turn;
private volatile boolean[] flag = new boolean[2];
}
- Comply with CS rule #2,3 – progress
- Even in case both threads declared I’ll enter CS, turn eventually points to either thread A or B!
Hardware Support
- Software solutions:
- Algorithm 3:
- It works only for a pair of threads. How about a mutual execution among three or more threads? Check Lamport’s Algorithm (See Appendix).
- Interrupt Masking:
- It disables even time interrupts, thus not allowing preemption. Malicious user program may hog CPU forever.
- Algorithm 3:
- Hardware solutions:
- Atomic (non-interruptible) set of instructions provided
- Test-and-set (or read-modify-write)
- Swap
- They are an atomic combination of memory read and write operations.
- Atomic (non-interruptible) set of instructions provided
Review of System Call, Interrupt, Exceptions
- System Calls
- Supervisor call
- software trap
- software interrupt
- Interrupts
- Peripherals
- if you want to prevent the OS from taking over, you can MASK the interrupts so you won't be bothered by hardware
- masks are privileged instructions
- Exceptions : 0 division/seg fault/Trap
Test and Set
synchronized boolean test_and_set( boolean *target ) {
boolean rv = *target; // rv means a register value
*target = true;
return rv;
}
while ( true ) {
while ( test_and_set( &lock ) )
; /* do nothing: someone else is locking, i.e., lock == true */
/* ciritical section: I set lock = true and got in the CS */
lock = false;
}
Lock
- 0 means unlocked
- 1 means locked
if test and set returns 0, it used to be unlocked, therefore you set 1
if ( *value == expected )
*value = new_value;
return temp;
}
while ( true ) {
while ( compare_and_swap( &lock, 0, 1 ) != 0 )
; /* do nothing: someone else is locking, i.e., lock == 1 */
/* ciritical section: I set lock = t1 and got in the CS */
lock = 0;
}
## Mutex Locks
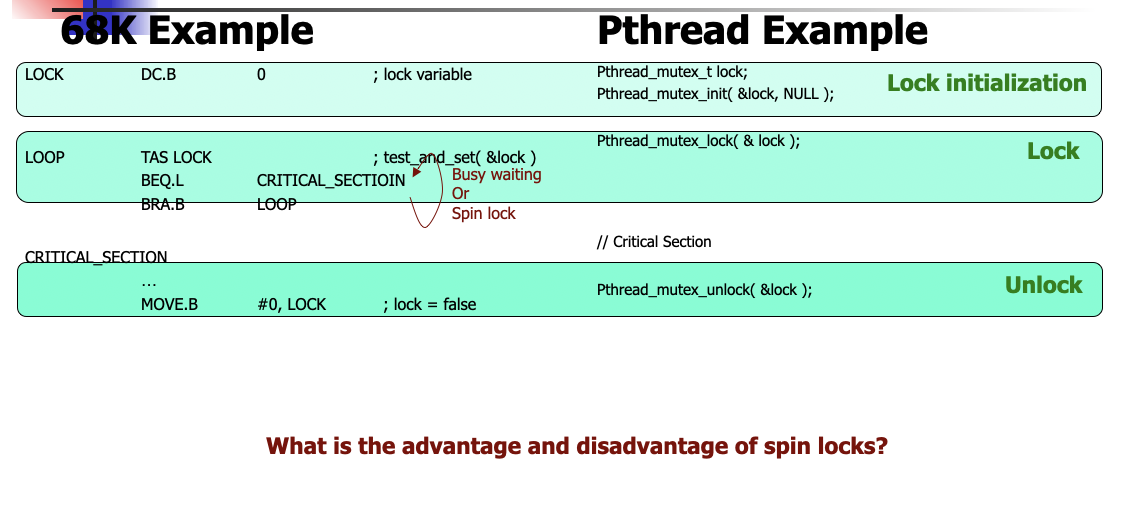
Busy waiting or spin lock...you're checking until something is ready
## Semaphores
- Synchronization tool that does not require busy waiting at a user level
- Semaphore S – integer variable
- Two standard operations modify S: wait() and signal()
- Originally called P() and V()
- Addressing the shortcoming of mutex locks
- Can only be accessed via two indivisible (atomic) operations

Difference between Test and Set And Semaphore
- Test and set
-lock = false - HARDWARE
-Semaphore
- wait/signal
-Semaphores processes will sleep and wakeup via Operating System
## Java Abstract Code with Semaphores
```java
public class Worker implements Runnable {
private Semaphore sem;
private String name;
public Worker(Semaphore sem, String name) {
this.sem = sem;
this.name = name;
}
public void run() {
while (true) {
sem.wait();
MutualExclusionUtilities.criticalSection(name);
sem.signal();
MutualExclusionUtilities.nonCriticalSection(name);
} } }
public class SemaphoreFactory {
public static void main(String args[]) {
Semaphore sem = new Semaphore(1);
Thread[] bees = new Thread[5];
for (int i = 0; i < 5; i++)
bees[i] = new Thread(
new Worker(sem,
"Worker " + (new Integer(i)).toString() ));
for (int i = 0; i < 5; i++)
bees[i].start();
} }
Pthread Semaphores
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
#include <unistd.h>
#include <iostream>
using namespace std;
sem_t semaphore;
void *worker( void* arg ) {
int id = *(int *)arg;
for ( int i = 0; i < 2; i++ ) {
sem_wait( &semaphore );
//critical section begin
cout << "thread " << id << ": entered ..." << endl;
sleep( 1 );
cout << "thread " << id << ": existing..." << endl;
sem_post( &semaphore );
} }
//critical section end
int main( ) {
sem_init( &semaphore, 0, 2 );
pthread_t t[5];
int id[5] = { 0, 1, 2, 3, 4 };
for ( int i = 0; i < 5; i++ )
pthread_create( &t[i], NULL, worker, (void *)&(id[i]) );
for ( int i = 0; i < 5; i++ )
pthread_join( t[i], NULL );
sem_destroy( &semaphore );
return 0;
}
Lecture 9 2023-01-31
Midterm Exam
Synchronization Examples
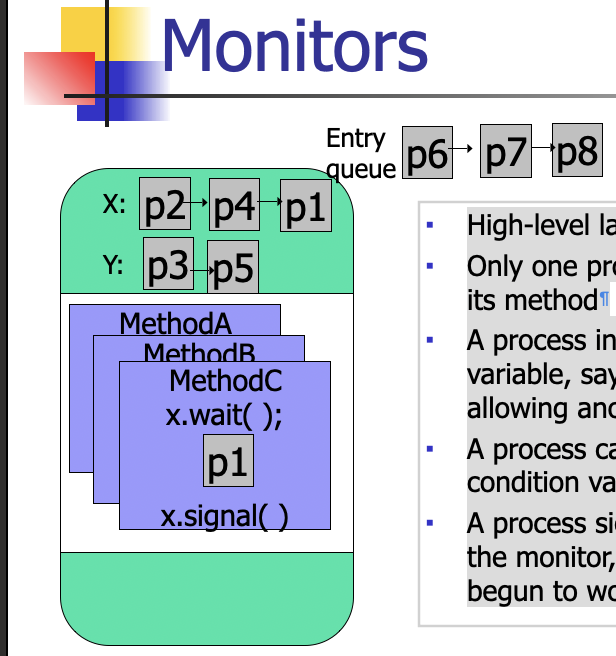
Monitors
- High-level language construct
- Only one process allowed in a monitor, thus executing its method
- A process in the monitor can wait on a condition variable, say x, thus relinquishing the monitor and allowing another process to enter
- A process can signal another process waiting on a condition variable (on x).
- A process signaling another process should exit from the monitor, because the signal process may have begun to work in the monitor.
Java Synchronization
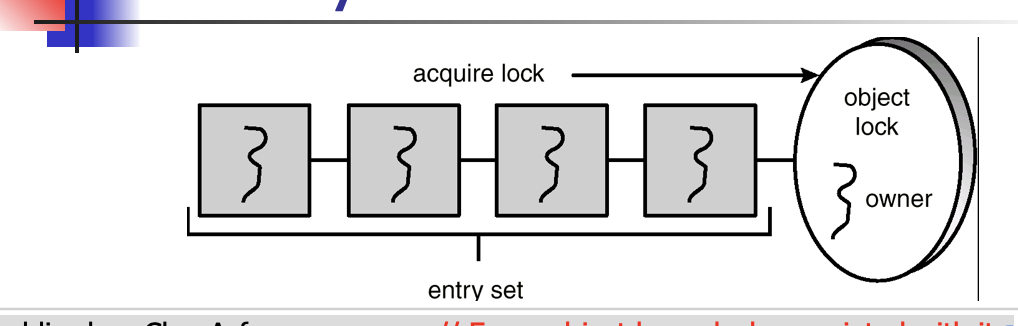
public class ClassA { // Every object has a lock associated with it.
public synchronized void method1( ) { // Calling a synchronized method requires “owning” the lock.
….;
// The lock is released when a thread exits the synchronized method.
}
public Synchronized void method2( ) { // If a calling thread does not own the lock it is placed in the entry set.
}
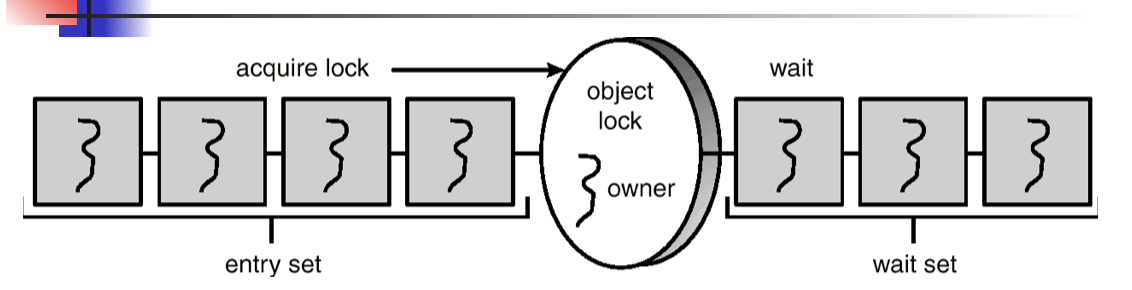
Java Monitor
public void synchronized method1( ) { // Calling a synchronized method requires “owning” the lock.
// If a calling thread does not own the lock it is placed in the entry set.
while ( condition == false )
try {
wait( ); // The thread releases a lock and places itself in the wait set.
} catch( InterruptedException e ) { }
}
….;
notify( ); // The calling thread resumes one of threads waiting in the wait set.
}
Enter and Remove with Java Synchronization
Producer
Public synchronized void insert( Object item ) {
while ( count == BUFFER_SIZE )
try {
wait( );
} catch ( InterruptedException e ) { }
}
++count;
buffer[in] = item;
in = ( in + 1 ) % BUFFER_SIZE;
notify( );
}
Consumer
Public synchronized Object remove( ) {
while ( count == 0 )
try {
wait( );
} catch ( InterruptedException e ) { }
}
--count;
item = buffer[out];
out = ( out + 1 ) % BUFFER_SIZE;
notify( );
return item;
}
Thread OS
- Each thread’s TCB maintains:
- A unique thread ID.
- It’s parent ID except Loader.java.
- SysLib.Join( )
- Puts the calling thread to sleep on the condition = this thread Tid.
- Returns the ID of a child thread that invokes SysLib.Exit( ).
- SysLib.Exit( )
- Wakes up this thread parent that has been waiting on the calling thread’s Pid.

HW3B
- Q1. To handle multiple monitor conditions in Java, (say SyncQueue.java in HW3B), how should we implement it?
-
- Q2. To prevent a thread from sleeping after notify( ) calls have been made, what features should we include in QueueNode.java?
public class SyncQueue {
private QueueNode queue[];
public SyncQueue( int condMax ) {
// initialize queue[0] ~ queue[condMAX – 1]
}
public int enqueueAndSleep( int condition ) {
// Implement the logic.
}
public void dequeueAndWakeup( int condition,
int tid ) {
// Implement the logic.
}
}
public class QueueNode {
private Vector<Integer> tidQueue;
public QueueNode( ) {
// initialize tidQueue;
}
public synchronized int sleep( ) {
// Implement the logic.
}
public synchronized void wakeup( int tid ) {
// Implement the logic.
}
}
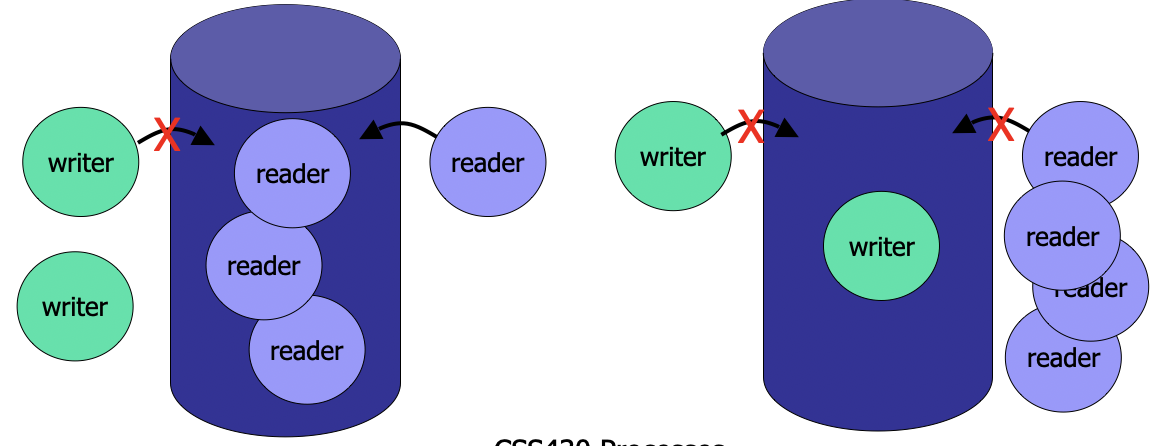
Classical Problem 2: The Readers-Writers Problem
- Multiple readers or a single writer can use DB.
Database
public class Database implements RWLock {
public Database( ) {
readerCount = 0; // # readers in database access
dbWriting = false; // a writer in database modification
}
public synchronized void acquireReadLock( ) {
/* A reader can start reading if dbWritng == false */ }
public synchronized void releaseReadLock( ) {
/* A reader exits from database, as waking up a thread */ }
public synchronized void acquireWriteLock( ) {
/* A writer can start writing if dbReading and dbWriting == false */ }
public synchronized void releaseWriteLock( ) {
/* A writer can exit from database, as waking up a thread */ }
private int readerCount;
private boolean dbWriting;
}
Readers
public synchronized void acquireReadLock( ) {
while (dbWriting == true) { // while a writer is in DB, I have to wait.
try {
wait( );
} catch (InterruptedException e) { }
}
++readerCount;
}
public synchronized void releaseReadLock( ) {
--readerCount
if (readerCount == 0) // if I’m the last reader, tell all others that DB has no more readers.
notify(); // wake up someone
}
Writers
Public synchronized void ackquireWriteLock( ) {
while (readerCount > 0 || dbWriting == true) // while reader(s) or another write is in DB
try {
wait( ); // I have to wait.
} catch ( InterruptedException e ) { }
}
dbWriting = true; // Tell all others that DB is in write.
}
public syncrhonized void releaseWriteLock( ) {
dbWriting = false; // Tell all others that DB is no more in write
notifyAll( ); // Wake up all others
}
Classical Problem 3: Dining Philosophers Problem
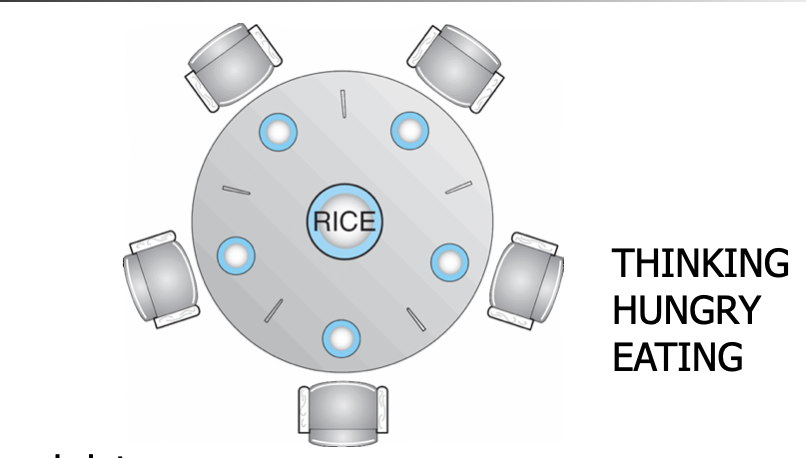
- Shared data
-Semaphore chopStick[] = new Semaphore[5];
Philosopher I
while ( true ) {
// get left chopstick
chopStick[i].P();
// get right chopstick
chopStick[(i + 1) % 5].P();
// eat for awhile
//return left chopstick
chopStick[i].V( );
// return right chopstick
chopStick[(i + 1) % 5].V( );
// think for awhile
}
Dining-Philosophers Problem Using A monitor
monitor DiningPhilosophers {
int[ ] state = new int[5];
static final int THINKING = 0;
static final int HUNGRY = 1;
static final int EATING = 2;
condition[ ] self = new condition[5];
public DiningPhilosophers {
for ( int i = 0; i < 5; i++ )
state[i] = THINKING;
}
public entry pickUp( int i ) {
state[i] = HUNGRY; // I got hungry
test( i ); // can I have my left and right chopsticks?
if (state[i] != EATING) // no, I can’t, then I should wait
self[i].wait;
}
public entry putDown( int i ) {
state[i] = THINKING; // I’m stuffed and now thinking.
// test lef and right neighbors
test( ( i+4 ) % 5 ); // if possible, wake up my left.
test( ( i+1 ) % 5 ); // if possible, wake up my right.
}
private test( int i ) {
// if phi-i’s left is not eating, phi-i is hugry, and
// phi-i’s right is not eating, then phi-i can eat!
// Wake up phi-i.
if ( ( state[( i+4 ) % 5 ] != EATING ) &&
( state[i] == HUNGRY ) &&
( state[( i+1 ) % 5] != EATING ) ) {
state[i] = EATING;
self[i].signal;
}
}
}
HW3A Dining Philosophers in C++
- Use C++ and Pthread library to complete philosophers.cpp
- pthread_mutex_init( )
- pthread_mutex_locK( )
- pthread_mutex_unlock( )
- pthread_cond_init( )
- pthread_cond_wait( )
- pthread_cond_signal( )
- Compile with
- g++ -lpthread philosopher.cpp
- Run
- Table 0 (no synchronization): ./a.out 0
- Table 1 (1 philosopher hogging the entire table): ./a.out 1
- Table 2 (2 philosophers eating simultaneously): ./a.out 2
Lecture 10 2023-02-09
Reader and writer problem can lead to starvation of writer
for final review dining philosopher with monitor and semaphore
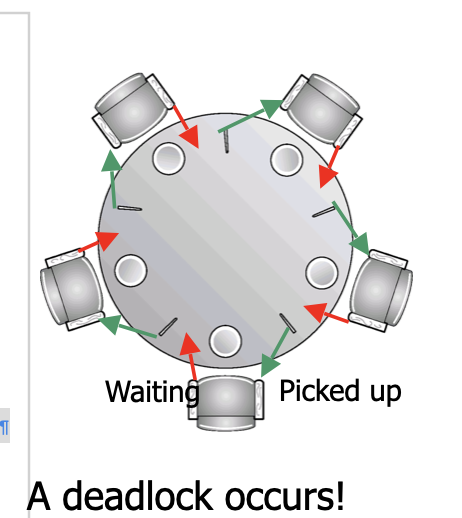
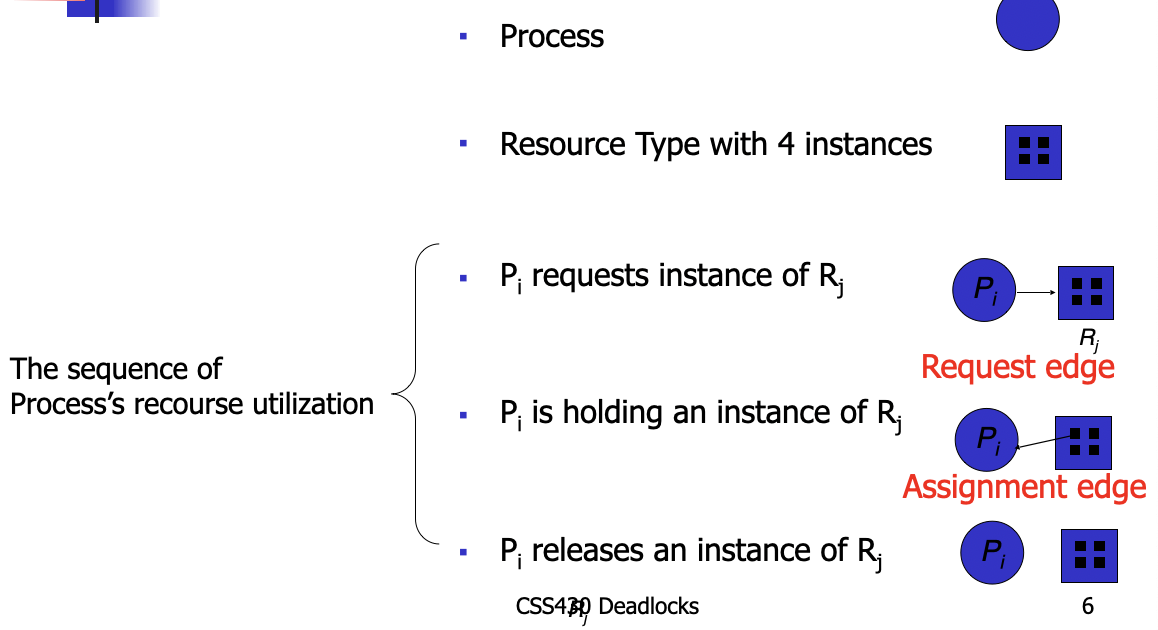
Deadlocks
Deadlock Characterizations
- Mutual Exclusion: only one process at a time can use a resource.
- Hold and Wait: a process holding resources(s) is waiting to acquire additional resources held by other processes
- No preemption: a resource can be released only voluntarily by the process holding it upon its task completion
- Circular wait
Deadlock Prevention
-Mutual exclusion: not required for sharable resources (but not work always)
- Hold and wait - must guarantee that whenever a process requests a resource, it does not hold any other resources
- require a process to request and be allocated all its resources before execution: low resource utilization
- allow process to request resources only when the process has none
- No preemption
- if a process holding some resources requests another resource that cannot be immediately allocated to it, all resources currently being held are released.
- if a process P1 requests a resource R1 that is allocated to some other process P2 waiting for additional resource R2, R1 is allocated to P1
- Circular wait: impose a total ordering of all resource types, and require that each process reuquests resources in an increaisng order of enumeration
Lecture 11 2023-02-14
Discussion
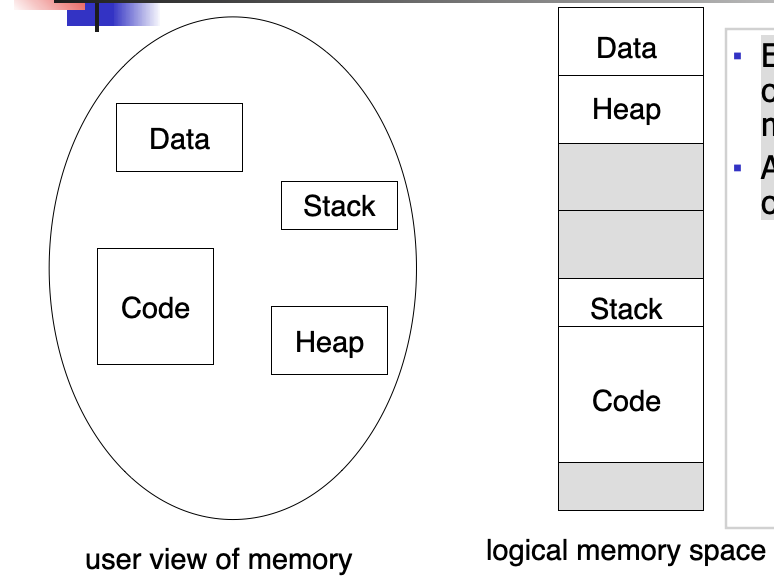
Memory Mapping
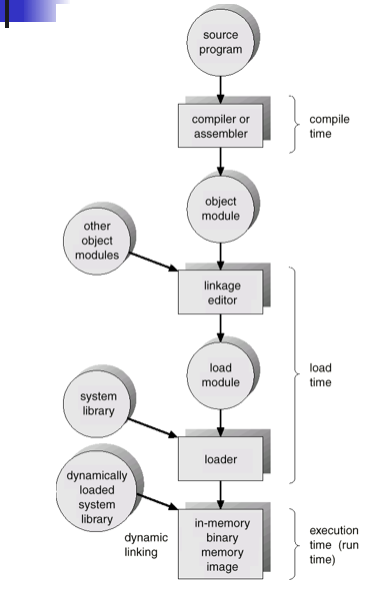
Address Binding
- Compile Time: code is fixed to an absolute address. Recompliation is necessary if the starting location changes
- Load time: code can be loaded into any portion of memory
- Run time: Code can move to any portion of memory during its execution
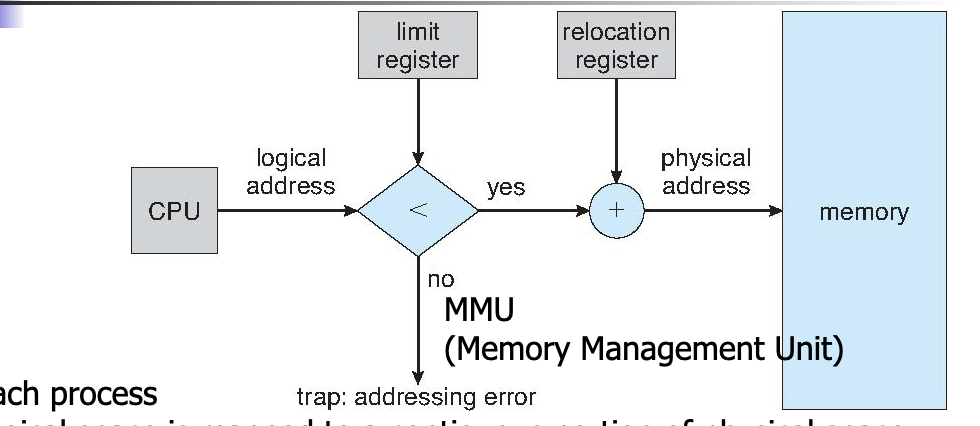
Logical Vs Physical Address Space
Physical address: the actual hardware memory address
Logical address: Each relocatable program assumes the starting location is always 0 and the memory space is much larger than actual memory
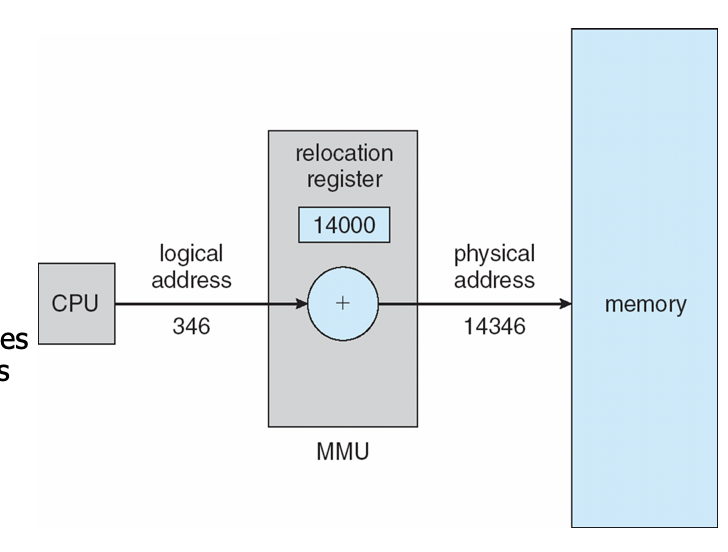
Relocation register helps map the memory and is located in MMU- memory management unit
Dynamic Loading
- Unused routine is never loaded
- useful when the code size is large
- unix execv can be categorized
- overloading a necessary program onto the current program
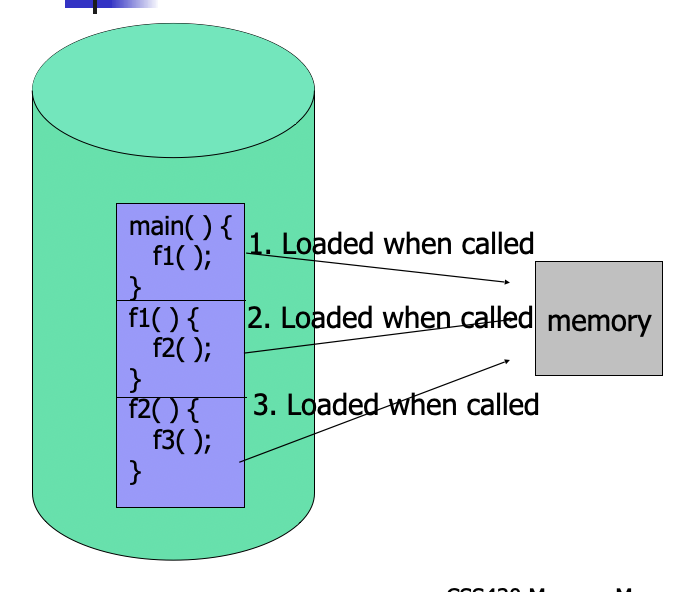
- overloading a necessary program onto the current program
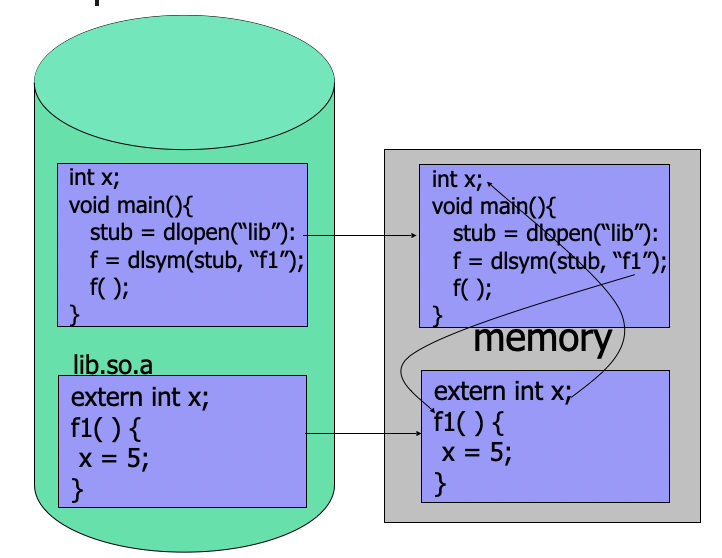
Dynamic Linking
- linking postponed until execution time
- small piece of code, stub, used to allocate the appropriate memory resident library routine
- stub replaces itself with the address of the routine and executes the routine
- operating system needs to check if routine is in processes' memory address
Swapping
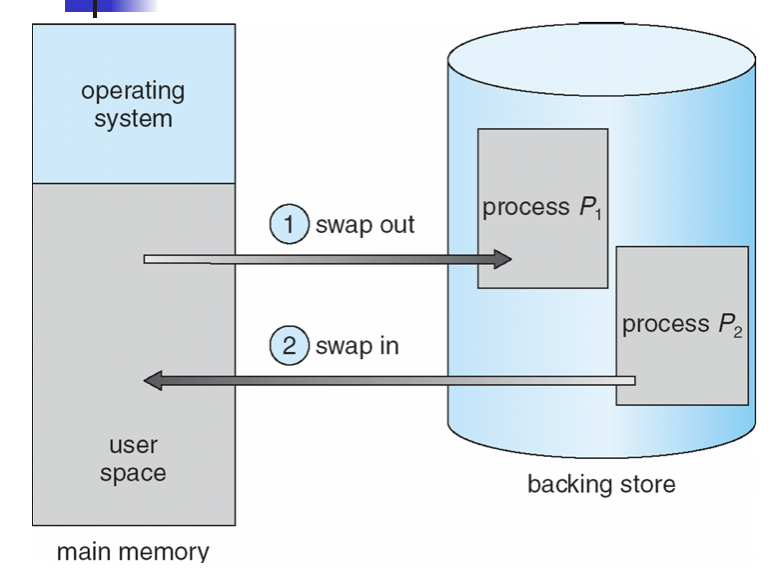
- When a process p1 is blocked so long(for I/O), it is swapped out to the backing store (swap area in Unix)
- When a process p2 is (served by I/O) and placed back in the ready queue, it is swapped in the memory
- Use the unix top command to see which processes are swapped out
Contiguous Memory Allocation
- For each process
- logical space is mapped to a contiguous portion of physical space
- a relocation and limit register are prepared
- relocation register = the starting location
- limit register = the size of logical address space
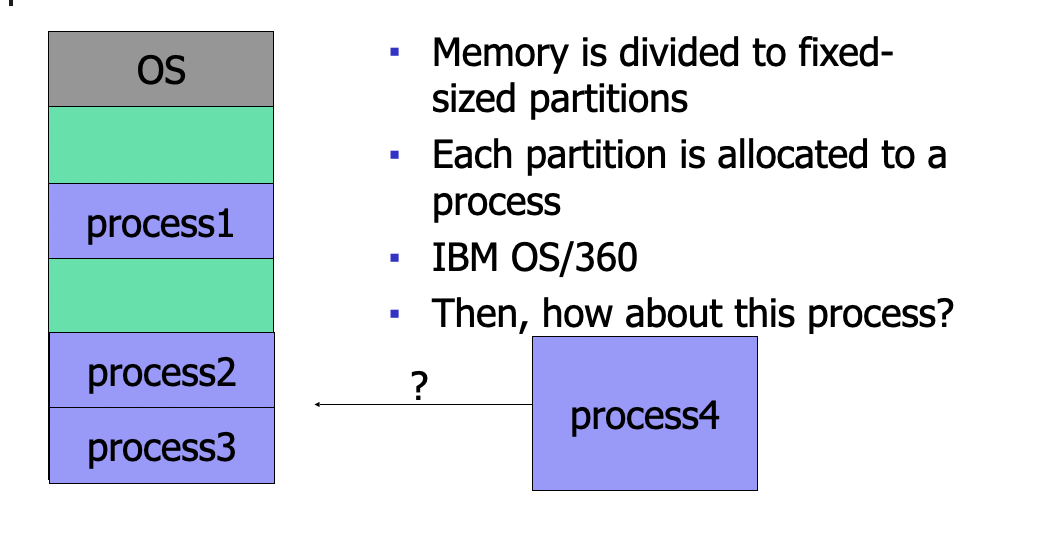
Fixed Sized Partition
Memory is divided to fixed-size partitions
each partition is allocated to a process
IBM OS/360
Variable Sized Partition
Whenever one of the running processes (p8) is terminated
- find a ready process whose size is best fit to the hole(p9)
- allocate it from the top of the hole
- If there is still an available hole, repeat the above (for p10)
- if any size of processes(up to the physical memory size can be allocated)
Dynamic Storage Allocation Problem
First Fit: allocate the first hole that is big enough (fastest search)
Best Fit: Allocate the smallest hole that is big enough; must search entire list, unless ordered by size. Produces the smallest leftover hole (best memory usage)
Worst-fit: Allocate the largest hole, must also search the entire list. Produces the largest leftover table (could be used effectively later)
First fit and best fit better than worst fit in terms of speed and storage
#Final Probably have worst fit algorithm
Lecture 12 2023-02-16
Memory management continued
Paging
- physical space is divided into 512b~8kb page frames(power of 2)
- The logical space is a correction of sparse page frames
- each process maintains a page table that maps a logical page to a physical frame
Address Translation
- A process maintains its page table
- PTBR(Page table base register) points to the table
- PTLR(Page table length register) keeps its length
- Logical address consists of:
- page number (eg 20bit)
- Page offset(eg 12bit)
- Address Translation
- if p> PTLR, error!
- frame =*(PTBR + P)
- Physical = frame << 12 |d
HW2A
main()
objA = malloc(sizeof(ClassA)) //Class A *objA = new Class A;
objB = malloc(sizeof(ClassB)) //Class B *objB = new Class B
//sbrk(size) extends heap
delete objB;
//sbrk(-size)
delete objA;
- C++ new Class/delete Obj
- C malloc() free()
- OS sbrk(+size) sbrk(-size)
Memory Management Part 2
Lecture 13 2023-02-21
Memory Management part 2
With shared pages, we just copy the page table
- Shared code
- read-only(reentrant) code shared among processes
- shared code appeared in teh same location in the physical address space
- Private code and data
- each process keeps a separate copy of the code and data (eg, stack)
- Private page can appear anywhere in the physical address space
- Copy on write
- pages my initially be shared upon a fork
- they will duplicate upon a write
Two-level page-table scheme
-
A logical address (on 32-bit machine with 4K page size) is divided into:
-
a page number consisting of 20 bits.
- a page offset consisting of 12 bits.
- If each page entry requires 4 bytes, the page table itself is 4M bytes!
-
Two-level page-table scheme
- Place another outer-page table and let it page the inner page table
- the page number is further divided into:
- a 10-bit page number.
- a 10-bit page offset.
-
Thus, a logical address is as follows:
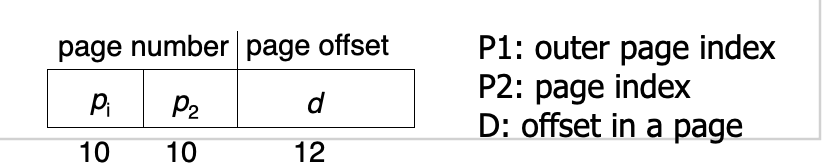
Address-Translation Scheme
- Address-translation scheme for a two-level 32-bit paging architecture
- Outer-page table size: 4K
- Inner page table size: 4K
- If a process needs only 1K pages (=1K * 4KB = 4MB memory), outer/inter page tables require only 8K.
Segmentation
- Each page is only a piece of memory but has no meaning.
- A program is a collection of segments such as:
- main program,
- procedure,
- function,
- global variables,
- common block,
- stack,
- symbol table
Segment Protection and Sharing
- Segment protection can be achieved by implementing various flags in each segment table entry:
- Read only
- Read/Write
- Unlike a page, a segment has an entire code.
- Thus, sharing code is achieved by having each process’ code segment mapped to the same physical space.
when sharing, the page table is replaced with a segment table, which is a contiguous block which may result in external fragmentation
Segmentation with Paging
- Segmentation
- Is very resemble to a contiguous memory allocation
- Causes External fragmentation
- Introducing the idea of paging
- Assuming
- The segment size is 4G bytes, and thus the segment offset is 32 bits
- a page is 4K bytes, and thus the page offset requires 12 bits.
- Logical address = <segment#(13bits), segment_offset(32 bits)>
- If segment# > STLR, cause a trap.
- If offset > [STBR + segment#]’s limit, cause a segmentation fault.
- Liner address = <[STBR + segment#]’s base | segment_offset>
- Decompose liner address into <p1(10 bits), p2(10 bits), page_offset(12 bits)>
- The first 10 bits are used in the outer page table to page the inner page table
- The second 10 bits are used in the inner page table to page the final page
- Physical address = <[PTBR + p2]’s frame# << 12 | page_offset>
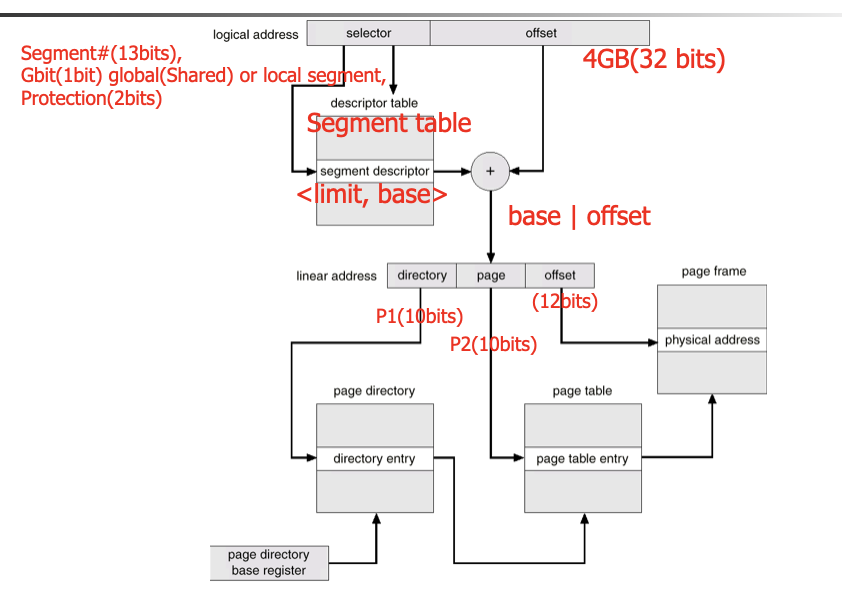
- Assuming
Logical / page size = page#
logical % page size = offset
Virtual Memory
Page replacement algorithm
Lecture 14 2023-02-23
- Page fault overheads:
- An OS trap, a process state saving, a disk I/O request, a context s/w to another process, a disk interrupt, a process state saving, disk reads, and a context s/w to the original process
- Effective access time (EAT)
- = (1 – p) x ma + p x page fault time
- Where 0 ≤ p 1 ≤ is the page fault probability
- Ma = 200 nsec
- Page fault time = 8 msec = 8,000,000 nsec
- EAT = (1 – p) x 200 + 8000000p = 7,999,8000p + 200
- Proportional to p
- Eg. how about 10% slower than Ma?
- 220 > 79998000p + 200
- P < 0.0000025 (=0.00025%)
Page Replacement
Too many page faults -> thrashing
Page Replacement mechanism

Page Replacement Algorithms
- Want lowest page-fault rate.
- Evaluate algorithm by running it on a particular string of memory references (reference string) and computing the number of page faults on that string.
- In all our examples, the reference string is 7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7.
- Algorithms
- FIFO (The oldest page may be no longer used.)
- OPT (All page references are known a priori.)
- LRU (The least recently used page may be no longer used.)
- Second Chance (A simplest form of LRU)
The first call is always a page fault
Lecture 14 2023-02-28
VM-2
Discussion
HW 4B
File-System interface?
Second Chance Algorithm
- Reference bit
- Each page has a reference bit, initially = 0
- When page is referenced, bit set to 1.
- Algorithm
- All pages are maintained in a circular list.
- If page to be replaced,
- If the next victim pointer points to a page whose reference bit = 0
a. Replace it with a new brought-in page - Otherwise, (i.e.,if the reference bit = 1), reset the bit to 0.
- Advance the next victim pointer.
- Go to 1.
Page Allocation Algorithm
-
frames = m, # processes = n
- Equal allocation
- m/n frames are allocated to each process.
- Proportional allocation
- (Pi’s vm size / Σpi’s vm size) * m frame are allocated to each process.
- This allocation is achieved regardless of process priority
- Priority allocation
- A process with a higher priority receives more frames.
- Global versus local allocation
- Global: can steal frames from another process.
- Local: must find out a victim page among pages allocated to this process.
Thrashing
- If a process does not have “enough” pages, the page-fault rate goes very high. This leads to:
- low CPU utilization.
- operating system thinks that it needs to increase the degree of multiprogramming.
- another process added to the system.
- The new process requesting pages
- Thrashing increased
Prevent Thrashing
- Local (or priority) replacement algorithm
- Effect: A thrashing process cannot steal frames from another process and thus trashing will not be disseminated.
- Problem: Thrashing processes causes frequent page faults and thus degrade the average service time.
- Locality model
- Process migrates from one locality to another.
- When Σ size of locality > total memory size, a thrashing occurs.
- Suspend some processes
- #final second chance
Lecture 15 2023-03-02
File Concept:
fd = open('filename', r)
read(fd, buf1, 512) -> operating system read 512
read(fd, buf2, 1024) -> operating system read 1024
read(fd, buf3, 512) -> operating system read 256
read(fd,buf3,256) -> returns 0 which indicates end of file
close(fd)
There can still be internal fragmentation in file systems
In 4b we use syslib.rawread() and syslib.create() however, in the final project, we will use syslib.read()
File Concept
- Nonvolatile storage unit
- Logically contiguous space
- Attributes
- Name, Type, Size, Protection, Time, Date, and User ID
- Location
- Directory from a user’s point of view
- Disk location from the OS view point
- File format
- A sequence of bits from the OS view point
- Meaningful information from each application view point
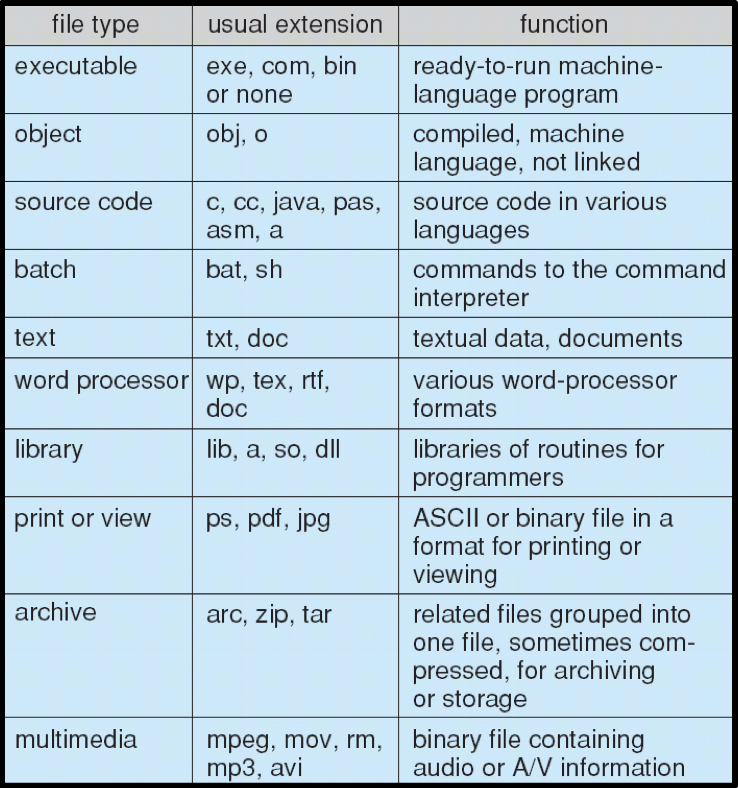
- Types identified by a file suffix
File Attributes
- Name – used for a user to reference a file.
- Type – needed for an application to identify if it is reading correct file information.
- Location – Directory path (and disk location).
- Size – current file size.
- Protection – controls who can do reading, writing, executing.
- Time, date, and user identification – data for protection, security, and usage monitoring.
File Types
File Operations
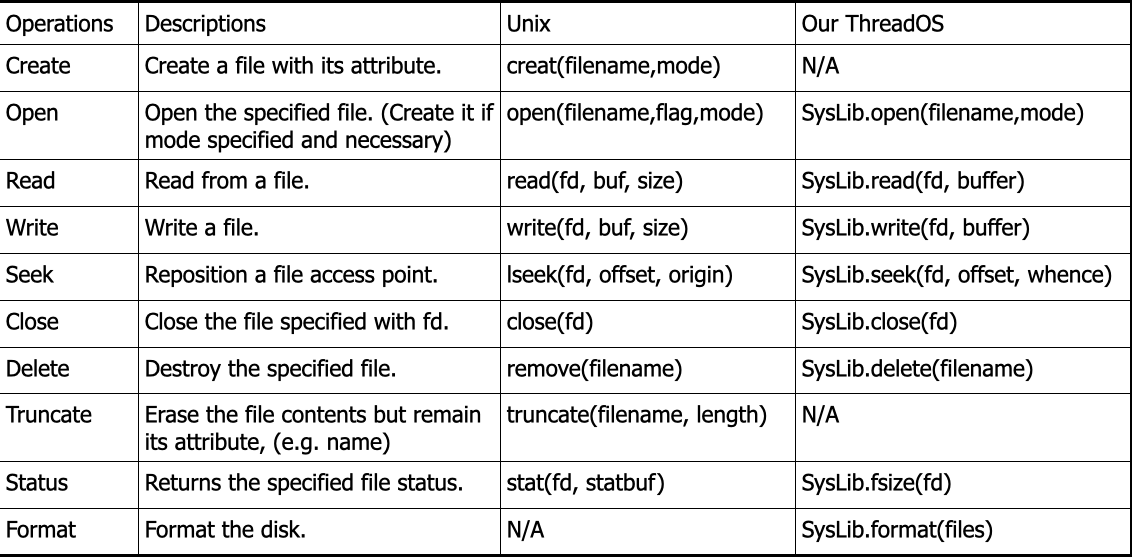
close() is necessary to free up file pointer
Seek

After seek(), you have to use read(). Seek moves the file pointer
eg seek(fd,-4,2) followed by read(fd,buf,4)
Operations Performed on Directory
- Search for a file
- find dirName –n fileName –print
- whereis or where filename
- Create a file
- Manual: Create a file by text editors
- Command: touch fileName … create a 0-length file
- System call: open(filename,O_CREAT,mode)
- Delete a file
- rm [-fr] fileName
- List a directory
- ls [-al]
- Rename a file
- Command: mv oldName newName
- System call: rename( oldname, newname)
- Traverse the file system
- find / -n -print
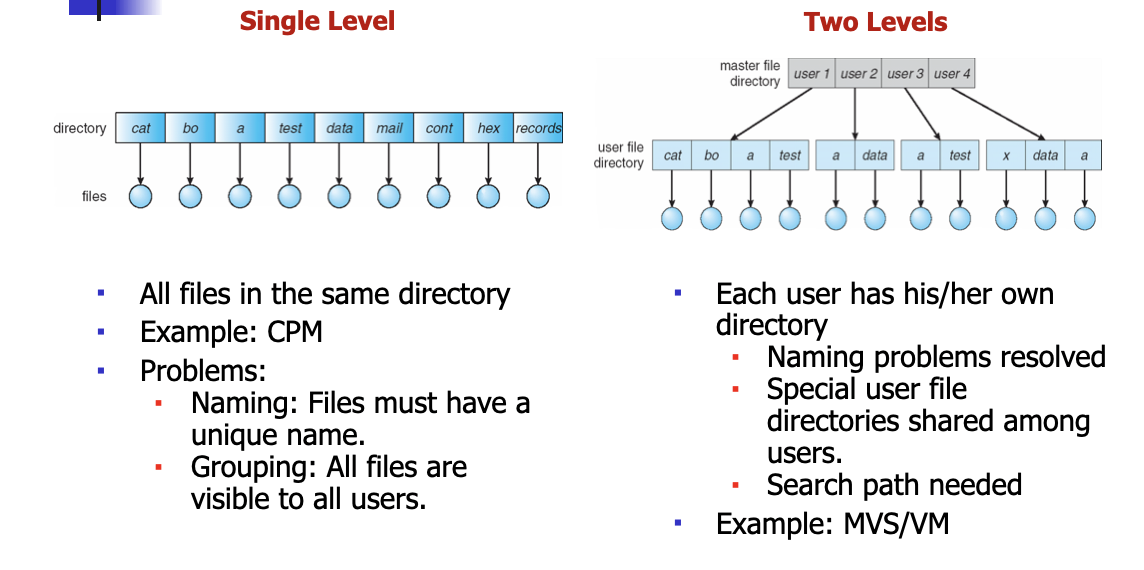
Single/Two-Level Directory
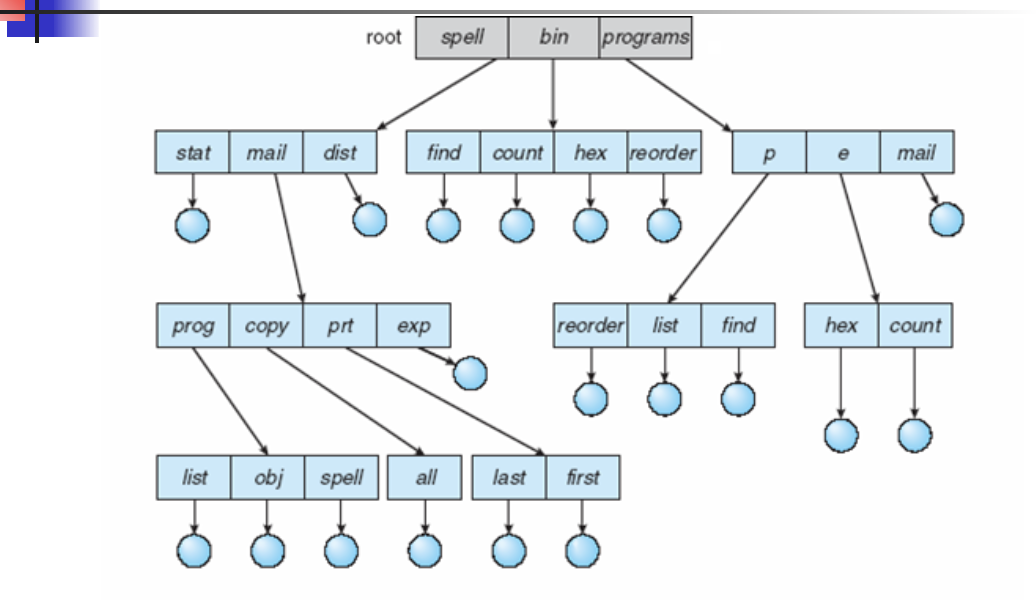
Tree Structured Directories
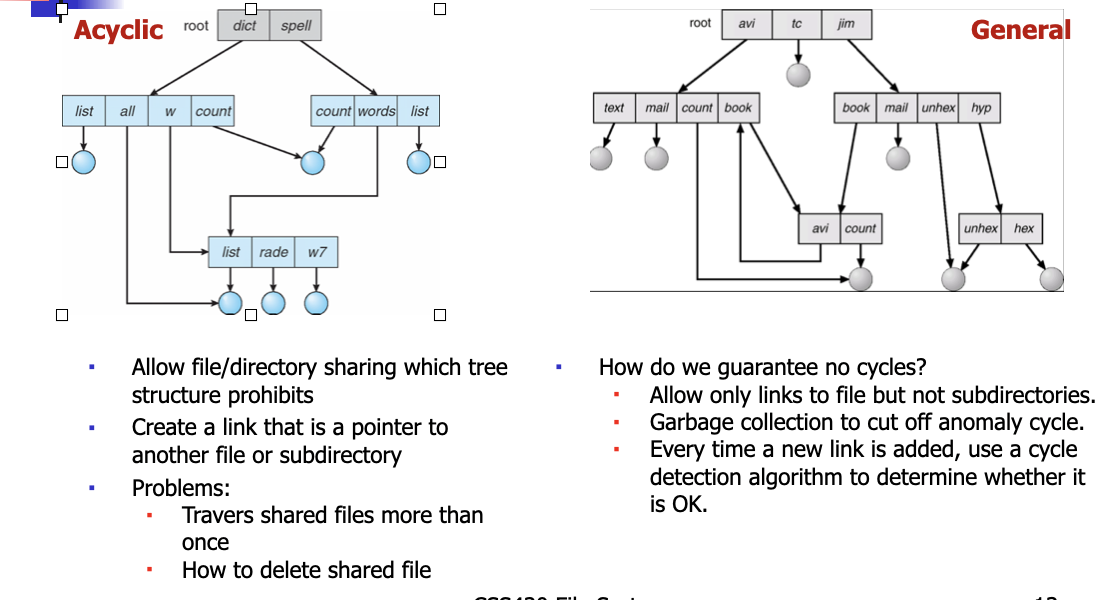
Acyclic-Graph/General Directory
File System Implementation
- Boot control block contains info needed by system to boot OS from that volume
- Volume control block contains volume details (= super block in Unix)
- Directory structure organizes the files file (= a file in Unix)
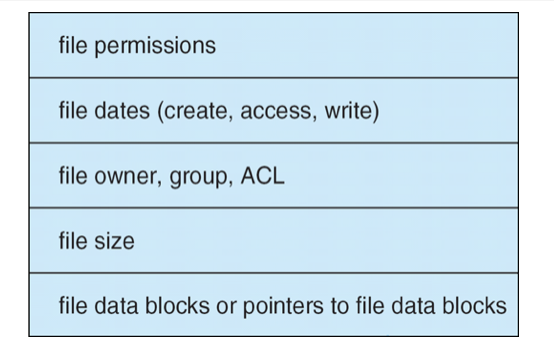
- Per-file File Control Block (FCB) contains many details about the file (= inode in Unix)
In-Memory File System Structures
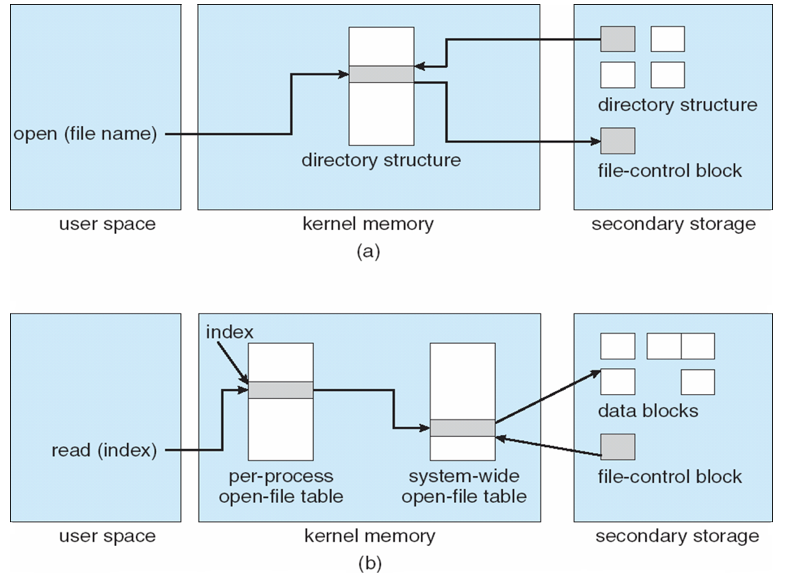
- How should file system allocate disk blocks to each stream-oriented file?
- Contiguous Allocation
- Linked Allocation
- File allocation table
- Indexed Allocation
- Linked scheme
- Multilevel index
- Combined scheme (Unix)
Lecture 16 2023-03-07
File Locking
ln - s = symbolic link src object
!where are file hardlinks stored?.excalidraw
File system implementation
Each entry in the inode direct block is 512 bytes
cut and paste to filetable.java
inode.java is done
implement filesystem.java and kernel.java
FINAL REVIEW 2023-03-09
- Final Project Discussion
- Break
- Rehearsal
Exam - Open Book
Test 5 should share uwb0
with open, first argument (0) is file name, and 1 is mode
first 4 bytes of super block shows total blocks
second 4 bytes shows total Inodes
first free block is the third integer
Each Inode
1 int = 4b
+3 shorts
+11shorts
14 shorts = 28bytes
therefore each inode = 32 bytes
512b/32b = 16 inodes
freelist is similar to a stack implementation (format)
superblock methods to implement
sync()
getFreeBlock
returnBlock
write means you will overwrite everything
superblock
returnblock()
Directory contains two arrays, 1, fsize and fname
The inedex corresponds to directory number
so 0 corresponds to / Fsize of 0 should be 1
File Structure Table
falloc
FIleTable.java
falloc()
- read database
ffree() - exit db
fempty() - returns if table empty
constructor(dir_referenece) - table = new vector
- dir = dir_reference
Directory.java
ialloc()
- allocate given file name(finds empty entry in name) returns index in fsize array
ifree()
Constructor()
namei()
File table needs synchronized