Hash Tables
Notes
This data structure is used frequently in day to day programming ie very common
A Hash table takes a key-value pair and stores it, and when given a key, it quickly returns the pair.
Key Functions
- insert
- delete
- look up
Eg: key - person: pair - address
Kevin - 335456
John - 123445
Now, given a name, return a number quickly.
Normally, if we would use an array, this would be a slow operation
The lookup time for a hash table look up function is very close to constant time
This can be mapped to an entire object, not just a single value
To achieve this constant time look up works we need to dive a little deep.
Open Hashing - Separate Chaining
Hashing - have an array with keys. Create a function which maps keys to array elements. Hash
A hash function will take a key and return an index to the location in memory where the key is stored.
For a good hash function, we want items well distributed in the hash table
a simple hash function would be say, using the modulo operator by 10...
so hash(32) would return an index of 2. Like wise, hash(97) would give us an index 7...but so would hash(177) , and hash(37) so we can chan this to the 7
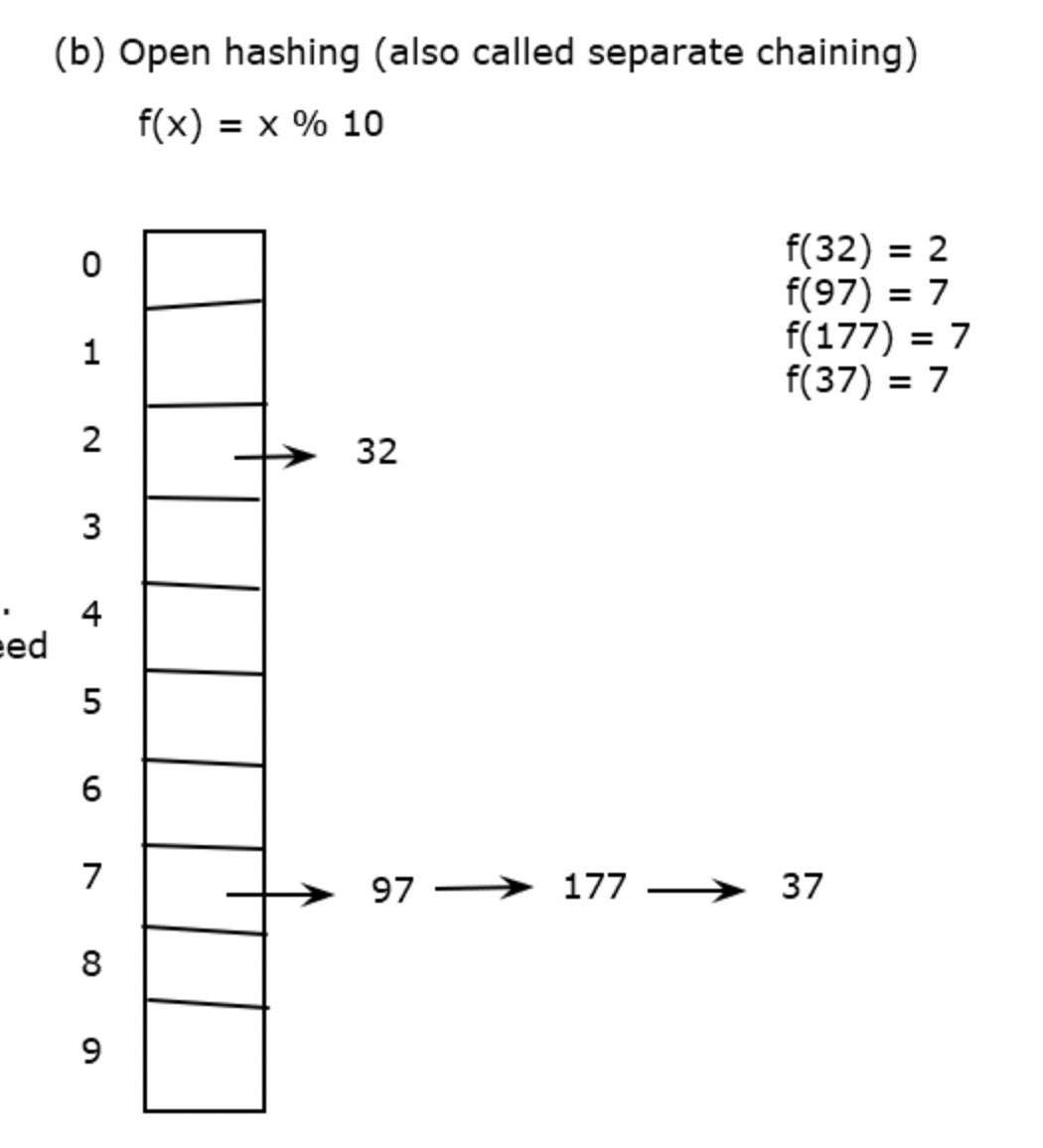
In reality though, our hash table should be much much larger(generally twice the size of what we think we'd need)
Array size should also be a prime number so data is more evenly spread (since you always mod by the size), this way, handling collisions don't lead to problems.
So now, to look up the key for 37. We look up the hash value for 37, then do a linear search for the key we're looking for.
Hash collisions cause the lookup to not be in constant time
Closed Hashing / Open addressing
Linear Probing
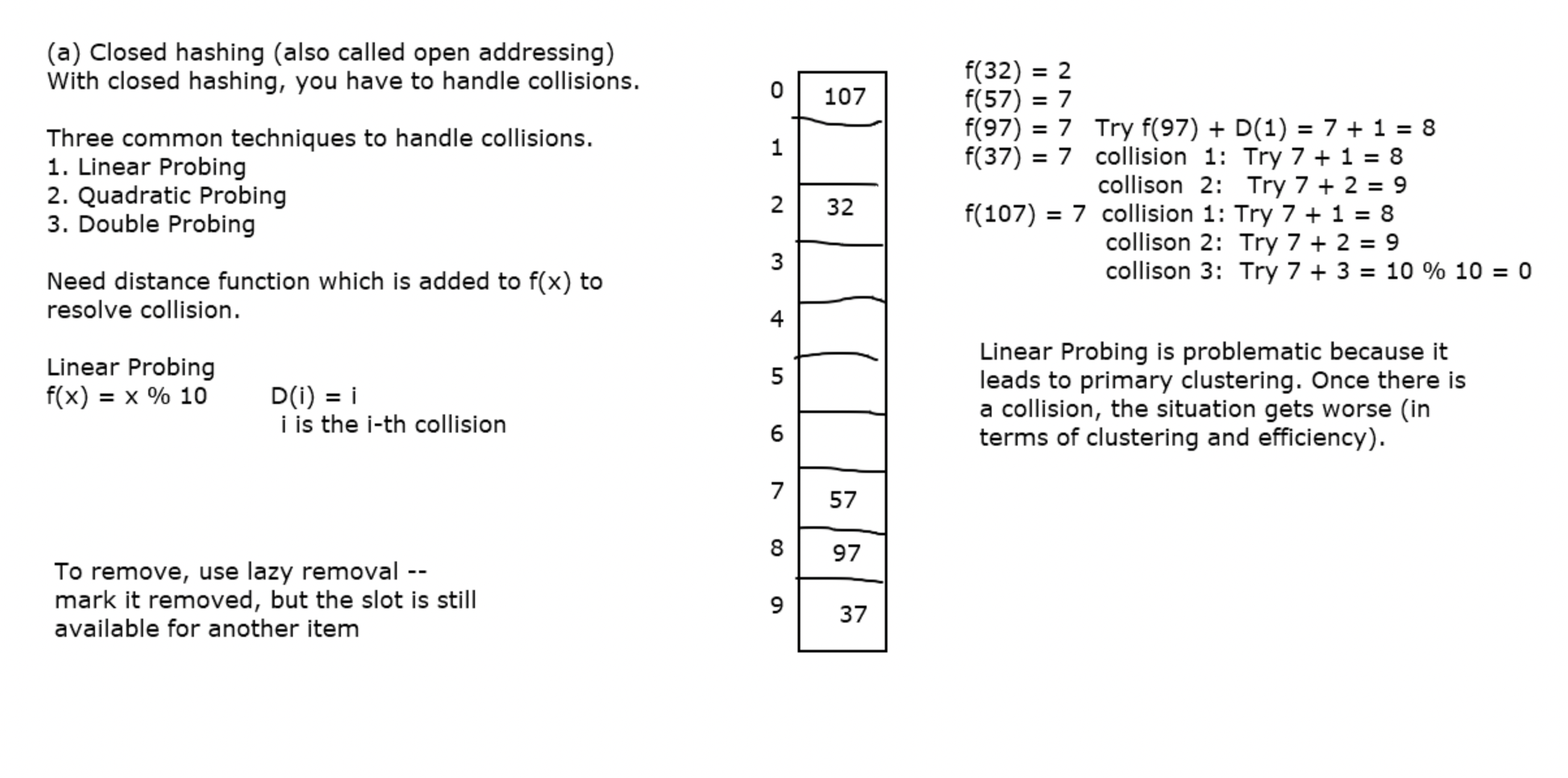
When we insert 32, we do a mod by 10 and place 32 in index 2
With linear probing, if we have a collision, we look for the next empty slot and place it there.
This leads to primary clustering when there is a collision the situation gets worse.
Quadratic Probing
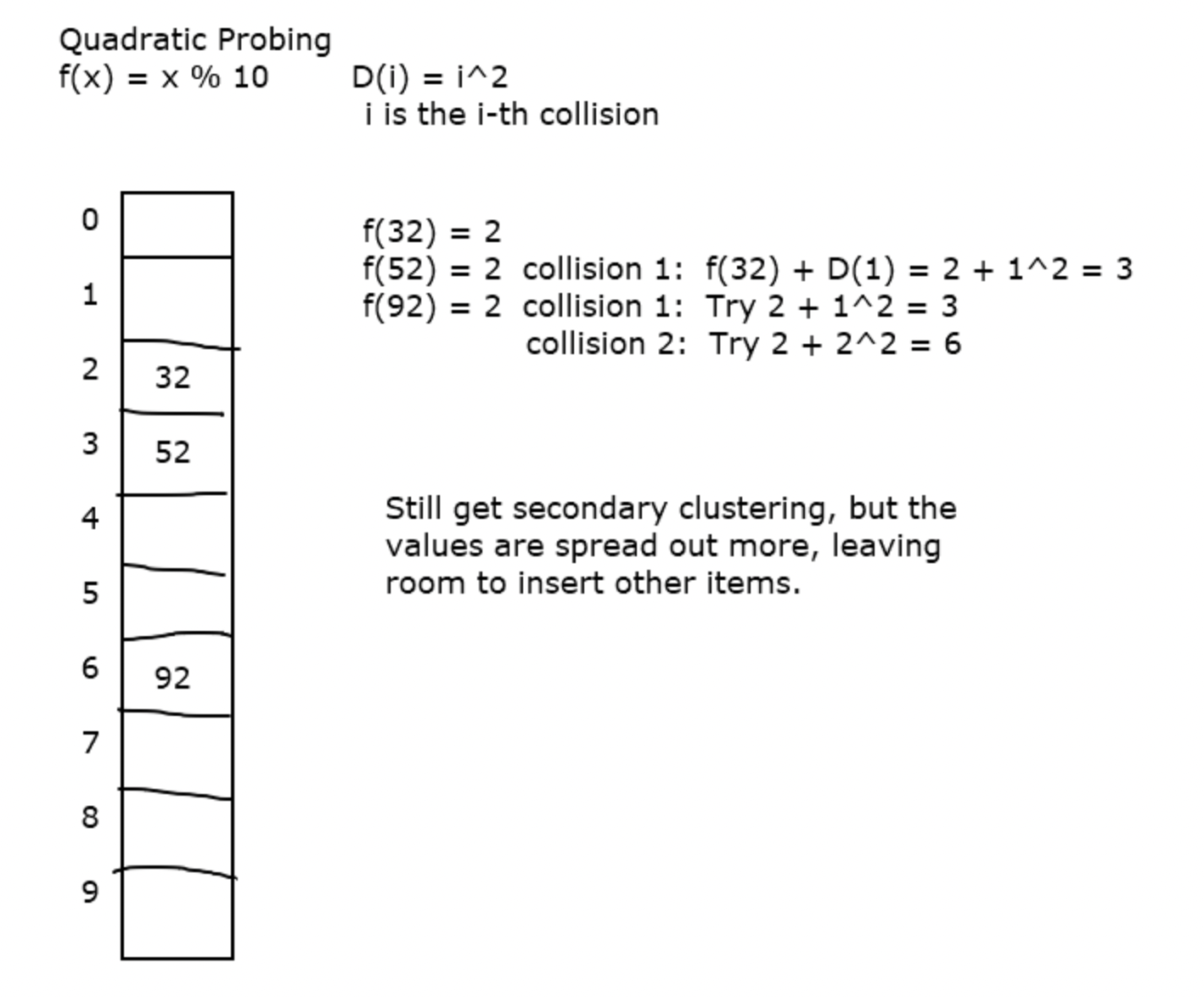
With quadratic probing, we initially try the index, if that is taken we do the index plus i^2, if that is taken, we increment i where i is the i'th collision. This spreads out the clustering.
Double Hashing

In double hashing we use two hash functions
example
h1(x) = x % 10
h2(x) = 7 - (x % 7)
h1(89) = 9
h1(18) = 8
h1(49) = 9, h2(49) = 7- (49 % 7) = 7
-> try h1(49) + 1 * h2(49) = 9 +1 * 7 = 16 (% 10 ) then we run through h1 again h1(16) = 6
Load Factor
The load of your current hash table ...ie what percentage of your allocated memory is occupied...so if you have a hash map of 10, and you have 6 items stored, then your load factor is 6/10 or
In closed hashing, your load factor will always be
However, in open hashing, there is no limit for how many items you can change, so your size may be far greater than one.
Our goal is to always have a small load factor as it reduces the likelihood of collisions
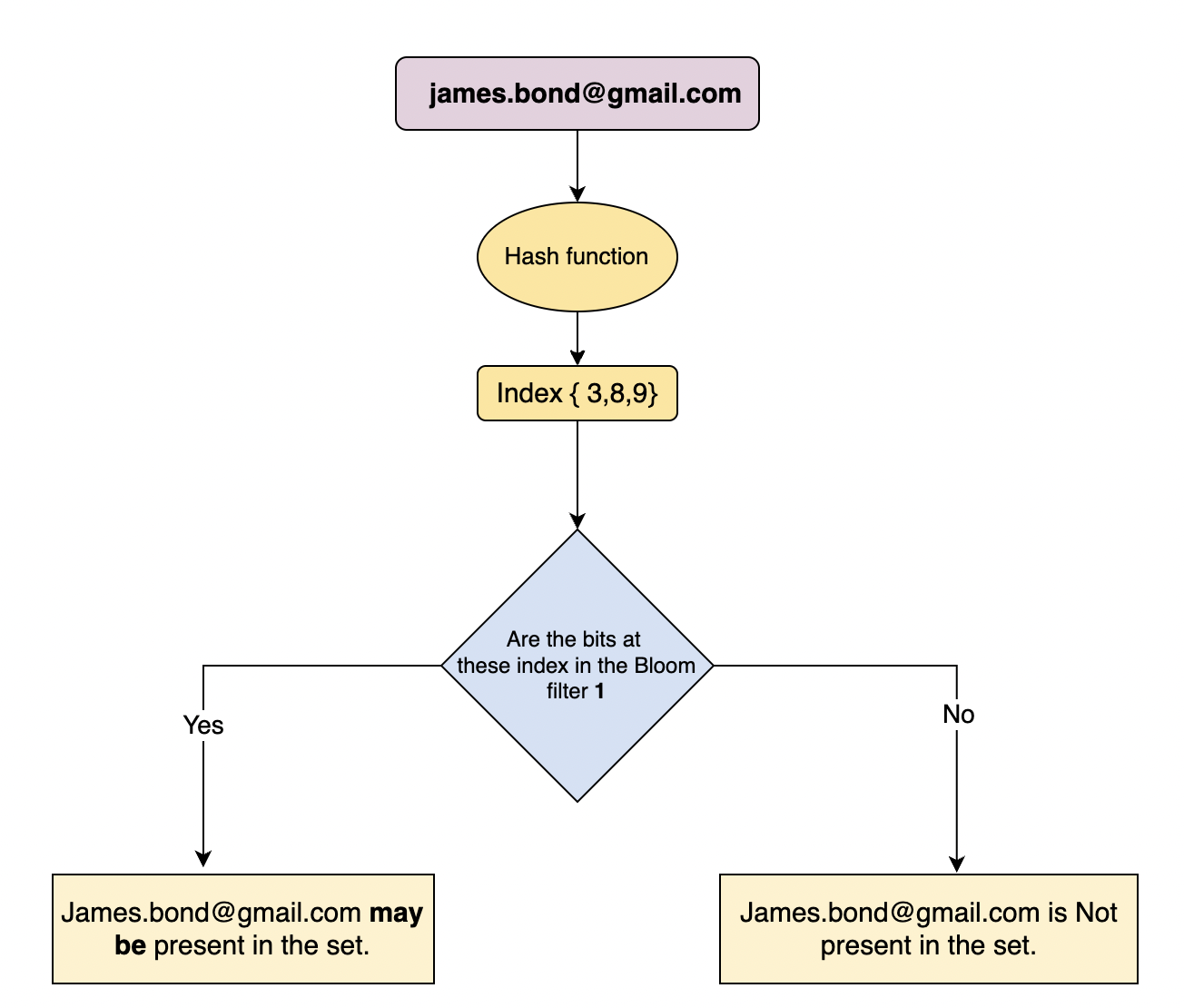
Bloom Filter
A bloom filter is a bit vector that is instantiated to all bits set to 0. When we add something to a bloom filter, we apply it through multiple hash functions. Each hash function will produce a different result, then we will sit the index = to 1.
Once the bit is set, it will always remain set, it can never reset back to zero.
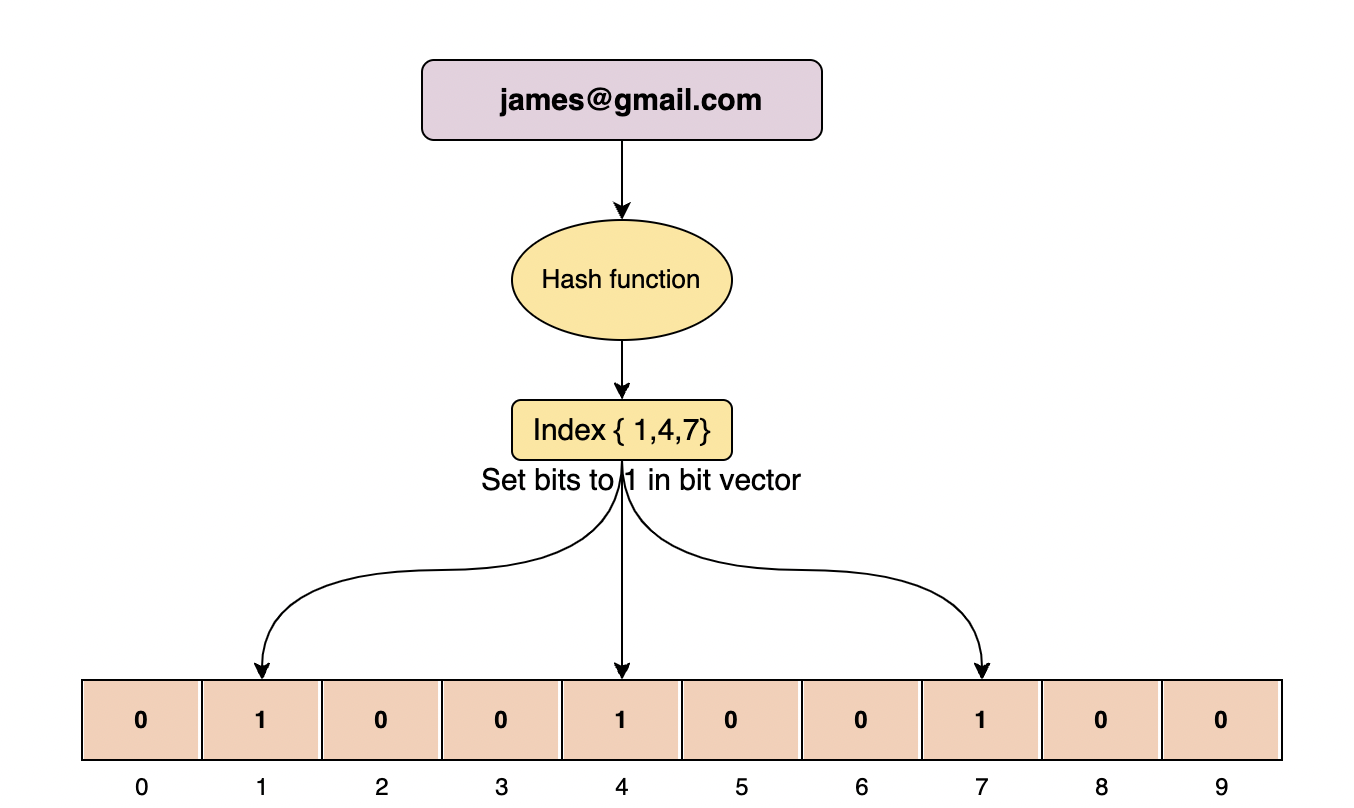
Bloom filters are used for testing whether a key has been previously inserted into a table or not.
It can tell very quickly if an item does not exist , or if it may exist
As long as one of the bits is not set to one, you can be certain that a key does not exist
Questions
It depends on the set of data, there is no universally fit hash function
Snippets
Terms
Resources
Related Notes
Binary Search Trees
Dijkstra's Algorithm
Data Structures Prep